Three papers from Speech AI Lab of NC AI Center were accepted at INTERSPEECH 2022, the most comprehensive conference on the science and technology of spoken language processing. NC has published its papers in Interspeech proceedings for three years in a row, proving its technological competitiveness.
We have explained the research culture of Speech AI Lab in the previous post (link). In this post, we will share the papers accepted by Interspeech 2022.
The three papers published in the proceedings cover applied research of singing AI and TTS model. In particular, please pay more attention to the various learning methods that they have attempted to try in an effort to make speech more natural. Also, we will disclose demo voices together with the research details. We hope you enjoy this opportunity to feel and experience AI voices that have become even more expressive than before.
“Adversarial Multi-Task Learning for Disentangling Timbre and Pitch in Singing Voice Synthesis” Interspeech 2022
We used to work in Singing Voice TF and started studying music-related AI in Music AI Team. The article about “N-Singer” published through 2021 Interspeech proceedings was research about voice synthesis model to improve the quality of lyric’s delivery. This year, we carried out research to improve naturalness in synthesis of singing voices. The previous models for singing voice synthesis were based on unsupervised learning to disentangle the timbre and pitch representations in mel-spectrograms. However, since they modeled the linguistic (lyric) and the note (MIDI) information separately without any explicit information about timbre and pitch, they could not express the natural timber that belonged to different levels of pitch. Therefore, we proposed the adversarial multi-task learning model in order to model the linguistics and the note information at the same time, while separating the timbre and pitch components.
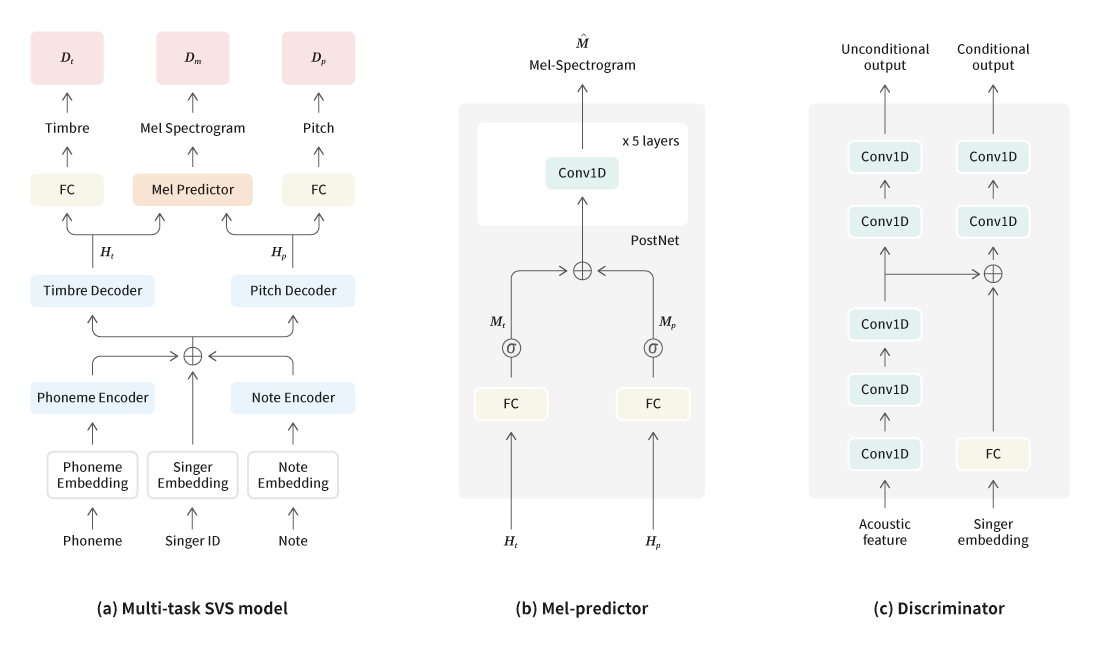
[Figure 1] Singing voice synthesis model structure based on adversarial multi-task learning
In the case of singing voice synthesis models, the audio characteristics are determined by vocoders that are used. The models may be divided into the ones using parametric vocoders and neural vocoders. In the case of parametric vocoders, there are limitations in audio reconfiguration, since information is lost during compression of audio characteristics. Meanwhile, neural vocoders may restore the mel-spectrograms into high-quality voices. However, they are not appropriate for separation of timber and pitch components. Therefore, the research developed a synthesis model that would learn both the audio characteristic in a parametric vocoder indicating timbre and pitch and the mel-spectrograms of a neural vocoder for separate modeling of timbre and pitch representations.
