The paper about regularizing gender bias in coreference resolution, authored by SunYoung Park of NCSOFT’s NLP (Natural Language Processing) Center’s Natural Language Team (Search Tech Division), is accepted to the 16th International WSDM (Web Search and Data Mining) 2023 Conference. This article will introduce the new language model learning methods proposed in the paper, which aims to recognize and alleviate gender bias in natural language understanding.
Language models, including OpenAI’s ChatGPT and Google’s BARD, have recently been in the spotlight. ChatGPT is said to be gained users even faster than TikTok. After throwing a few sentences to OpenAI’s ChatGPT, one might be reminded of the AI assistant ‘JARVIS’ from the movie 〈Ironman〉. How can these language models generate such excellent responses that seem like they were written by humans? The answer lies in the “data.” The machine, which was originally nothing but a shell, becomes capable of imitating humans through deep learning based on vast amounts of text data written by people. In reality, these machines do not “think” to come up with a response, but rather utilize their learned data to generate responses with the highest probabilities.
Is it possible to construct high-quality language models using just large amounts of text and GPUs? The answer is both yes and no. If the goal is simply to create a language model that speaks well like a human, inputting a massive amount of data into the model and training it without any restrictions would not pose a significant problem. However, imagine a language model being frequently used as a tool for evaluating people or in real-life situations. If the language model evaluates people differently or produces unethical comments based on their gender and race without any filters, using the model will not be easy, even if its language skills are excellent.
The Continuing Problem of AI: Gender Gap
The majority of language models are pre-trained based on large corpora, including Wikipedia. By pre-training with large corpora as a foundation, language models can obtain basic language abilities. After fine-tuning the model with targeted data, it is possible to build a language model that fits the needs of the user. However, data bias is a fundamental issue that arises here. Not all written content is ethically correct, and the data may not represent a balanced gender ratio or social diversity. Is it possible to use data sets that are balanced in terms of representing various social groups, including males, females, queer individuals, and people of different races such as White, Asian, and Black? Previous studies have revealed that the data used for pre-training in many cases were biased towards specific groups of people. For instance, the most commonly used dataset for pre-training language models, Wikipedia, reportedly has only 15.5% of its content related to female figures.
One might suggest adjusting the distribution of training data as a solution to this problem. If you don’t have the resources to pre-train your model from scratch, it is common to download pre-trained language models provided by large tech companies like Google or OpenAI. The use of biased data during pre-training can naturally cause the language model to learn and reproduce bias, creating a cycle that perpetuates bias. The model is biased even before fine-tuning.
It is not an easy task for a typical developer to adjust a pre-trained language model. However, there is too much risk to use a model that is clearly biased. Therefore, there are many recently proposed debiasing techniques that aim to adjust the model's biases during the fine-tuning stage. There are many topics related to biases and inequality, but in this article, we will primarily focus on gender bias. As mentioned earlier, commonly used datasets are typically composed of examples that are male-centric. It is often said that many datasets reflect traditional gender roles and biases. Training a model with such data inevitably increases the likelihood of creating a biased model with gender discriminatory characteristics.
Stereotypes and Skews
Biased models commonly exhibit two phenomena: Stereotypes and skews. For instance, consider a sentence like “[MASK] is a doctor and has a high salary,” where the blank must be filled in with either ‘He’ or ‘She’ in the absence of any context. An unbiased model would predict ‘He’ and ‘She’ with equal probability (i.e., 50% each) since there is no prior context. However, in the real world, models are more likely to choose “He.” This is because either the model learned the stereotype that doctors are typically male or the pre-training data contained significantly more text related to men, resulting in skewed predictions towards “He.”
In the case of existing debiasing methodologies, they generally attempted to solve the problem by using data augmentation. The idea behind this is to balance the male and female data even during the fine-tuning stage, as it was thought that using such data for fine-tuning could resolve the issue. Or there is a method that involves separate post-processing techniques to adjust the probability. The use of existing methods has mitigated the “skew” in language models, but the problem of “stereotypes” remained unsolved. Additionally, when training the model using augmented training data, a phenomenon was observed where the model’s natural language understanding ability was degraded. The approach of simply modifying the data or adjusting the outputs of pre-trained models was not sufficient.
