엔씨소프트는 AI센터 내 스피치(Speech)랩을 설립, 전문 연구진들이 모여 음성 기술에 대한 연구 개발을 활발히 진행하고 있는데요.
‘게임과 AI’ 6편에서는 AI에서 꼭 필요한 음성 기술 중 하나인 음성 인식(Speech Recognition) 기술의 큰 흐름을 핵심적인 원리와 함께 살펴보겠습니다.
또한, 스피치랩에서 진행하고 있거나 관심을 두고 있는 연구 주제들은 무엇인지 소개하며 앞으로 펼쳐질 음성 인식의 미래는 어떤 모습일지 함께 생각해보겠습니다.
음성 인식 기술
좁은 의미의 음성 인식은 일반적으로 세 가지 과정을 의미합니다.
①공기(채널)를 통해 전송된 음성을 마이크와 같은 소리 센서로 얻고 ②그 신호를 채널(회로, 전화, 유무선데이터)로 전송해 음향학적 신호를 획득한 후 ③단어나 단어열 혹은 문장으로 변환하는 과정입니다.
음향학적 신호(Acoustic Speech Signal)에는 문서(text) 정보 외에도 언어, 국적, 감정, 화자, 주변상황(잡음, 반향), 환경, 출신지, 성별, 나이, 전송된 채널 등 다양한 추가 정보가 포함돼 있습니다.
넓은 의미의 음성 인식은, 앞서 설명한 좁은 의미의 음성 인식 성능을 향상시키는 것과 위에서 언급한 언어, 감정, 화자와 같은 추가 정보 추출 기술을 모두 포함합니다.
음성 인식기는 입력 음성을 받아 적은 텍스트를 결과물로 내놓습니다. 결과물에는 감정, 주변 환경 등의 추가 정보도 포함됩니다.
그렇다면 이 텍스트를 어떻게 사용할 수 있을까요? 저장하거나, 음성 이해를 위한 언어처리의 입력 데이터로 사용합니다.
음성 안에는 이런 많은 정보가 들어 있습니다
일반인들은 대체로 ‘음성 인식’을 ‘음성 이해’와 동일하게 생각합니다. 하지만, 엄밀히 말하면 다릅니다.
쉽게 설명하자면 음성 인식은 받아쓰기에 해당합니다. 음성 이해는 받아쓰기를 넘어 음성이 지닌 뜻까지 파악하는 수준을 의미합니다. 뜻을 알아야 그에 맞는 대답이나 행동을 할 수 있겠죠.
이해를 돕기 위해 익숙한 예를 들어 설명해 볼까요? 넓은 의미의 음성 인식은 좁은 의미의 음성 인식도 포함한다는 것을 꼭 염두에 두고 읽어주세요.
음성 파형(신호)과 그 안에 포함된 여러 정보
광고에서의 음성 인식 기술
IMF 한파가 엄습하던 1997년, 배우 안성기 씨가 몸을 던지며 열연했던 휴대전화 ‘애니콜’ TV 광고가 큰 인기를 얻었었는데요.
광고 속에서 안성기 씨가 달리는 기차 위에서 악당과 몸싸움을 벌이던 중 휴대전화를 떨어뜨리자 플립(Flip; 폴더폰과는 다릅니다)이 열리는 장면이 나옵니다.
그러자 휴대전화에서 “이름을 말하세요.”라는 안내음성이 나옵니다. 안성기 씨가 다급히 “본부! 본부!”라고 외치자 휴대전화는 친절히 전화를 걸어 본부를 연결해 줍니다. “즉시 출동 바람!”
안성기 씨는 본부가 보내준 헬리콥터에서 내려준 줄사다리를 타고 “이젠 말로 거세요.” 한 마디를 남긴 채 유유히 사라집니다.
추억의 애니콜 광고
이제는 역사 속으로 사라진 브랜드 ‘애니콜’이지만, 이 광고에는 우리가 이야기하려는 음성 인식에 대한 고민이 녹아있습니다. 현재 흔히 사용되는 음성 인식 기술과 여러 연관 기술을 누구나 이해할 수 있게 직관적으로 보여주기도 했습니다. 물론 지금은 당시보다 음성 인식 기술이 훨씬 더 진보한 상태입니다.
자 그럼, 이제부터 애니콜 광고 속에 숨어 있는 음성 인식 기술을 자세하게 나눠 그 발달 과정과 함께 살펴보겠습니다.
“본부! 본부!”란 음성은 어떻게 인식했을까?
안성기 씨가 “본부! 본부!”라고 외친 뒤 휴대전화가 본부를 연결해 줄 때 가장 중요한 기술이 바로 ‘음성 인식’ 기술입니다. 휴대전화의 음성 인식 시스템이 화자의 음성에서 단어를 인식하고 주소록에서 ‘본부’를 찾아 전화를 걸어준 것입니다.
이러한 상황에서 음성을 인식하는 방법은 크게 두 가지입니다.
‘고립단어인식’과 ‘연속음성인식’인데요. 고립단어인식은 하나의 독립된 단어를 인식하고 연속음성인식은 화자의 발성 방식을 인식합니다. 화자가 즉흥적인 말을 하거나, 심지어 말을 더듬어도 인식할 수 있습니다.
