엔씨 AI CENTER 산하 Speech AI Lab은 8월 체코에서 열린 음성 분야의 국제학회인 Interspeech에서 논문 4편의 게재를 승인받는 성과를 올렸습니다. 이번에 발표한 논문들은 엔씨의 독자적인 음성 합성 기술에 관한 노하우를 토대로 음성 합성 기술을 향상하고 다양한 연구에 응용할 수 있는 가능성을 열었습니다. 지난 기사(링크)에서 논문 저자 인터뷰를 통해 연구 과정과 Speech AI Lab의 연구 문화를 전했다면, 이번 기사에서는 4편의 논문 내용을 간략히 소개하고 연구 방법과 함께 실제 데모 음성을 공개하겠습니다.
가창 음성을 합성하는 N-Singer 모델
: 독자적인 Singing Voice Synthesis (SVS) system 연구 개발
“N-Singer: Non-Autoregressive Korean Singing Voice Synthesis System for Pronunciation Enhancement”, Interspeech 2021
이경훈, 김태우, 배한빈
데모: Demo page of N-Singer (nc-ai.github.io)
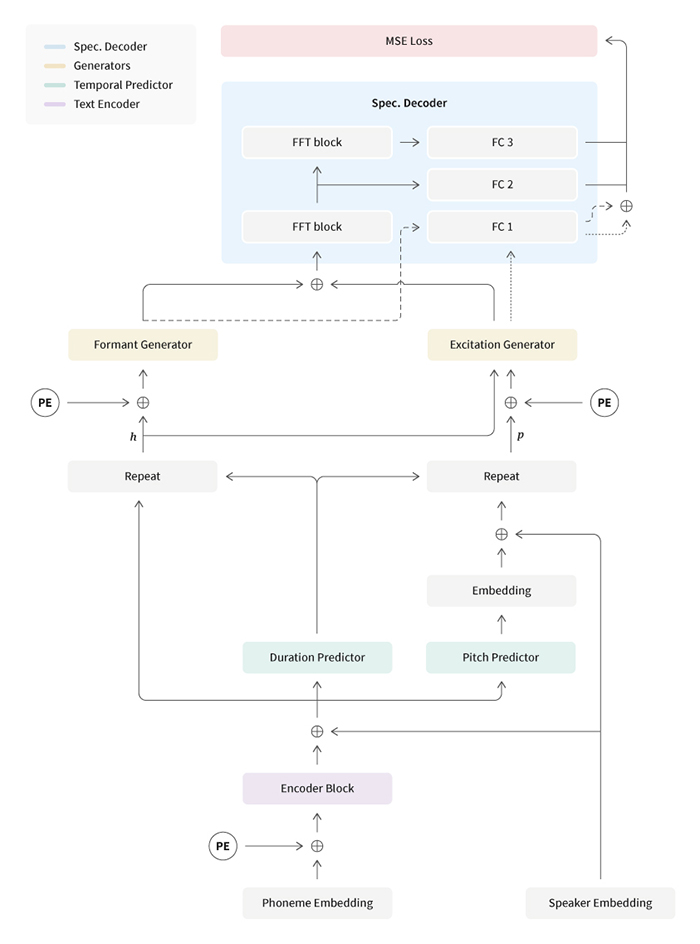
올해 초 Speech AI Lab은 산하에 Singing Voice TF팀을 만들고, 기존의 음성 합성 기술을 이용하여 사용자에게 새로운 즐거움을 제공하기 위해 ‘가사와 음악 정보로 가창 음성을 합성하는 N-Singer 모델’을 연구하기 시작했다. N-Singer는 비자기회귀(Non-autoregressive) 가창 음성 합성(Singing Voice Synthesis, SVS) 모델의 줄임말이다. 이 단어를 발음하면 NC Singer인데, NC를 대표하는 AI Singer를 의미한다. 즉, 가창 음성을 합성하여 노래할 수 있도록 했다는 뜻이다.