Bias Mitigation Methods 1: Stereotype Neutralization (SN)
The paper introduces new learning methods to address issues of stereotypes and improve the problem of degradation of natural language understanding performance. It is important not only to remove prejudice before and after the model training process, but also to adjust the learning process to remove the bias of the model itself. The paper proposed two new techniques to address the issues of 1) stereotypes and 2) decreased performance in addition to correcting gender-biased models through data augmentation. The proposed approach adds penalty terms to the loss function during the fine-tuning stage, which can influence constraints related to biases that the model may learn.
The first methodology is called Stereotype Neutralization (SN). Before explaining the methodology, here is a brief description of word embeddings, which are vectors that represent words. The language model represents words as high-dimensional vectors that computers can understand and operate on. These vectors should capture the relationships between words in the corpus, which means that similar words are located closer to each other in the vector space, and words with different characteristics are further apart. If a language model contains bias, there is a high likelihood that words that embody gender stereotypes will be clustered together. In fact, when visualizing the word vectors for gender-biased job generated by BERT, we can observe that words with biased associations towards the same gender tend to cluster together.
Certain words such as “doctor,” “nurse,” “secretary,” and “CEO” should not be associated with a particular gender, while other words like “dad” and “mom” have inherent gender characteristics. Wouldn’t it be possible to reduce the model’s preconceptions about gender by increasing the distance between vectors of gender-neutral words and words that have gender characteristics? Based on this idea, the paper adds a normalization term based on orthogonalization to the existing loss function, so that two types of words are distinguished and find-tuned. Orthogonalization makes each word vector perpendicular to each other, making the distance between the two vectors as far as possible. This method eliminates the relationships between words so that words with different biases are distinguished from each other in the vector space. If the model is trained with this normalization term, the SN-based model has relatively less bias for specific words compared to pre-trained language models.
Bias Mitigation Methods 2: Elastic Weight Consolidation
If SN was intended to address the problem of gender stereotypes, Elastic Weight Consolidation (EWC) was proposed as a method to address the problem of performance degradation in models trained in data augmentation environments. Generally, EWC is a methodology commonly used when retraining models on multiple data or tasks to ensure that they do not forget their previous learning. In the paper, Fisher Information-based EWC regularization terms, which contain the main parameter information of the model, are added to the loss function and used. If the model is trained with reference to the main parameter values of existing pre-trained language models, it means that the performance of models learning with augmented data will be less degraded. For instance, in a task of removing bias from a BERT model, it means that the importance of each parameter in the general BERT model is calculated and the training proceeds in the direction of maintaining the main parameters as much as possible. This limits the learning process of pre-trained language models to maintain its exceptional language understanding capabilities. Even if bias is well removed, if language ability is compromised, ultimately its value as a language model will decrease.