Also, the model improved the quality of synthesized audio based on more sophisticated estimation of individual timbre and pitch representations on Generative Adversarial Networks (GAN). Subsequently, the research succeeded to disentangle the timbre and pitch representations in mel-spectrograms for modeling purposes and could improve performance compared to existing singing voice synthesis (SVS) models.
Audio Sample 1
Sentence: 사라져가는 저 별빛 사이로 감출 순 없나요 커져버린 마음
(Pronunciation): salajyeoganeun jeo byeolbich sailo gamchul sun eobsnayo keojyeobeolin ma-eum
N-Singer + Parallel WaveGAN
AMTL-SVS + Parallel WaveGAN
Audio Sample 2
Sentence: 이제 다른 생각은 마요 깊이 숨을 쉬어봐요 그대로 내뱉어요
(Pronunciation): ije daleun saeng-gag-eun mayo gip-i sum-eul swieobwayo geudaelo naebaet-eoyo
N-Singer + Parallel WaveGAN
AMTL-SVS + Parallel WaveGAN
In the course of research, the researchers discovered that the estimation ability of mel-spectrograms were affected by the ability to estimate the timbre and pitch characteristics. To address this issue, the researchers improved the level of estimation through GAN learning of not only mel-spectrograms, but also the timbre and pitch characteristics that were auxiliary characteristics to improve the estimation ability of the mel-spectrograms as well. As a result, the researchers could synthesize the most natural singing voices and could create multiple singing voices through a single model.
“Enhancement of Pitch Controllability using Timbre-Preserving Pitch Augmentation in FastPitch”, Interspeech 2022
The Text-to-Speech (TTS) model is a voice synthesis model that generates the target speaker’s voice based on given text. Thanks to development of the end-to-end learning method in TTS model research, we are now able to generate natural voices that are difficult to be differentiated from those of actual human beings. The FastPitch model used in this research is specialized in adjustment of phoneme-level pitches. The data recorded for learning of TTS models are composed of voices that do not vary in style (since most of them are reading voices), and therefore, in the case of learning of FastPitch model, the synthesized voices created through pitch adjustment may show decline in audio quality, including inaccurate speech.
The most basic solution to this problem is to record additional voices that have even more diverse pitch information compared to existing TTS data, and therefore, it requires large extra costs and efforts. Therefore, the voice synthesis team reached a conclusion that they had to acquire data with diverse pitch information using the existing TTS training data without additional recordings. To this end, the researchers proposed introduction of VocGAN-PS, which was a way to shift pitches while preserving timbre of existing voices.
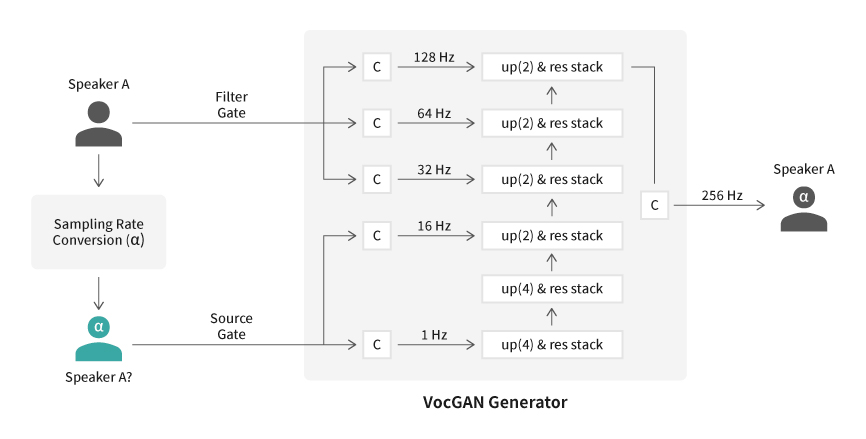
[Figure 2] VocGAN-PS method
The VocGAN-PS does not require an anticipation algorithm to acquire pitch and additional voice information. Also, it may generate high-quality pitch-augmented datasets that preserve the timbre of the original speaker’s voice. As a result, utilizing the collected data, the researchers could greatly improve the pitch adjustment capability and the quality of speech of FastPitch TTS model.
