 Facebook
Facebook  Twitter
Twitter  Reddit
Reddit  LinkedIn
LinkedIn  Email
Email  Copy URL
Copy URL Four research papers by NC Research, NCSOFT's AI R&D organization, have been accepted to ICASSP(International Conference on Acoustics, Speech, and Signal Processing) 2024, which is the world's largest and most comprehensive technical conference focused on signal processing and its applications. NC Research has been publishing the results of various research work based on AI core technologies in the industrial and academic fields. For ICASSP 2024, NC published two papers on Vision AI: ▲Relieving the Hallucination of Multimodal Language Models and ▲Improving Face Recognition, and two papers on Speech AI: ▲User-Defined Keyword Spotting Model and ▲Text-to-Speech for Virtual Speaker. Find out more about the research through this article.

Relieving the Visual Hallucinations of Multimodal Language Models
Title: "Visually Dehallucinative Instruction Generation"
Multimodal AI Lab - Sungguk Cha, Jusung Lee, Younghyun Lee, Cheoljong Yang
Read more about the research here.
There have been an increasing number of multimodal models that comprehend and create multimodal data such as text, images, video, and sound. Multimodal models are more complex than existing language models, processing various tasks and conducting in-depth interactions with users. The more modalities a language model possesses, the more data it learns. Therefore, AI hallucinations occur in greater numbers as a language model develops into a multimodal model. Among AI hallucinations, an example of visual hallucinations is when the user provides an image without a vehicle to an AI model and asks, "Where is the car?"and being given an answer as if there is a vehicle in the image.
This research presents CAP2QA, the instruction tuning technique that creates instruction texts in the form of questions and answers based on image captions, to alleviate these visual hallucinations. CAP2QA ensures the credibility and image-alignness of the generated question and answer instructions due to its use of verified image captions. In addition, NC used CAP2QA to create and distribute a visual instruction dataset designed to be limited to image content, named CAP2QA-COCO. It is an instruction that converts the COCO-caption dataset, a large-scale multimodal dataset, into the form of questions and answers in order to reduce visual hallucinations by having the model only answer using the facts that can be derived from the provided image.
Experiments proved that CAP2QA was effective in reducing visual hallucinations and improving the visual recognition abilities and expressive abilities of the model. Furthermore, through VQA (Visual Question Answering) comparison with another model that was trained with unaligned image-to-text data, CAP2QA achieved remarkably lower hallucination rates and higher recognition performance.

VQA Experimental Results of Existing Model vs. Proposed Model
This study proposed a new method for generating visual instructions and was able to prove that this method reduced visual hallucinations and improved the expressiveness of the multimodal language model through experimentation. This implies that high-quality multimodal data is more constructive in generating better results than purely size-based data. These study results are expected to contribute to improving the credibility and practicality of multimodal language models that can be applied to various services.
Accurate Face Recognition Even in Adverse Environments
Title: "Robust Face Recognition Based on an Angle-aware Loss and Masked Autoencoder Pre-training"
Multimodal AI Lab - Jaehyeop Choi, Youngbaek Kim, Younghyun Lee
Read more about the research here.
Face recognition is a technology that allows the recognition of people based on their faces. Face recognition plays an important role in various modern application fields. Despite the advances in deep-learning technology, accurate identification using face recognition in poor conditions such as changes in face angles, bad lighting, and occlusions remains a challenge.
In this paper, NC proposes a learning method to help feature extraction models perform accurate face recognition even in poor conditions. First, the team aimed to improve the performance of face recognition in various angles by implementing an angle-aware loss function that provides a large margin for significantly rotated faces. Additionally, the paper introduces a method of pre-training a masked autoencoder (MAE) to set the initial weight of the model in order to deal with lighting changes and obstructions and enhance the recognition ability of the model.
