NC dreams of a future where the world is connected with joy. The future includes practicing safe, transparent, and unbiased technology ethics to pursue righteous joy. To this end, NC fully understands the importance of AI technology development and ethical responsibility and actively managing its technology. In particular, it has established [NC] AI Ethics Framework to enable sustainable development of AI technology into the one based on ‘human values’.
The three core values of [NC] AI Ethics Framework include ‘Data Privacy’, ‘Unbiased’, and ‘Transparency’. NC pays attention to protect users’ data and to prevent social biases in the course of AI technology development and aims to develop ‘explainable AI’. Also, to enhance social awareness of AI ethics, NC is carrying out multiple projects including discussion with the world’s renowned scholars, joint research with external parties, and research support. In this article, we will explain the reason that NC has selected ‘Data Privacy’ as a core value and the activities that it is carrying out in relation to such a core value.
AI That Emphasizes Data Protection
The extensive collection of data shows the power of AI. The data collected to develop AI, including personal identification and tracking system and voice recognition service customized for each user’s needs, are likely to include personal information. Last year, the Ministry of Justice was mired in a controversy, since it provided personal facial images to an AI developer while developing an AI identification and tracking system to be utilized in immigration service. Even now, personal information is used for AI learning without giving any clear notification to users or obtaining their consent.
NC provides fundamental protection for user privacy and personal information when utilizing the data required for AI research and development. Also, to enhance awareness of importance of personal information protection across the company, it is regularly carrying out data protection and information handling trainings. These efforts have started to fundamentally prevent the possibilities where problems like leakage of service users’ personal information would occur based on data privacy protection and to start providing services after removing the possibilities of such problems to occur through reviewing the data in a repetitive manner.
Compliance with the Data Usage Policies at Home and Abroad
NC has established the “NC data usage policy and process” to comply with the data security regulations at home and abroad and to make sure that the data are safely utilized. Also, the policy and process are applied to AI research and development. Since 2021, the importance of proper personal information handling has increased, and NC AI Center has introduced an internal personal information protection system in a preemptive manner based on demands from the society. In particular, the NLP (Natural Language Processing) Center studies all texts created by people, and therefore, it has started to find the texts that are subject to ‘personal information’ protection. Diverse information may be included in the scope of personal information, including resident registration numbers, regional names, and personal names. Through reviewing the Enforcement Decrees, local laws, and related papers, NC has established standards on ‘what to be defined as personal information’ and ‘how to find such personal information from data’. In particular, in case public external data are used, NC has actively complied with the external data provider’s license and usage policies and maintained data privacy.
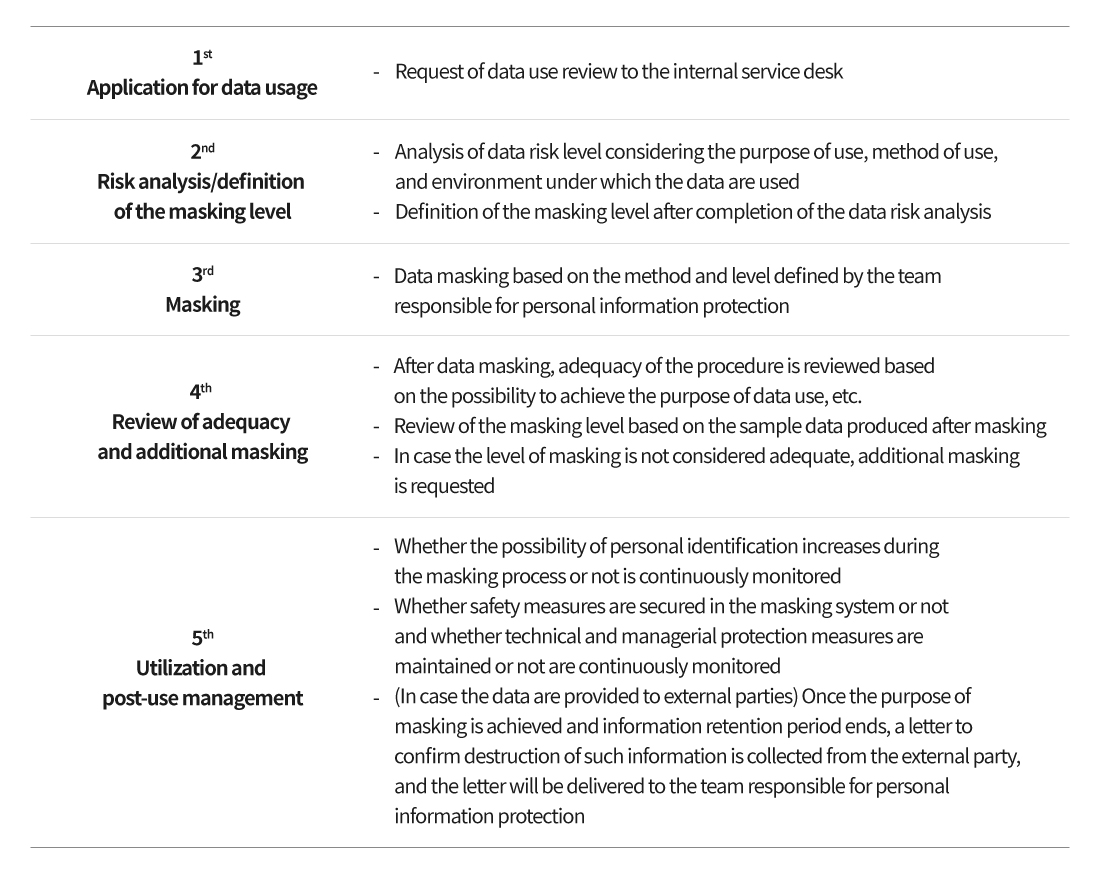