이번 연구를 위해 Singing Voice TF팀은 음성 합성과 가창 음성 합성에 관한 연구 자료를 수집했다. 데이터 셋의 경우 문제의 난이도를 낮추기 위하여 한국 발라드를 타깃으로 설정하고 주어진 음을 정확히 만들어내는 데 초점을 맞췄다. 데이터는 오디오 파일과 가사, 미디 파일들을 따로 정제하여 구축했다. 음성 합성 분야에서 발화의 안정성, 자연성을 높이기 위한 방법론들을 토대로 기본 모델의 구조를 만들었고, 품질 높은 음성을 합성할 수 있는 뉴럴 보코더를 채택했다.
이 연구를 통해 더 뚜렷한 발음으로 가창 음성을 합성함으로써 노래에서 중요한 요소 중 하나인 가사 전달력을 개선하였다. 또한 음성합성팀이 그동안 축적한 음성 합성 기술에 관한 노하우로 독자적인 Singing Voice Synthesis (SVS) 시스템을 설계했다. 이를 통해 엔씨의 사운드 센터와 함께 데이터를 수집, 가공하여 마침내 AI 가창 합성 기술을 실현하였다.
계층적 구조의 Transformer 기반 음성 합성 모델
: Transformer 기반 음성 합성기의 성능 향상을 위한 연구
“Hierarchical Context-Aware Transformers for Non-Autoregressive Text to Speech”, Interspeech 2021
배재성, 박태준, 주영선, 조훈영
데모: Demo page of Hierarchical TNA-TTS (nc-ai.github.io)
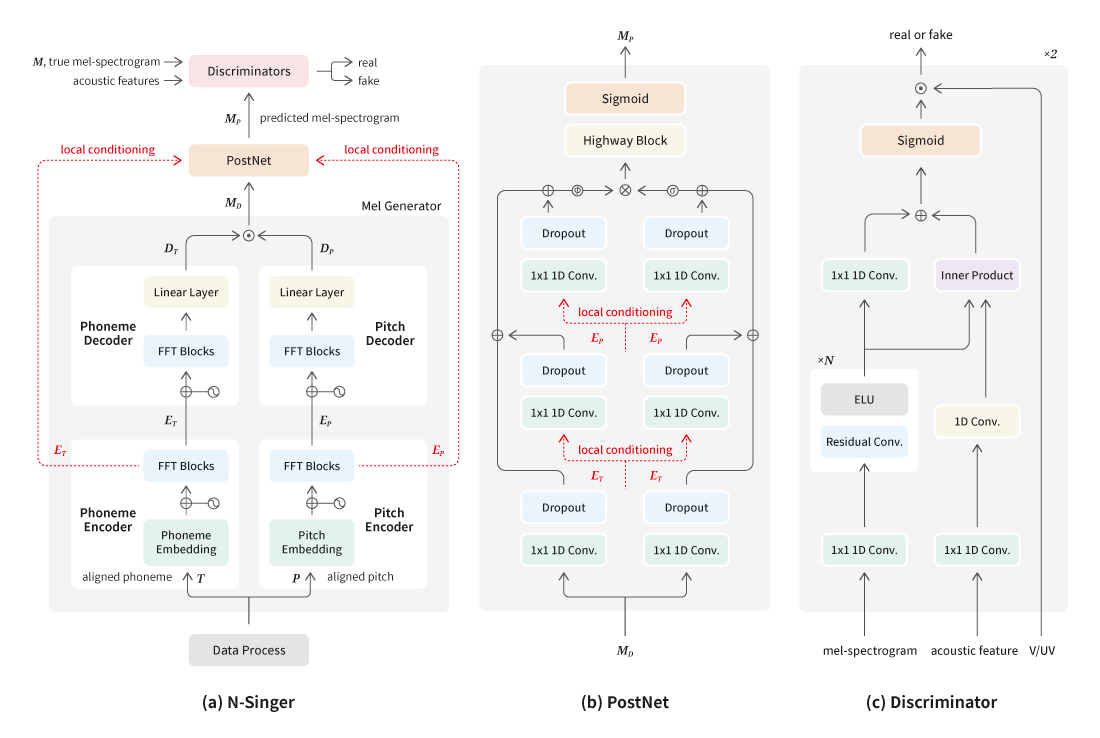
음성 합성에서는 발음이 정확한 음성을 생성하는 것이 매우 중요하다. 최근 등장한 트랜스포머(Transformer)에 기반한 비자기회귀(non-autoregressive) 음성 합성 모델들은 음성을 생략하거나 반복하지 않고 안정적인 음성을 생성할 수 있다. 그러나 음성합성팀은 트랜스포머에 기반한 비자기회귀 음성 합성기의 자연성이나 발음의 정확성에 만족하지 못했다. 그래서 음성 합성기가 다루는 텍스트와 오디오의 데이터 특성을 고려하여 계층적 구조의 트랜스포머에 기반한 음성 합성 모델을 개발했다.