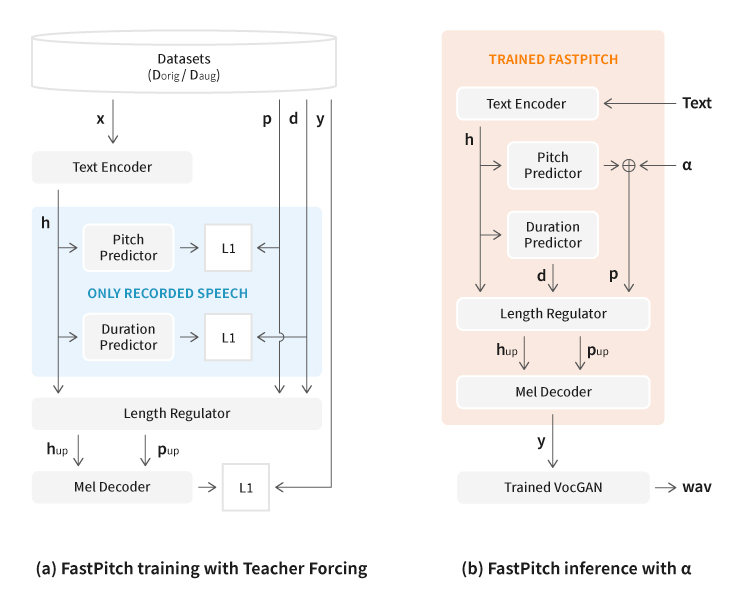
[Figure 3] Data preparation process
The following is the voices after shifting the original one by +3 semitone, using TD-PSOLA, WORLD vocoder, and VocGAN-PS suggested by the researchers. Both in quantitative and listening assessment, the performance of VocGAN-PS surpassed that of other algorithms; in particular, it received a higher score in the listening test to assess audio quality.
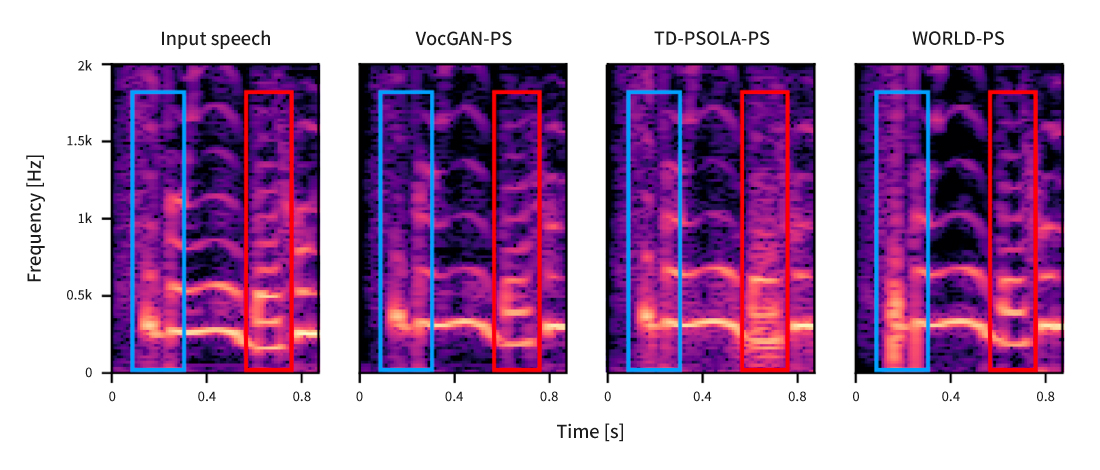
[Figure 4] The spectrograms of the voices after shifting of the original one by +3 semitone, using TD-PSOLA, WORLD vocoder, and VocGAN-PS
The research started based on the efforts to acquire data with varying pitch information using the existing training data of the TTS model. In the meantime, the researchers intuitively discovered the need to study and analyze how neural vocoders would create voices. Since then, the researchers could find clues to the voice creation principles of VocGAN through the research they started to understand the principles. As a result, they invented the VocGAN-PS algorithm and used the algorithm as the data to improve the TTS and the Voice Conversion model.
