 Facebook
Facebook  KakaoTalk
KakaoTalk  LinkedIn
LinkedIn  Email
Email  Copy URL
Copy URL 게임 AI에 대한 R&D 연구를 선도해오고 있는 엔씨소프트.
엔씨소프트는 AI Center 내 Speech Lab을 설립, 전문 연구진들이 모여 음성 기술에 대한 연구 개발을 활발히 진행하고 있는데요.
‘게임과 AI’ 4편에서는 최근 주목 받고 있는 게임 속 음성 기술에 대해 살펴보고, 엔씨소프트Speech Lab의 구체적인 연구 내용과 목표를 소개하겠습니다.
게임 AI에 대한 R&D 연구를 선도해오고 있는 엔씨소프트.
엔씨소프트는 AI Center 내 Speech Lab을 설립, 전문 연구진들이 모여 음성 기술에 대한 연구 개발을 활발히 진행하고 있는데요.
‘게임과 AI’ 4편에서는 최근 주목 받고 있는 게임 속 음성 기술에 대해 살펴보고, 엔씨소프트Speech Lab의 구체적인 연구 내용과 목표를 소개하겠습니다.

인공지능(AI) 스피커의 춘추전국시대가 펼쳐지고 있습니다. 이제 음성으로 기계와 대화하는 게 자연스러운 현상으로 자리 잡고 있습니다.
덕분에 AI 하면 곧바로 음성 인식이나 음성 합성을 떠올릴 정도로 음성 기술이 우리 곁에 바짝 다가왔습니다.
음성 기술은 AI가 일상 속에 매끄럽게 녹아들게 하는 필수 기술이기도 합니다. 그래서 AI를 다루는 많은 기업에서는 대부분 음성 기술을 연구하는 조직을 두고 활발히 연구 개발을 진행하고 있습니다.
물론 엔씨소프트의 AI Center에도 Speech Lab이라는 음성 기술 연구 조직이 있습니다. 이번 원고를 통해 저희의 연구 내용과 목표를 소개하고, AI 시대에 필요한 음성 기술은 무엇이며 어디에 어떻게 적용할 수 있는지 살펴보겠습니다.
AI의 궁극적 목표는 무엇일까요? 바로 인간을 닮은 기계를 만드는 것입니다.
음성은 인간의 가장 기본적인 커뮤니케이션 수단입니다. 인간을 다른 동물과 구분할 수 있는 중요한 특징이기도 합니다.
인간의 말을 알아듣고 인간의 말로 반응을 보이는 행위는 AI에게 가장 필수적인 능력일 수밖에 없습니다. 그래서 인간과 기계를 연결하는 음성 기술이 AI 분야에서 주목 받을 수 밖에 없습니다.
인터페이스 도구로서 음성은 여러 장점이 있습니다.
과일을 깎거나 TV 리모컨을 조작하면서도 동시에 상대방과 메시지를 교환할 수 있습니다. 키보드와 마우스를 사용하는 것과 달리 먼 거리에 있어도 로봇이나 인공지능 스피커에 명령을 내릴 수도 있습니다. 어조나 어투, 음량 등의 변화를 통해 단순한 정보 전달이 아닌 감정 전달까지 할 수 있습니다.
이러한 특징 때문에 AI 분야에서는 음성 인터페이스가 가장 기본적인 요소로 자리 잡고 있으며 이를 다루는 음성 기술이 더욱 각광받고 있습니다.

음성 기술의 응용 분야
입술 바로 앞에 공기의 떨림을 감지할 수 있는 진동판을 두고 기록하면 다음 그림과 같은 음성 파형(speech waveform) 그래프를 얻게 됩니다.
음성 파형을 단순하게 보면 1차원 정숫값의 나열에 불과하지만, 파형 신호 속에는 언어 정보, 연령 정보, 감정 정보, 성별 정보 등 다양한 정보가 포함돼 있습니다.