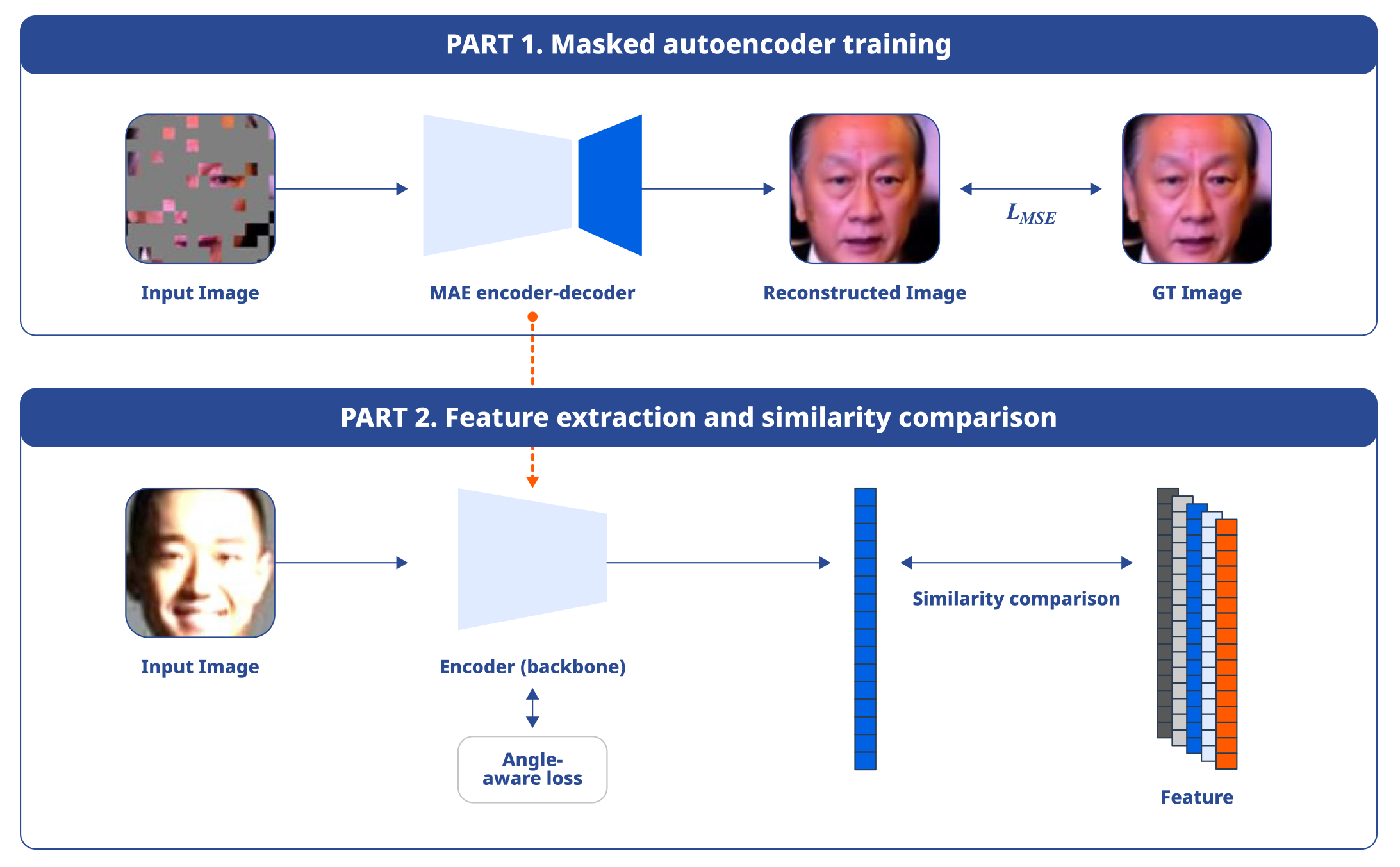
Proposed Model Structure
The results of the experiment confirmed superior face recognition performance compared to existing methods in both ordinary and compromised surroundings.
This research proves its worth by introducing the optimum method to provide stable face recognition even in poor conditions. It can be expected to be utilized in various services that require the face recognition of gamers, such as video games that require the users' faces to be exposed on camera. NC Research plans to continue contributing to face recognition technology and introduce new ways to utilize the technology in various fields.