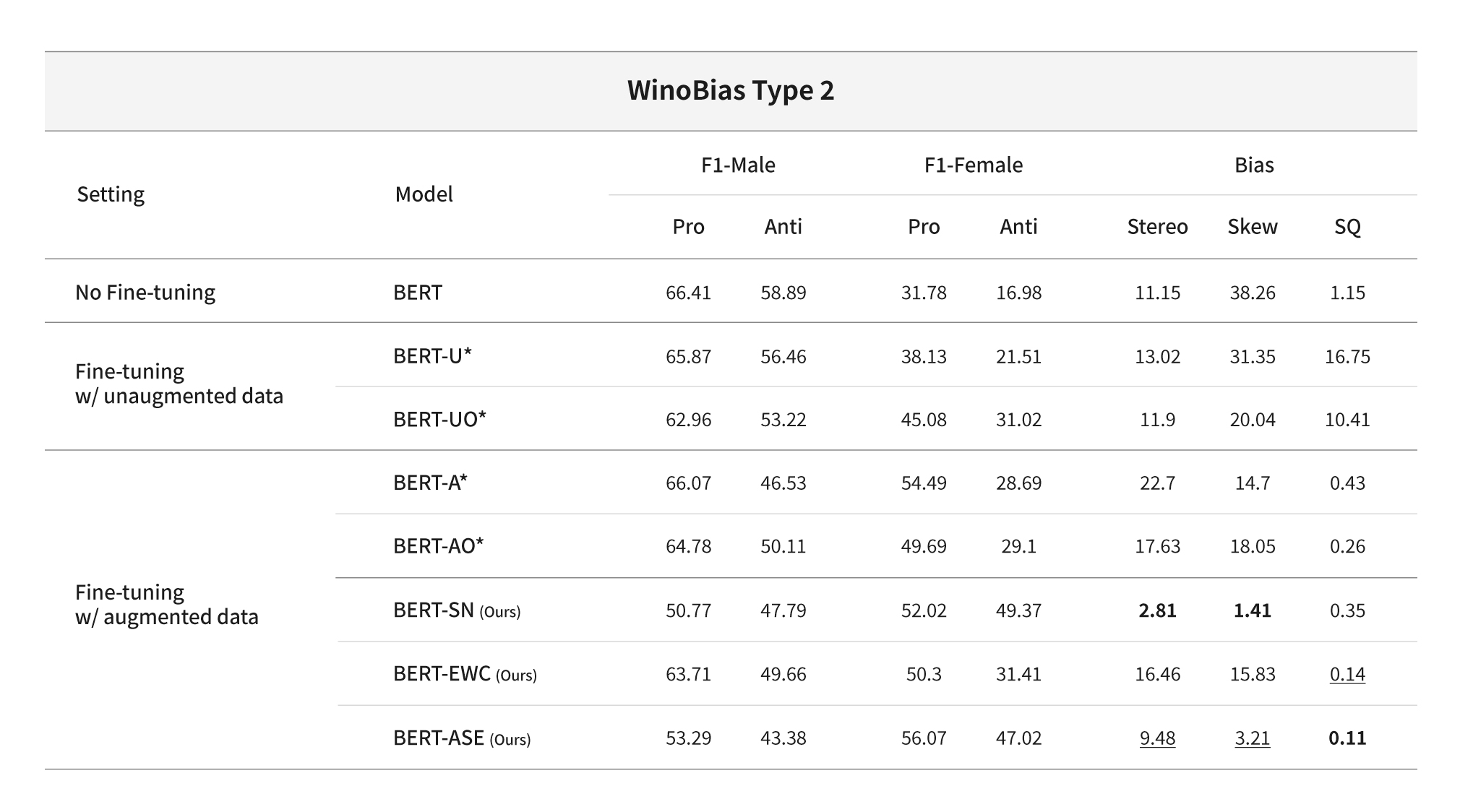
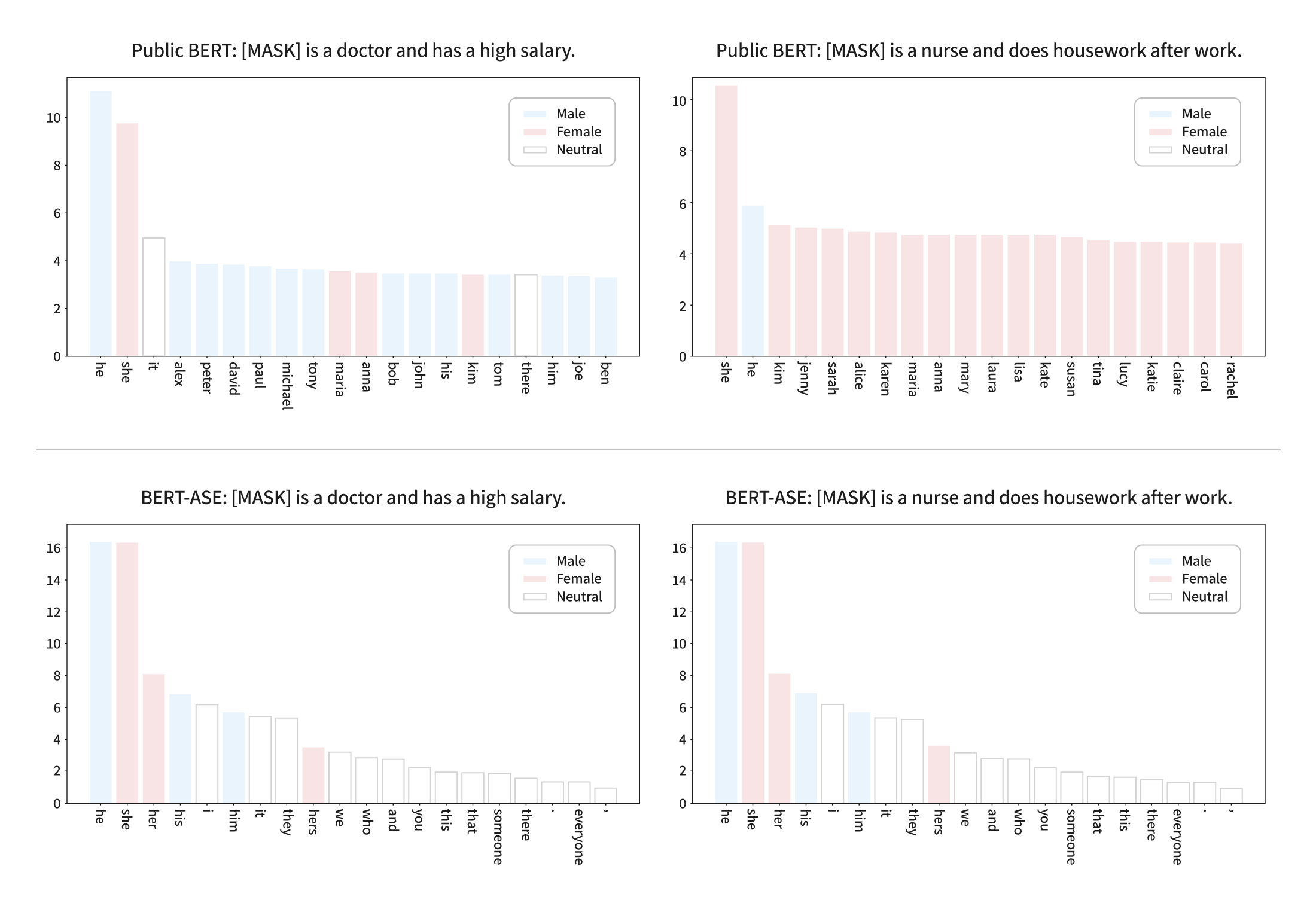
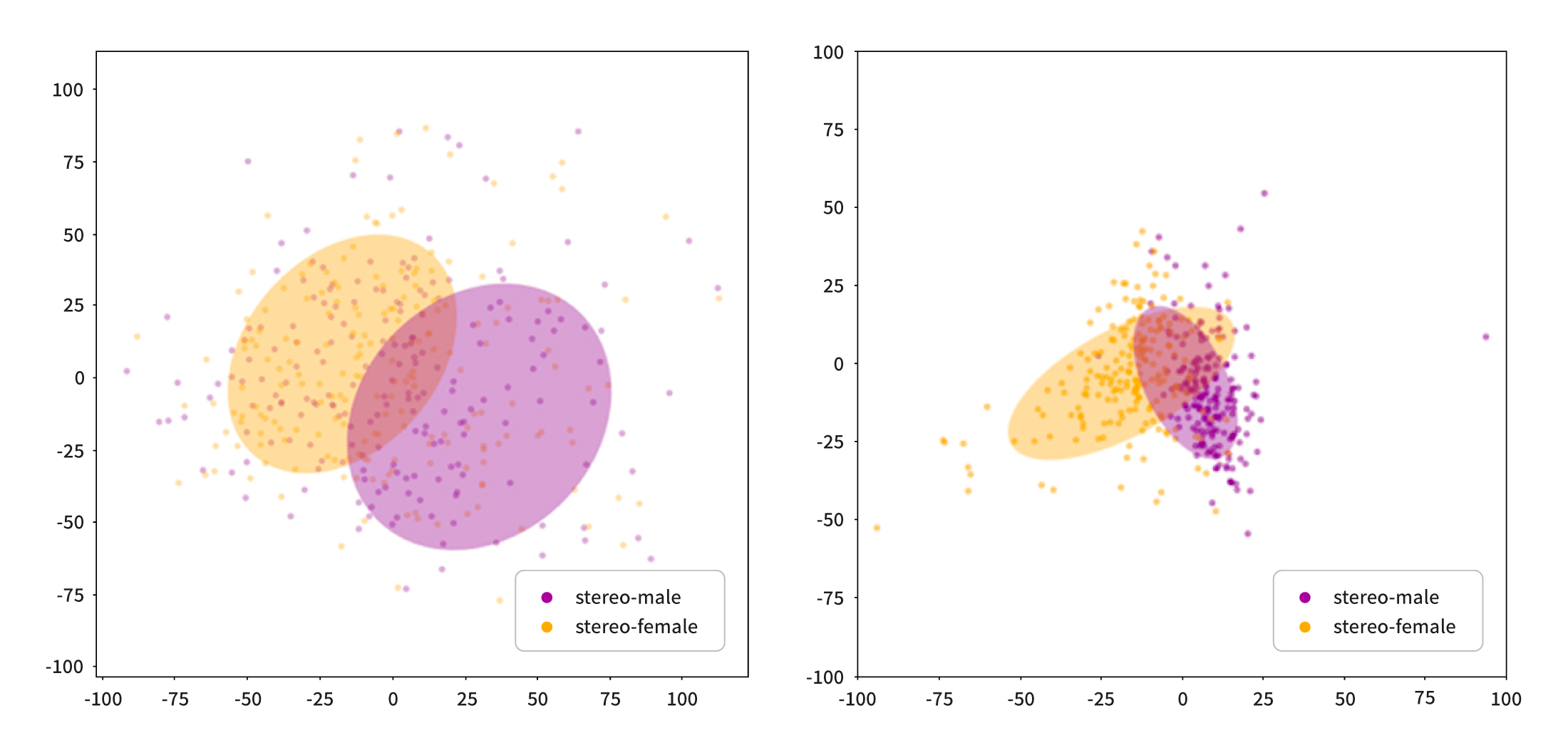
In the case of the BERT-ASE (Augmentation+SN+EWC) model, which adds both SN and EWC to the existing loss function, it reduces the stereotypical traits of the model and prevents the degradation of the model’s inherent linguistic ability simultaneously while resolving the skewness compared to the previously proposed methodologies. The qualitative analysis results are also interesting. In the sentence “[MASK] is a doctor and has a high salary,” BERT predicts male names more often, whereas BERT-ASE ranks neutral words as such as “It” or “They” higher. A clearer difference can be observed with the sentence “[MASK]s is a nurse and does housework after work.” BERT-ASE shows almost equal prediction rates for both male and female pronouns, while the existing BERT shows a tendency to skew towards “She” and female names. When visualizing the embeddings, the distance between embeddings of occupations with strong stereotypes is relatively reduced in BERT-ASE compared to BERT.
How to Embed Trust in Language Model
This paper suggests a new training scheme for mitigating gender biases in large-scale PLMs using algorithmic regulations while staying within the bounds of the existing learning paradigm. As interest in language models and the field of NLP increases, there is a need for a much deeper discussion on the developing of ethical language model. Even if answers generated by large language models contain incorrect information, it is extremely difficult for the average users to detect notice. Because the language models' ability to generate answers that seem too plausible, it can instantly undermine our previously held doubts and suspicions about the technology we originally possessed. No matter how well a model speaks naturally, it is dangerous to have AI models with biases in gender, jobs, race, and others to be widely distributed in our society. The methods for identifying and eliminating biases hidden in the flashy text generated by the model will become increasingly important in the future.
 Facebook
Facebook  Twitter
Twitter  Reddit
Reddit  LinkedIn
LinkedIn  Email
Email  Copy URL
Copy URL 