음성 파형과 그 안에 포함된 여러 정보
음성 기술은 이러한 음성 파형을 기계가 스스로 분석해 다양한 정보를 찾아내거나, 거꾸로 텍스트와 같은 다른 형태의 커뮤니케이션 데이터를 가지고 다양한 정보가 담긴 음성 파형으로 합성하는 기술을 모두 포함하는 기술입니다.
음성 기술은 크게 음성 인식(speech recognition), 음성 합성(speech synthesis), 음성 코딩(speech coding), 음성 개선(speech enhancement) 등 크게 네 분야로 나눌 수 있습니다.
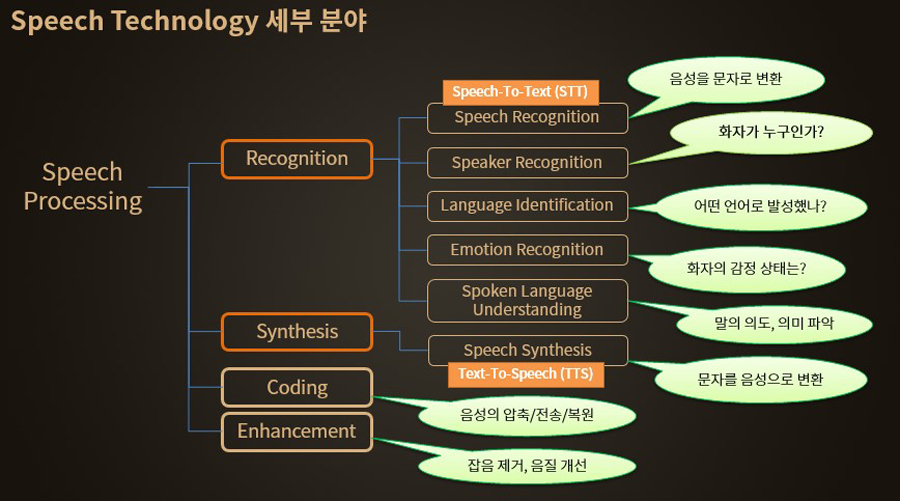
음성 기술의 주요 연구 분야
음성 인식 기술은 또 몇 가지 세부 영역으로 나뉩니다.
△음성 인식(speech-to-text, STT)은 음성 신호에서 텍스트 정보를 추출합니다. △화자 인식(speaker recognition)은 발성한 사람이 누구인지 식별합니다. △감정 인식(emotion recognition)은 화자의 감정 상태를 맞춥니다. △언어 식별(language identification)은 어떤 언어로 말했는지 판단합니다. △음성언어 이해(spoken language understanding, SLU)는 음성에 포함된 화자의 궁극적인 의도나 말의 의미를 이해합니다.
음성 인식과 반대로 주어진 텍스트 문자열로부터 음성 신호를 자동으로 생성하는 기술이 있는데, 그것이 바로 음성 합성 기술입니다. 운전 중 최신 텍스트 뉴스를 음성으로 자동 전환해 읽어준다거나 특정 인물의 억양, 감정 상태 등을 담은 음성을 만들어 내는 예들이 모두 음성 합성 영역입니다.
음성 코딩은 음성 신호를 보다 효율적으로 압축하거나 원거리 전송 후에 다시 복원하는 기술입니다. 압축은 원본의 10분 1 수준으로 이뤄집니다. <리니지>와 같은 MMORPG에서 여러 명의 사용자가 하는 음성 채팅에도 바로 이 기술이 적용돼 있습니다.
음성 개선은 잡음이 섞이거나 왜곡이 발생한 음성 신호를 원래의 신호로 복원하는 분야입니다. 음성 개선을 위해서 하나의 마이크를 사용해 잡음을 제거하거나 여러 개의 마이크를 사용한 마이크 어레이(microphone array)를 구성해 사용합니다. 마이크 어레이 기술 역시 몇 가지로 나뉩니다.
목표로 한 음성의 방향을 탐지하는 방향 탐지(source localization), 특정 방향의 소리만을 강화하는 빔포밍(beamforming), 여러 소리가 뒤섞인 상황에서 각각의 소리를 분리하는 음원 분리(source separation), 심한 울림이 있는 공간에서 반향 효과를 제거하는 반향음 제거(dereverberation) 등이 음성 개선을 구성하는 기술입니다.
음성 개선 기술은 음성 인식의 전처리 단계에서 흔히 사용됩니다. 예를 들어 먼 거리에서 음성으로 AI 스피커에 명령을 내릴 때 인식 정도를 향상하려면 반드시 필요합니다.