[그림 2] 계층적 구조의 트랜스포머에 기반한 음성 합성 모델 구조
생성 모델에 관한 연구에서 매번 겪는 어려움 중 하나는 성능을 적절히 평가하는 일이다. 이를 해결하기 위해 1차적으로 내부에서 주관적으로 평가하여 어느 정도 성능이 좋은 모델 구조를 찾은 후, 다양한 객관적 평가 지표와 주관적 평가를 함께 활용하여 모델의 성능을 최종적으로 평가하였다.
샘플 1
– Sentence: 한참 연주 결혼식 준비할 때도 니가 그때 얘가 나쁜 애는 아닌데 지금 상황이 너무 힘들어서 그렇다고 그랬잖아.
– (Pronunciation): Hancham yeonju gyeolhonsig junbihal ttaedo niga geuttae yaega nappeun aeneun aninde jigeum sanghwang-i neomu himdeul-eoseo geuleohdago geulaessjanh-a.
샘플 2
– Sentence: 일단 도착하자마자 숙소에 짐 풀고 우리 둘은 샤워하고 애들이랑 바다 가서 술 마시고 놀았지.
– (Pronunciation): Ildan dochaghajamaja sugso-e jim pulgo uli dul-eun syawohago aedeul-ilang bada gaseo sul masigo nol-assji.
[샘플 1,2] 계층적 구조의 트랜스포머에 기반한 음성 합성 모델과 기존 모델 비교
그 결과 발음이 더 정확한 합성음을 생성할 수 있었다. 그리고 트랜스포머에 기반한 음성 합성 모델의 self-attention layer에 다양하게 분석적으로 접근하여 다른 연구자들에게 트랜스포머에 기반한 음성 합성에 관한 인사이트를 줄 수 있었다.
음원여과기 이론을 접목한 합성 모델
: 합성음의 과다한 피치 조절 구간에서도 고품질의 음성을 생성하기 위한 연구
“FastPitchFormant: Source-filter based Decomposed Modeling for Speech Synthesis”, Interspeech 2021
박태준, 배재성, 배한빈, 김영익, 조훈영
데모: Demo page of FastPitchFormant (nc-ai.github.io)
음성합성팀은 품질 높은 음성 합성 기술을 보다 다양한 서비스에 제공하기 위해 운율 제어 기술(Prosody Control)도 연구하고 있다. 지난해 소개된 ‘중계체’ 합성 기술이 좋은 사례이다. 대표적인 운율 제어 방법으로는 합성음의 높낮이, 세기와 같은 음향적 특징을 조절하는 방법이 있다.
연구 과정에서 음성의 특징 분포상 평균보다 멀리 떨어진 값으로 운율을 제어하면 합성음의 품질과 화자 유사도가 낮아지는 문제점을 발견했고, 문제의 원인은 텍스트와 운율 정보를 함께 다루는 모델의 구조적 한계 때문이라고 결론 내렸다. 그래서 본 연구에서는 음원여과기 이론(Source-Filter Theory)을 접목하여 텍스트와 운율을 별도로 모델링하는 합성 모델을 제안했다.