Keyword Spotting Technology that Filters Users' Voices
Title: "iPhonMatchNet: Zero-shot User-Defined Keyword Spotting Using Implicit Acoustic Echo Cancellation"
Audio AI Lab - Yong-Hyeok Lee, Namhyun Cho
Read more about the research here.
One of the most important features of speech recognition technology is filtering the user's speech. The importance of recognizing the user's voice only amplifies in situations where the microphone catches various noise, such as environments where speakers are used instead of headsets or console games are played via TV. iPhonMatchNet is a keyword spotting model that can only recognize the keywords set by the user, even in surroundings where various noise is produced through speakers.
PhonMatchNet, the base study for iPhonMatchNet published in INTERSPEECH 2023, is a zero-shot keyword spotting model that immediately recognizes the keyword that was input by the user. Therefore, it can immediately understand and recognize the user's keyword without undergoing "sample voice recording" and "additional learning" steps that used to hinder the user's experience in the existing keyword spotting system.

Proposed Model Structure
iPhonMatchNet has implemented an iAEC (Implicit Acoustic Echo Cancellation) module on the existing PhonMatchNet, which shows remarkable performance in recognizing user keywords while ignoring audio generated by speakers. This research was successful in proving that the iPhonMatchNet performed drastically better than the existing PhonMatchNet in speech recognition in environments where audio signals, such as music or voices, were produced through speakers. According to the results of the experiment, the addition of 1K iAEC-related model parameters to the existing 655K models yielded an over 99% decrease in keyword recognition errors due to self-triggering issues. The current structure can only support one language per model, but the team is planning to implement the IPA (International Phonetic Alphabet) on this model to create a comprehensive zero-shot keyword spotting model that is not restricted by language.
Voice Learning Technology that Generates a Virtual Voice According to the Face, Synthe-Sees
Title: "Synthe-Sees: Multi-Speaker Text-to-Speech for Virtual Speaker"
Audio AI Lab - Jae Hyun Park, Joon-Gyu Maeng, Young-Sun Joo / SK Telecom - TaeJun Bak
Read more about the research here.
Many have been studying virtual voice generation using images of faces. However, most of the existing virtual voice generation technology has inconsistency issues, such as failing to generate the same voice for different images of the same speaker or generating similar voices for different speakers. This research introduces the facial encoder* module for the pre-trained multi-speaker TTS system, Synthe-Sees, to address the issue. The purpose of this module is to utilize face embeddings to generate speaker embeddings with a completely different virtual voice from the voice used for training and the existing voice samples. That is because generating a virtual voice that matches a face will save time and money in creating an audio database to use for training and reduce the number of voice actors required for adding new voice lines. Through this module, not only will the voice match the image of the face, but it will also remain consistent.
- *Facial encoders process images of faces, extract the key features of the image, encode it, and create vectors of facial features such as the eyes, the nose, and the mouth.
Synthe-Sees's facial encoder was trained via two methods. First, it was trained to capture the discriminative speaker attributes of the speaker using a dataset that is capable of distinguishing the speaker in order to create consistent speaker embeddings. Second, it was trained to reflect the internal structure of the speech embedding and enable the pre-trained multi-speaker TTS system to generate various, high-quality voices.