다양한 분야에서 활용되는 음성 인식 기술
게임 역시 음성 기술이 활발하게 적용되는 분야입니다. 특히 MMORPG가 모바일로 넘어오면서 음성 인식 기술의 중요성은 더욱 커지고 있습니다. 바로 게이머 간의 빈번한 채팅 때문입니다.
MMORPG를 하다 보면 게이머끼리 커뮤니케이션이 굉장히 자주 필요합니다. 바쁘게 진행되는 게임 도중 작은 스마트폰의 가상 키보드로 일일이 메시지를 입력한다는 건 굉장히 불편하고 어렵습니다. 좁은 공간에서 타이핑을 하다 보니 오타도 많이 나올 수 밖에 없습니다. 게임을 하며 음성으로 메시지를 입력하고 들을 수 있다면 이런 문제는 쉽게 풀릴 수 있습니다.
모바일 MMORPG에서 채팅은 보통 한 명이 말을 하고 다수의 혈맹원이 동시에 청취하는 일이 비일비재합니다. 일대일 통신뿐만 아니라 일대다 통신도 원활하게 지원해야 합니다.
전체 게임을 놓고 보자면 수십만 명이 동시에 이 기능을 사용하므로 대규모 음성 전송이 일어나는 상황에서도 효율적으로 단위 데이터(패킷)를 전송하고 안정적으로 서비스 할 수 있어야 합니다. 그뿐만 아니라 게임 자체에서 발생하는 사운드와 음악, 마이크를 통해 입력되는 외부 잡음까지 목소리와 분리해 음성의 명료도를 높이는 작업도 필요합니다.
이처럼 게임에서 음성 기술은 여러 차원의 문제를 동시다발적으로 풀어내는 일을 처리하고 있습니다.
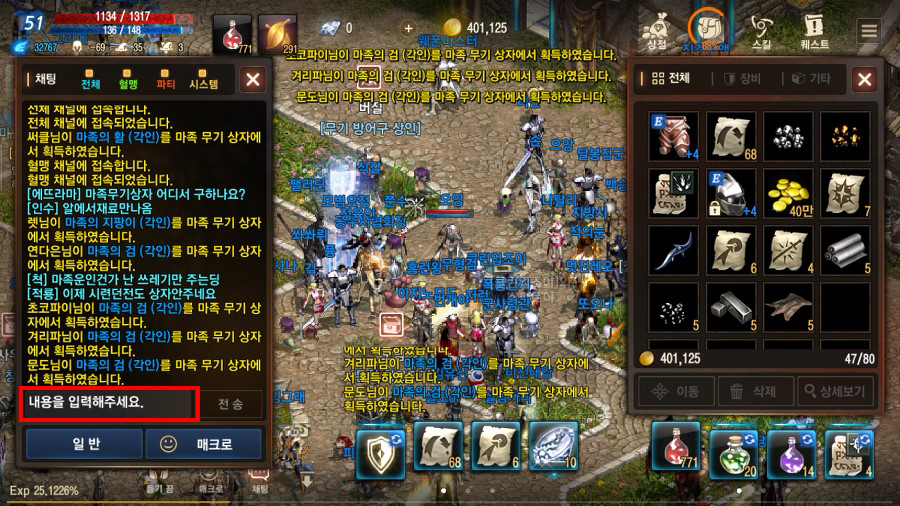
모바일 MMORPG에서 텍스트 채팅을 하는 모습
음성 채팅뿐만 아니라 게임에 필요한 명령 자체도 화면 터치와 함께 음성으로 하는 방법도 활발히 개발 중입니다. 아직 음성 인식 정도가 완벽하지 않은 만큼 정확도에 민감하지 않은 명령어에 적합합니다.
외국 게임 중 <인 버비스 버투스(In Verbis Virtus)>가 대표적인 사례입니다. 이 게임에서는 영화 해리포터 시리즈에 나오는 마법 용어와 유사한 명령어를 음성으로 내려 임무를 수행하는 형식을 취하고 있습니다.
뿐만 아니라 가상현실(VR)이나 증강현실(AR) 기반 게임에도 음성 기술을 효과적으로 적용할 수 있습니다.
VR·AR 게임에서 중요한 도구인 헤드 마운트 디스플레이(HMD)를 쓴 상태에서 명령어를 내릴 수 있는 수단으로 음성이 가장 편리하기 때문입니다. 유비소프트와 같은 게임 개발사는 IBM과 공동으로 음성 인식으로 구동하는 VR 게임 <스타트랙: 브릿지 크루(Star Track: Bridge Crew>를 개발하고 있기도 합니다.
음성 인식뿐만 아니라 음성 합성도 게임에 적절하게 이용할 수 있습니다.
게임 속에는 수많은 캐릭터, 특히 NPC와 몬스터들이 존재합니다. 이들이 지닌 게임적 특성과 성격에 따라 목소리가 제각각인데, 기존에는 이를 모두 성우들이 엄청난 시간과 비용을 들여 직접 녹음하는 방식으로 만들었습니다.
만일 텍스트를 원하는 형태의 음성으로 생성할 수 있다면, 시간뿐만 아니라 비용 면에서도 크게 절약할 수 있습니다. 음성 합성 기술 중 하나인 음성 변환(voice conversion)이나 변조 기술을 이용하면 성우가 낸 하나의 음성 발화 데이터를 다양한 음색으로 변환시켜 적절한 음질을 유지하면서도 다양한 캐릭터 목소리를 만들어 낼 수도 있습니다.
물론 성우가 녹음한 수준까지 가기 위해서는 아직 갈 길이 멀기에 이 분야는 더 도전할 부분도 많이 남아 있습니다.