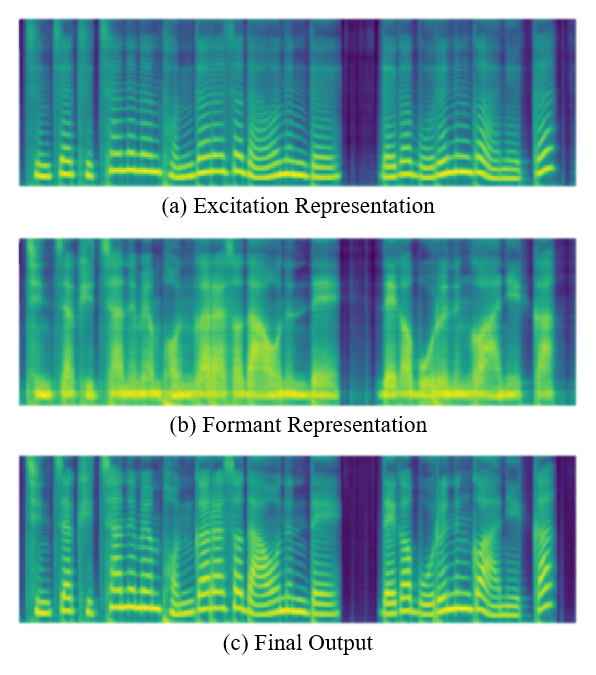
[그림 4] 본 모델의 기본적인 동작 원리 – 여기 신호 표현(Excitation Representation), 포만트 표현(Formant Representation)이 각각 존재하고, 두 표현을 통해 최종 음성을 합성하는 원리이다.
샘플 3
– Sentence: 진짜 귀찮으면 번갈아서 나오는데 내가 모르는 거 아닐까?
– (Pronunciation): jinjja gwichanheumyeon beongaraseo naoneunde naega moreuneun geo anilkka?
Excitation Representation
[샘플 3] 여기 신호 표현(Excitation Representation), 포만트 표현(Formant Representation), 합성음(Final Output) 샘플
그리하여 본 연구에서는 음향적 특징값(pitch, energy)으로부터 형성되며 성대의 진동을 나타내기 위한 여기 신호 표현과, 텍스트로부터 형성되며 성도에서의 공명 주파수(formant frequency)를 나타내는 포만트 표현 두 가지로부터 최종 음성을 생성하도록 모델을 설계했다.

[그림 5] 위의 -8, -6, -4 … +8 등의 숫자는 세미톤(semitone)이라는 단위로 음성의 높낮이(피치)를 조작한 것을 의미한다. 아래의 % 단위 숫자는 평소 화자의 높낮이 100%를 기준으로 하여 세미톤 단위로 조절하면 몇 %로 변화하는지를 표시한 값이다.
샘플 4
– Sentence: 나는 몇 달째 계속 못 들고 있는데 넌 어떻게 들었어?
– (Pronunciation): naneun myeot daljjae gyesok mot deulgo issneunde neon eotteohge deureosseo?
-8 / FastPitch (Baseline)
-8 / FastPitchFormant (proposed)
-8 / Excitation Representation from FastPitchFormant (proposed)
-8 / Formant Representation from FastPitchFormant (proposed)
-6 / FastPitch (Baseline)
-6 / FastPitchFormant (proposed)
-6 / Excitation Representation from FastPitchFormant (proposed)
-6 / Formant Representation from FastPitchFormant (proposed)
-4 / FastPitch (Baseline)
-4 / FastPitchFormant (proposed)
-4 / Excitation Representation from FastPitchFormant (proposed)
-4 / Formant Representation from FastPitchFormant (proposed)
Female(KOR) / FastPitch (Baseline)
Female(KOR) / FastPitchFormant (proposed)
Female(KOR) / Excitation Representation from FastPitchFormant (proposed)
Female(KOR) / Formant Representation from FastPitchFormant (proposed)
+4 / FastPitch (Baseline)
+4 / FastPitchFormant (proposed)
+4 / Excitation Representation from FastPitchFormant (proposed)
+4 / Formant Representation from FastPitchFormant (proposed)
+6 / FastPitch (Baseline)
+6 / FastPitchFormant (proposed)
+6 / Excitation Representation from FastPitchFormant (proposed)
+6 / Formant Representation from FastPitchFormant (proposed)
+8 / FastPitch (Baseline)
+8 / FastPitchFormant (proposed)
+8 / Excitation Representation from FastPitchFormant (proposed)
+8 / Formant Representation from FastPitchFormant (proposed)
[샘플 4] 기존에 제안된 모델(FastPitch)과 비교하기 위한 샘플이다. baseline과 proposed 두 모델의 높낮이(-8, -6, -4, 0, +4, +6, +8)를 변화시키며 합성음을 만들 때의 차이를 보이는 샘플로, 음성의 높낮이를 넓은 범위에서 조절해도 품질이 더 향상된 합성음을 만들 수 있다는 본 연구의 장점을 잘 보여준다.