“Hierarchical and Multi-scale Variational Autoencoder for Diverse and Natural Speech Synthesis” Interspeech 2022
Jae-Sung Bae, Jinghyeok Yang, Tae-Jun Bak, Young-Sun Joo
Demo: https://nc-ai.github.io/speech/publications/himuv-tts/
While human beings may read the same sentence in many different ways, the TTS would generally read the given sentence based on average speech style. In order to improve such weakness, the researchers have continuously studied the solution to improve expressive ability of synthesized voices, since there was a need to greatly improve the naturalness and diversity of prosodies. Therefore, in this research, the researchers focused not only on improving naturalness of synthesized voices, but also on prosody modeling. HiMuV-TTS, a text-to-speech (TTS) model based on hierarchical and multi-scale variational autoencoder, was suggested through this paper to enable generation of synthesized voices with diverse prosodies.
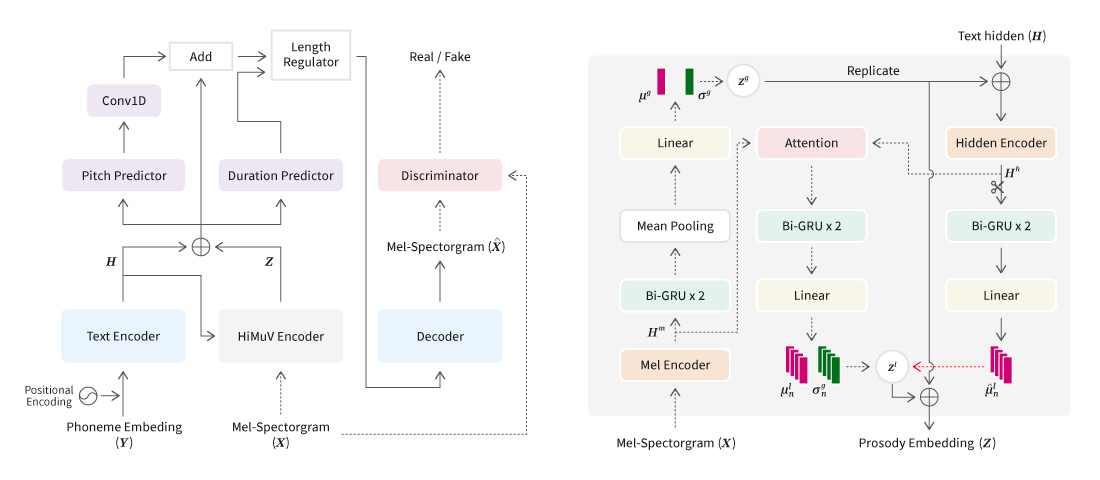
[Figure 5] HiMuV-TTS model and HiMuV-Encoder
To consider both the global-scale prosody and the local-scale prosody in a single sentence, the researchers created a vector (z_theta) to embed overall prosody of the input sentence (the one to be synthesized). Then, they registered the vector embedding overall prosody (z_theta) and the one embedding text (H) as conditions to generate the vector to embed the local-scale prosody in the sentence (Z_l). Also, to improve the quality of synthesized voices, they applied the adversarial training method introduced through the paper (J. Yang, J.-S. Bae, T. Bak, Y.-I. Kim, and H.-Y. Cho, “GANSpeech: Adversarial training for high-fidelity multi-speaker speech synthesis,” in Proc. Interspeech 2021. Link) published in 2021 Interspeech proceedings.
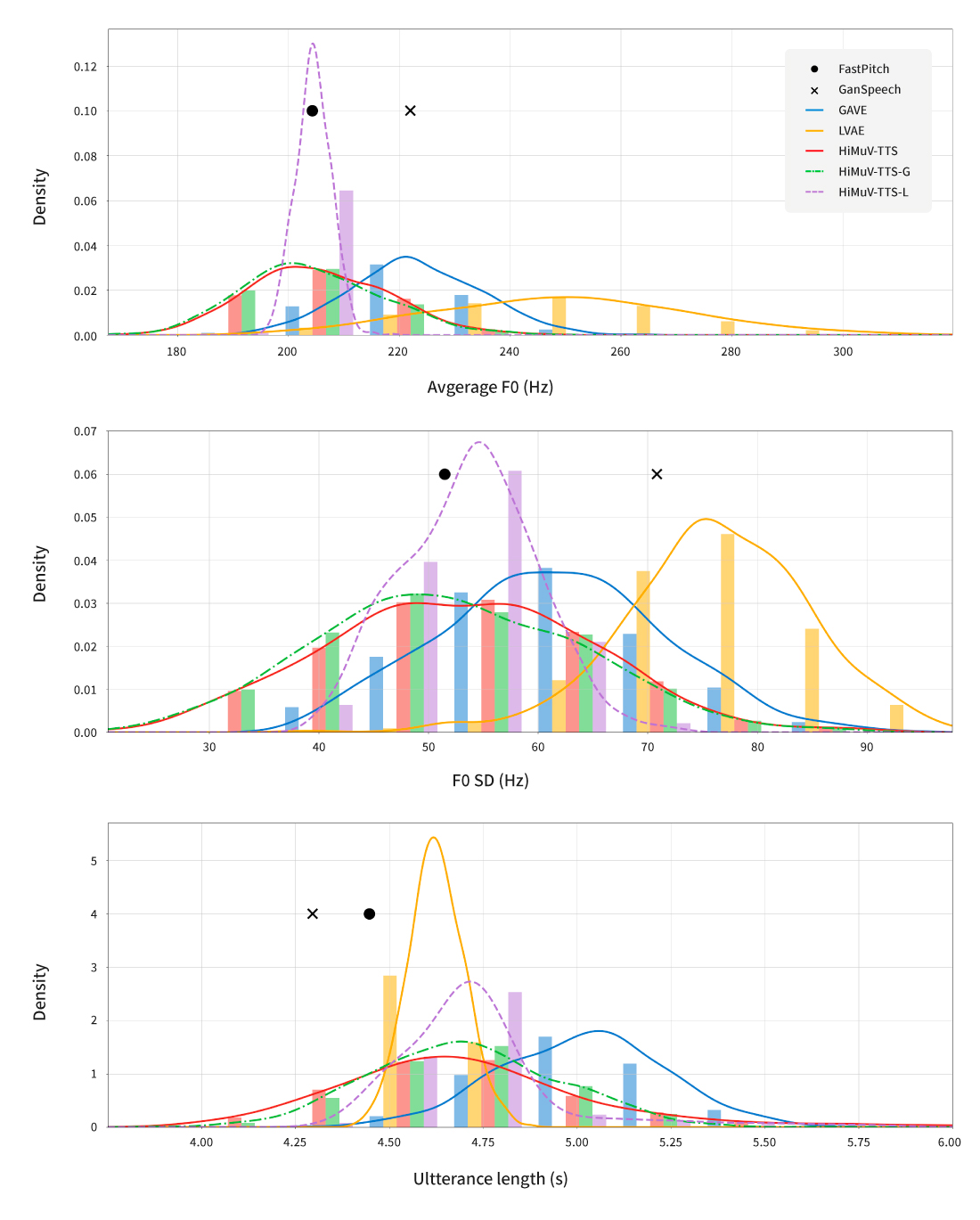
[Figure 6] The distribution of synthesized voice pitches (#1,2) and sentence length (#3) of HiMuV-TTS and various synthesis models: the graph confirms that HiMuV-TTS may generate synthesized voices, reflecting diverse expressions of actual human beings.