캐릭터들의 개성에 따라 목소리 역시 다르게 표현되어야
게임 자체뿐만 아니라 게임 개발 자원을 효율적으로 관리하는 데도 음성 기술을 활용할 수 있습니다.
게임을 개발하다 보면 엄청난 분량의 음성 데이터∙텍스트 데이터 쌍이 쌓이게 됩니다. 용량이 커지면 커질수록 음성 신호의 특정 구간이 어떤 어휘에 해당하는지, 발성한 언어의 종류가 무엇이고 어떤 감정 상태인지 설명할 수 있는 메타 데이터가 필수적입니다. 이러한 메타 데이터를 자동으로 생성하고 관리할 수 있다면 게임 개발 과정의 효율성을 극대화할 수 있습니다.
엔씨소프트 AI Center에도 Speech Lab이라는 음성 기술 연구 개발 조직이 있습니다. Speech Lab은 국내외 기업, 정부출연연구소에서 오랜 기간 음성 기술을 연구하던 전문가들과 각 대학 주요 음성연구실 석박사 전공자들로 구성돼 있습니다. 이들은 '음성인식팀'과 '음성합성팀'으로 나뉘어 서로의 전문 분야에서 흥미로운 연구를 활발히 진행하고 있습니다.
게임회사 내 조직이다 보니 게임에만 집중할 것 같지만, Speech Lab의 연구 개발 방향은 음성 기술이 적용될 수 있는 곳이라면 어디든 가리지 않습니다. Speech Lab은 ①사용자가 누구인지 알아보고 ②말의 내용과 감정을 인식하며 ③자연스럽고 다양한 톤의 음성으로 응답하고 ④사용자 주변 음향 환경을 이해한다는 4대 연구 과제를 바탕으로 오늘도 연구 개발에 매진하고 있습니다.

엔씨소프트 AI Center Speech Lab의 주요 연구 과제
지금까지 AI 시대의 음성 기술이란 무엇인가 알아보고 우리에게 익숙한 게임에 적용된 사례를 살펴봤습니다.
다음 편에서는 AI에서 꼭 필요한 음성 기술 중 하나인 '음성 합성 기술(text-to-speech)'에 대해 더욱 구체적으로 살펴보도록 하겠습니다.

조훈영
RELATED