이 연구를 통해 텍스트(언어적) 정보와 음향적 특징을 분리하여 모델링하는 음성 합성 모델을 설계하여, 넓은 범위의 운율 제어에서도 품질 높은 음성을 생성하고 운율 제어의 정확도와 합성음 화자 유사도를 향상시켰다. 운율 정보가 구조적으로 분리되어 있으므로 추후 감정 혹은 스타일 전이가 가능한 합성 모델로 발전시킬 수 있으리라고 기대된다.
GANSpeech: GAN을 이용한 높은 품질의 다화자 TTS
: 서비스를 위해 더 나은 품질의 음향 모델 설계를 위한 연구
“GANSpeech: Adversarial Training for High-Fidelity Multi-Speaker Speech Synthesis”, Interspeech 2021
양진혁, 배재성, 박태준, 김영익, 조훈영
데모: Demo page of GANSpeech (nc-ai.github.io)
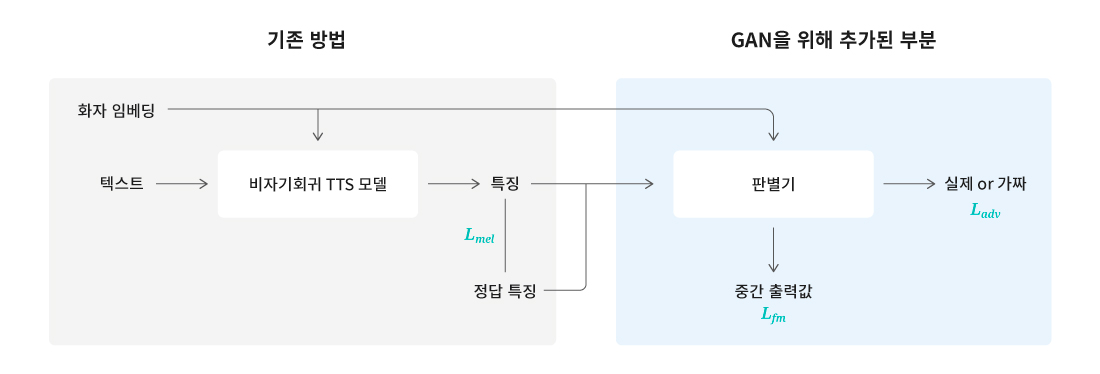
[그림 6] GANSpeech의 대략적인 구조. 출력의 특징은 멜 스펙트로그램을 사용한다는 점이다. 학습 이후 생성 단계에서 판별기는 제거된다.
기존에는 수많은 목소리를 하나의 모델로 제공하는 과정에서 성능이 저하되는 현상이 나타났고, 이를 최적화하기 위해 각각의 목소리에 모델을 적응시키면 모델의 개수가 목소리 개수만큼 필요하다는 문제가 있었다. 음성합성팀은 올해 초부터 UNIVERSE에서 아티스트 100명 이상의 목소리를 서비스하고 있는데, 하나의 모델로 품질 높은 음성을 제공하기 위해 연구를 진행했다.
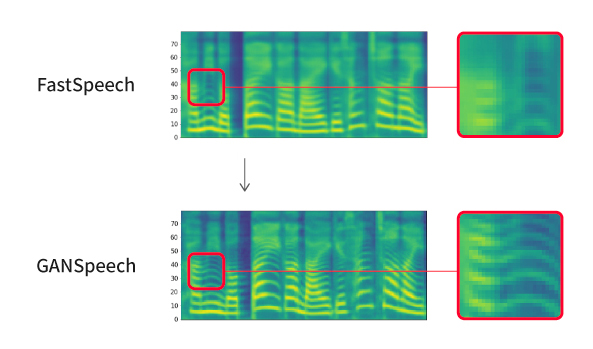
[그림 7] 기존 방법과의 스펙트로그램 비교. 하단의 스펙트로그램이 높은 주파수 대역까지 더 선명하고 정교하다.