Audio Sample 4: Comparison of voice samples between FastPitch, GVAE, LVAE, and HiMuV-TTS
Text: In another portion of the garden more clothing partly male and partly female was discovered.
Audio Sample 5: Voice samples of diverse speech styles created through sampling of the HiMuV-TTS model
Text: They entered a stone cold room and were presently joined by the prisoner.
Through this research, it was confirmed that the model may generate more natural, effective, and diverse prosodies, reading speeds, and pauses using the same sentence compared to existing models. However, there is a need for more in-depth analysis and additional research to enable actual users to adjust various prosody elements and to easily create the voices they want. The research project has opened up the possibility to help actual users to create diverse voices in the way they want.
Challenge to provide synthesized voices that are more human than those of actual human beings
Even at this moment, Speech AI Lab continues to make new attempts. NC will not become complacent with the existing AI technology and will create its own competitive voice AI technologies through addressing weaknesses and converging with various areas like music beyond the boundary of AI voice synthesis technology. Also, since AI voice synthesis is one of the essential technologies to develop digital human beings, which are the target of NC AI for the next generation, NC is developing diverse and differentiated technologies. The current target is to develop a high-quality voice AI technology that not only speaks in diverse languages, but also could express its emotion to imply situation in the voice and the speech style, adopt diverse and distinctive voices, and freely control all the aforementioned voice elements. NC will continue to make challenges to introduce a digital human that could ultimately exchange emotions and communicate with people.
 Facebook
Facebook  Twitter
Twitter  Reddit
Reddit  LinkedIn
LinkedIn  Email
Email  Copy URL
Copy URL