Facebook
Facebook  Twitter
Twitter  Reddit
Reddit  LinkedIn
LinkedIn  Email
Email  Copy URL
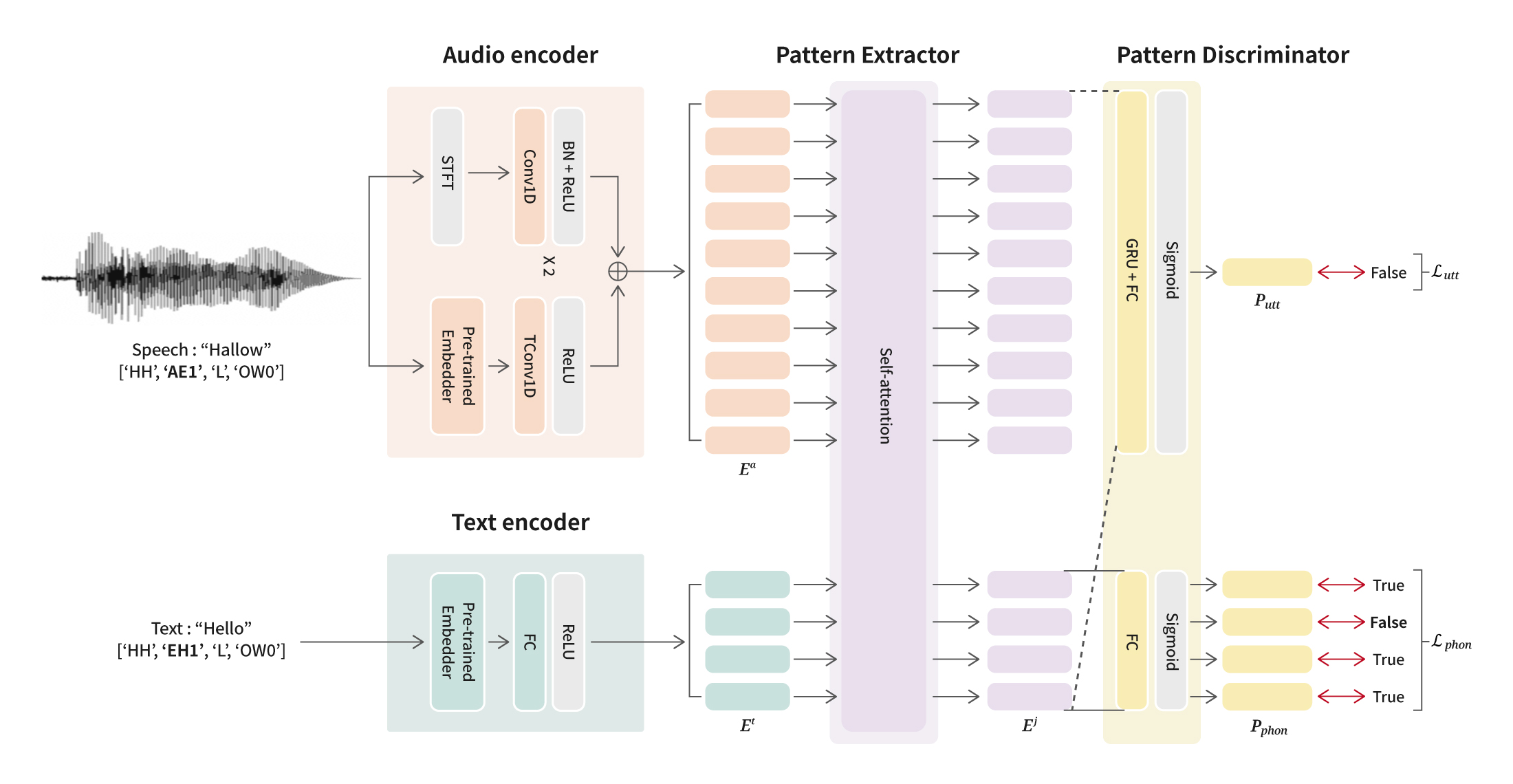
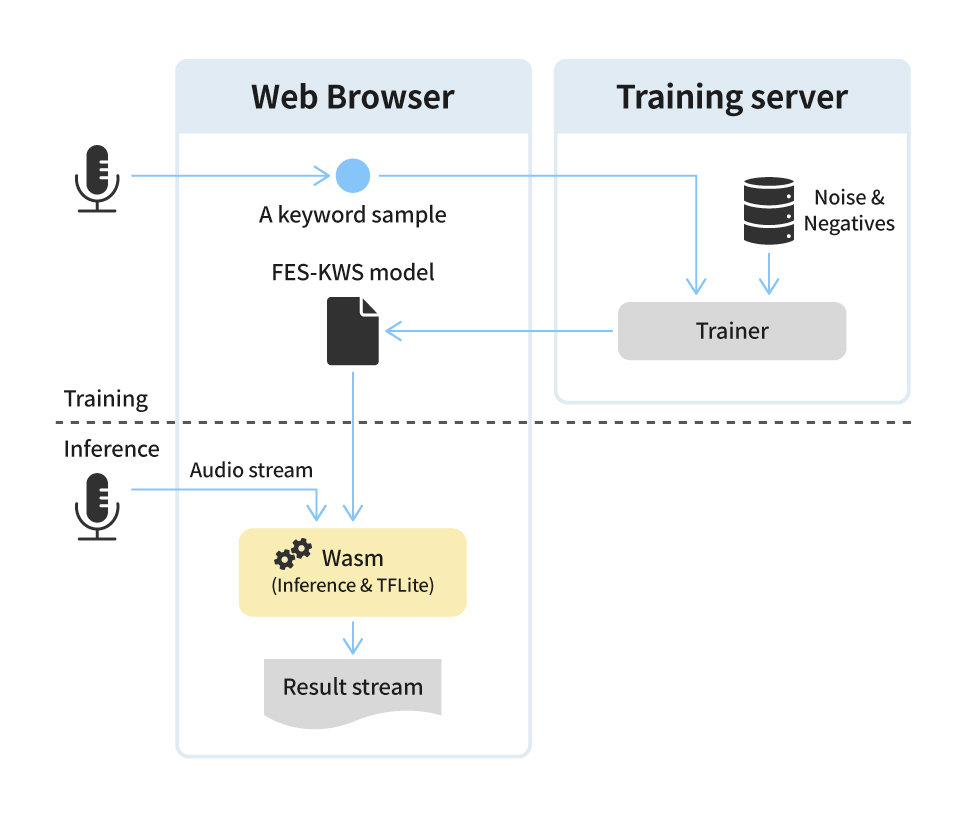
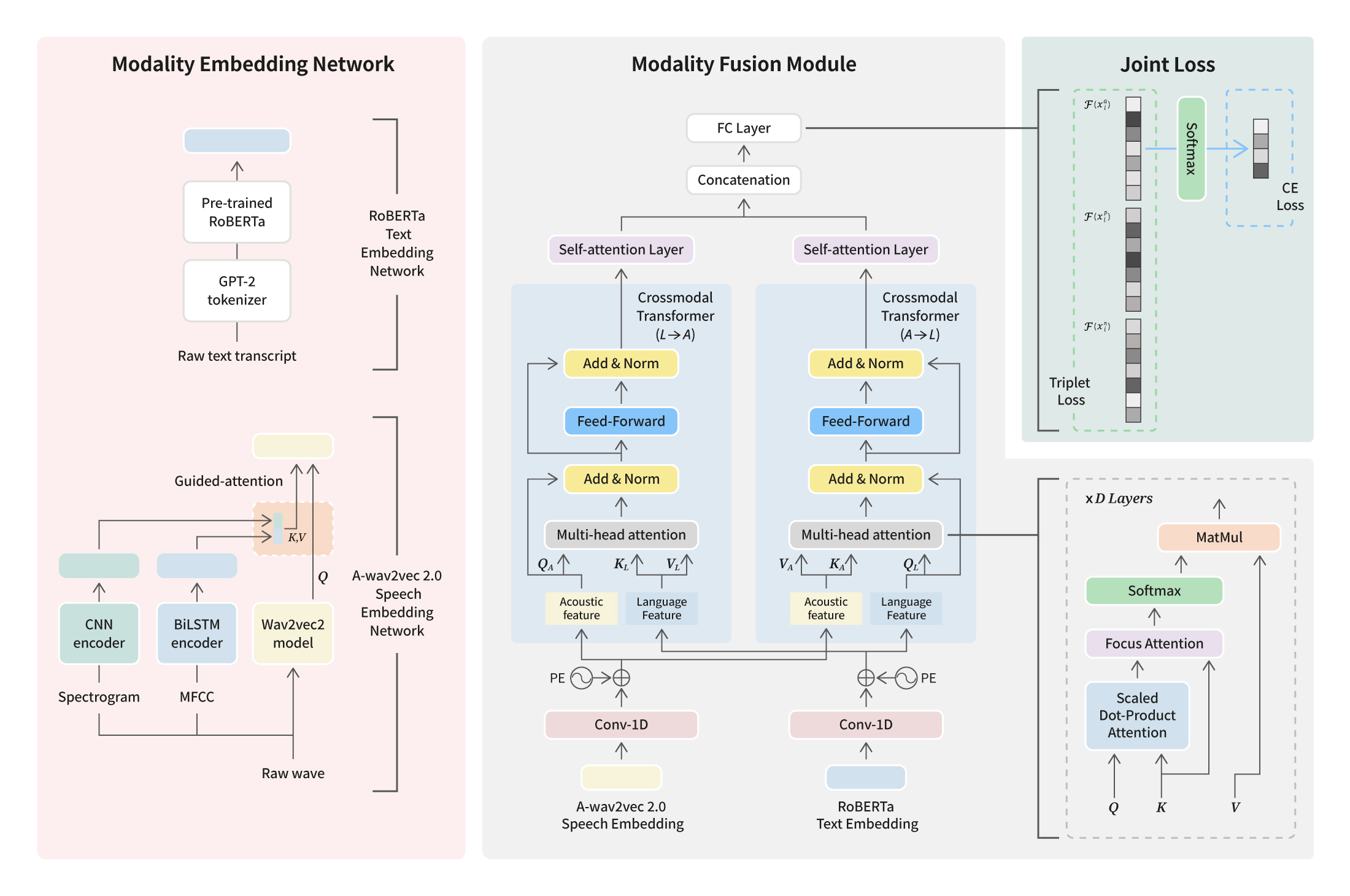
Copy URL The Speech AI Lab within NC’s AI Center has accomplished a significant achievement by consistently publishing research papers at INTERSPEECH, the world's largest and most comprehensive conference on the science and technology of spoken language processing, for four consecutive years. Over this period, the Speech AI Lab has been dedicated to presenting research papers that focus on enhancing the quality of verbal output and speech. While previous studies primarily delved into natural verbal communication and the generation of AI singing voice, the recent research papers covered a broader array of artificial intelligence models and systems. These results offer experiences that closely simulate interactions with real individuals, all aimed to create “digital humans” with the capacity to engage effectively with people.
NC has a steadfast commitment to the creation of digital humans capable of meaningful conversations with users. To create digital humans tailored to the unique preferences of individual users, the team has been prioritizing the development of technology, focusing not only on natural language communication but also on the recognition of users' speech and gestures. The compelling research findings presented at the INTERSPEECH 2023 conference are poised to drive the evolution of personalized digital humans. These digital entities are designed to readily adopt nicknames, provide swift responses at any time and place, and even comprehend and empathize with users' emotions. Let's delve into the three research papers that offer a sneak peek into the forthcoming advancements in speech technology.