Prevention of Registration of User Identification Logs
In addition, NC prohibits registration of user identification logs to protect personal information in the data used in AI learnings. User logs are collected to analyze issues that occur while users enjoy AI content introduced by companies or to confirm that AI content are working in the way that is initially intended. During this process, privacy issues may be raised in case the information that may identify individuals is included. Therefore, NC is taking measures to remove personal identification information so that the user identification logs could never be registered and to make sure only the information required for verification of AI’s behaviors would be collected.
For instance, users may not find it so sensitive that the company collects the information on who plays ‘the Mirror War’ and how. However, users will not find the feeling that each of their moves is registered and monitored so pleasant. Therefore, removing personal identification information in user logs is not only important for personal information protection, but also for caring of our customers.
Establishment of the De-identification System
NC’s AI R&D organization is not only establishing internal procedures for data usage, but also establishing de-identification policies and setting up and applying information treatment systems. Also, it is making efforts to continuously improve policies, systems, and processes. All data that are disclosed by external parties and are collected internally and modified for technological purposes are within the scope of de-identification. For NLP research, text data are required, and it is more likely that adequate technologies are developed once more text data created by ordinary people are collected. Written languages including new articles are easy to come by, but spoken languages are not. Therefore, AI researchers tend to make efforts to collect less sophisticated utterances of ordinary people. Therefore, NC is de-identifying the data that used to be maintained internally without being de-identified.


In particular, in case a person becomes identifiable in the information, the information is more likely to be used for the purposes that were not initially intended. Users would believe that their personal information is leaked once their facial information is exposed. However, it is never easy to understand the importance of text data until an individual becomes identifiable in such text data. The data like bank account number and resident registration number are very much important, since once they are leaked, it may pose threat to one’s private assets or be used in crimes. At the moment, such important data are easily exposed to many third parties through chats and bulletin boards. NLP Center has striven to establish a system to handle person information through removing the data that implicitly expose personal information and leaving others that are required for AI learning.


In the case of websites and apps in operation like PAIGE, they should clearly state the information items that are being collected and how the company is separating, saving, and managing the collected information for how many years in accordance with the terms and conditions related to <Personal Information Handling Guideline> inclusive in the service policy. A few years ago, there were many cases where user information collected for provision of service was treated in a strict manner, while treatment of personal information for research was considered less important. However, since 2021, the public data that have recently become available have gone through de-identification of personal information. The de-identification process of personal information is as follows:
Data Security and Information Handling Training
NC is regularly carrying out trainings on how to handle data depending on their characteristics, how to redact names in data, how to prevent personal information leakage, and the matters requiring caution in information handling. To develop technologies to de-identify personal information, the terms that are considered as personal information should be tagged in learning data. In this case, personal information would be unintendedly exposed to multiple individuals, and therefore, NC has introduced various measures for safe data protection. First, all behaviors of the persons accessing data would be registered in log files through de-identification tools to prevent unlawful acts like leakages. Second, NC is training database developers on data security and information handling.
Moreover, NC is operating a security system to prevent illegal usage and leakage through having developers and researchers sign the “Security Protection Pledge for Individuals Handling Personal Information”. To apply technology to ordinary conversations, the data on such conversations should be reviewed, and to develop technology suited for game chats, actual game chats should be reviewed. Therefore, NC is making efforts to prevent abusive use of data and leakage of personal information through training of the persons responsible for data security and information handling. While it may be difficult to prevent all individual misconducts, such trainings give an alarm to data handlers to have the sense of ethical obligation. Also, the trainings may function as a minimum ethical guideline in treatment of data in the course of research.
Development of a System for Strict Treatment of Personal Information
Data are essential in development of better services and technologies. It is true the use of data is the zeitgeist of our times and AI learning and development would be impossible without data. In case there are 100,000 personal information among a million data, it will mean that the number of AI learning data would for AI developers and researchers will decrease. NC is actively researching technologies for automatic data treatment so that individual names would be redacted or replaced with other words and the rest of the data could be used for learning purposes.
Through establishing a system for strict treatment of personal information, the individuals accessing data would treat data with the sense of social responsibility and contribute to AI learning and development. Meanwhile, service users would not have to feel anxious about the possibility that their information would be leaked to other parties, endangering personal identity or assets. NC will develop a solid system for personal information protection and continuously review and improve to prevent ethical issues in the course of data collection and utilization for AI technology development and learning with the aim to create an environment where users could continue to use NC’s services with much ease of mind.
 Facebook
Facebook  Twitter
Twitter  Reddit
Reddit  LinkedIn
LinkedIn  Email
Email  Copy URL
Copy URL 