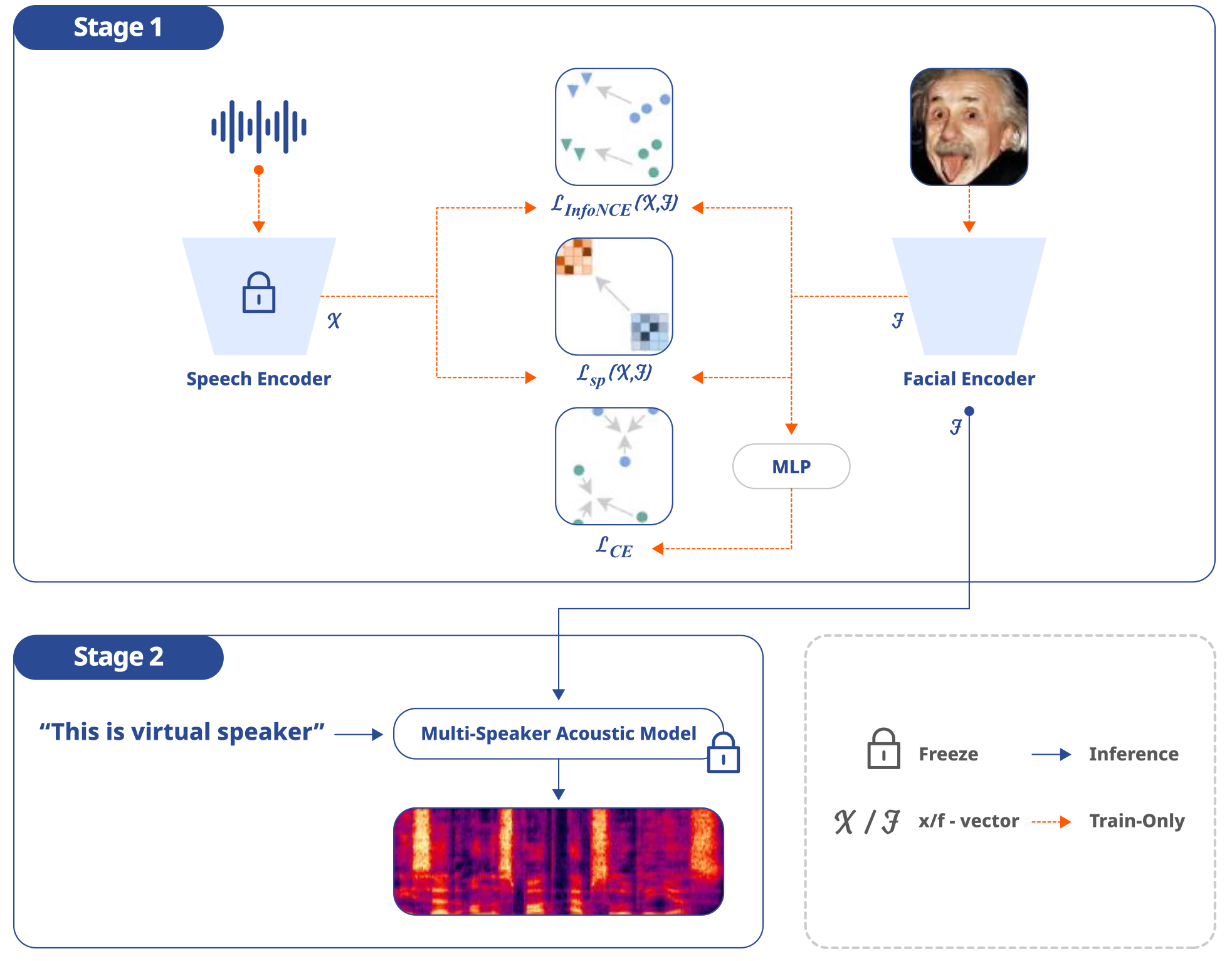
Proposed Model Structure
The team conducted both quantity and quality tests to evaluate the abilities of Synthe-Sees. In the quantity test, the team implemented indicators to measure the consistency of voice embedding generated by the same speaker in order to evaluate how it distinguishes speakers and how the speaker varies. In the quality test, 25 native English speakers were given 20 voice samples to evaluate properties such as fluency, intelligibility, and sound quality. It was confirmed that it generated clearer, more consistent, high-quality voices compared to the other new methods in both quantity and quality evaluations. You can access the demo website through the following link. Link
AI and Games that Will Create Greater Joy
NC strives to develop "service-centric technology" in various fields related to gaming. AI will be further integrated into the game-developing pipelines in order to raise the development productivity and competitiveness of games. Moreover, NC will focus on user-centric AI research to help technology research eventually lead to greater joy for gamers. Stay tuned for the enhanced gaming experience that will be delivered by the collaboration of games and AI.