음성합성팀이 제안한 방법은 기존 방법(FastSpeech1, FastSpeech2)을 활용하되 GAN(Generative Adversarial Network)을 추가로 도입하여 학습하는 것이었다. 기존의 학습 방법은 모델로 생성한 스펙트로그램을 정답과 픽셀 단위로 L1 거리를 계산하여 손실 함수(loss function)로 사용하는데, 그러면 그림 7 상단의 스펙트로그램과 같이 전체적으로 흐릿하고 뭉개지는 현상이 나타난다. GAN을 이용하면 이러한 현상을 해소할 수 있다. 즉, 판별기에 입력하고 스펙트로그램을 사용하여 진짜(정답 스펙트로그램)인지 가짜(TTS 모델로 생성한 스펙트로그램)인지 판별하고 실제 분포를 추정하도록 학습한다. 또한 GAN을 안정적으로 학습하기 위해 기존 방법의 손실 함수를 균등한 비중으로 반영하도록 동적으로 비중을 조정하였다.
샘플 5
– Sentence: “한때 명성이 자자했던 화씨 대 가문도 과거에 묻히게 되었다.”
– (Pronunciation): “hanttae myeongseongi jajahaessdeon hwassi dae gamundo gwageoe muthige doeeossda.”
[샘플 5] 실험에서 두드러진 차이가 나타난 FastSpeech1과 동일 모델에 기반한 GANSpeech의 비교 샘플
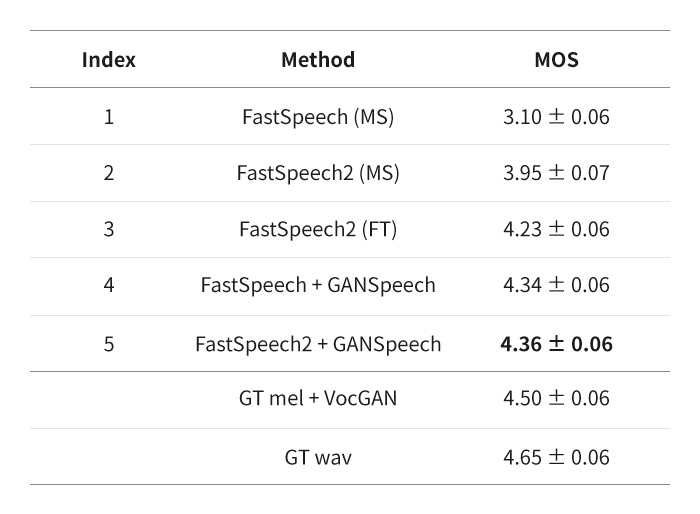
[표 1] 청취 평가 결과. MS는 다화자 모델, FT는 특정 화자에 적응시킨 모델, GT는 정답을 나타낸다.
결과적으로 GANSpeech를 통해 단일 모델로도 다수의 화자가 더 품질 높은 음성을 생성하도록 개선하였다. 또한, 실험을 통해 제안하는 방법이 특정 TTS 연구에 국한하지 않고 성능을 개선할 수 있음을 보였다.
고품질 음성 합성 기술을 서비스에 제공하기 위한 노력
지금도 Speech AI Lab은 AI 합성음의 품질과 표현력을 높이기 위해 다양한 방법으로 연구를 진행하고 있다. AI 연구는 발전 속도가 빠르므로 새로운 기술이 나오면 그 전의 기술은 의미가 없어지기도 한다. 하지만 Speech AI Lab은 기존의 기술에 NLP 분야의 연구를 활용하여 적용하거나, 다른 분야와 융합하며 연구를 확장하고 있다. 앞으로도 독자적인 음성 합성 기술력을 확보하고 보다 퀄리티 높은 합성음을 만들기 위해 연구개발에 노력을 아끼지 않을 것이다. 나아가 AI 기술을 사용자들의 즐겁고 편리한 일상에 활용할 수 있도록 서비스를 개발하는 한편, 무엇보다 기술을 올바르게 사용할 수 있도록 세심하게 주의하며 연구를 이어갈 것이다.
 Facebook
Facebook  KakaoTalk
KakaoTalk  LinkedIn
LinkedIn  Email
Email  Copy URL
Copy URL