여러 환경을 고려했을 때, 광고 속 상황에서는 고립단어인식 기술을 적용했을 가능성이 높습니다. 안성기 씨가 외친 “본부!”는 하나의 독립된 단어이기 때문입니다. 만약, “음, 본부에 연결해.”라고 말한다면 연속음성인식 기술이 필요했겠죠.
음성 인식의 든든한 지원군, 딥러닝
음성 인식 기술은 1950년대까지 거슬러 올라갈 정도로 역사가 오래됐습니다.
초창기 음성 인식은 신호처리 후 미리 정의한 규칙(템플릿)에 따라 처리했습니다. 사람의 다양한 표현을 각각의 규칙으로 정하는 것은 불가능에 가깝습니다. 그래서 이 당시 음성 인식 기술은 성능이 낮을 수밖에 없었습니다. 무엇보다 이런 작업을 제한된 시간 내에 할 수 있는 컴퓨터도 계산기 수준밖에 안되었으니, 현재와 비교했을 때 많이 열악했습니다.
음성 인식 기술은 통계적 방법을 만나 한 단계 발전을 이룹니다. 이 방법은 신호의 고유 특징을 수학적으로 해석한 뒤 통계적 수치에 기반해 처리합니다. CPU 혹은 DSP(Digital Signal Processing) 칩의 성능 향상 덕분에 실용적으로 사용 가능해졌습니다. 다른 분야에서도 종종 사용되는 HMM(hidden Markov Model: 은닉 마르코프 모델; 음성 인식, 자연어 처리, 몸짓 인식 등과 같이 대량으로 출력된 데이터의 패턴을 통계적 방법으로 분석)이 대표적인 방법입니다.
현재 음성 인식의 대세는 AI 기술 중 하나인 딥러닝(deep learning)입니다.
딥러닝은 방대한 규모의 연산이 필수인데, 이를 뒷받침할 수 있는 고속 연산 장치와 대용량 메모리가 필요합니다. 기술 발전 덕분에 관련 시스템 비용이 낮아져 딥러닝 기술에 대한 접근성이 좋아졌습니다. 물론, 과거보다 더 많은 데이터를 쉽게 얻을 수 있다는 점도 딥러닝 기술을 활발히 쓰는 이유 중 하나입니다.
AI 기술을 비약적으로 발전시킨 딥러닝
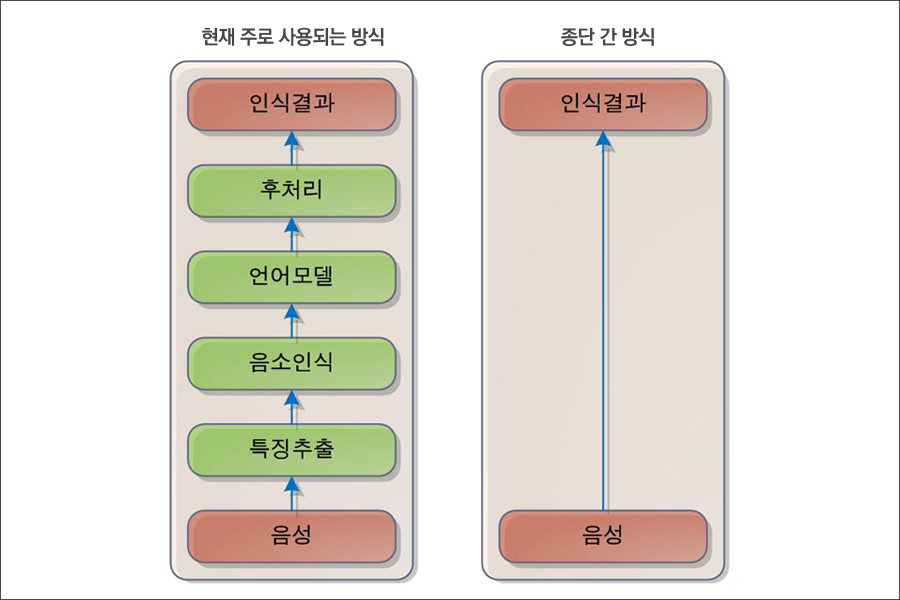
일반적으로 음성 인식은 다섯 단계를 거칩니다.
①음성을 획득한 후 ②고유의 특징을 추출해 ③음소를 인식하고 ④음소 순서에 가장 적합한 단어를 언어모델의 도움으로 찾아 ⑤몇 가지 처리과정을 거쳐 단어 혹은 최종 문장으로 인식한 결과를 얻습니다.
과거에는 통계와 수학 계산을 통해 전체 과정을 진행했으나, 이제는 각 단계별로 딥러닝을 이용할 수 있게 됐습니다. 특히 ‘음소 인식’에서는 통계적 방법보다 딥러닝 기법을 더 많이 사용하기도 합니다.
현재 주로 사용되는 음성 인식 방식(왼쪽)과 종단 간 방식(end-to-end)
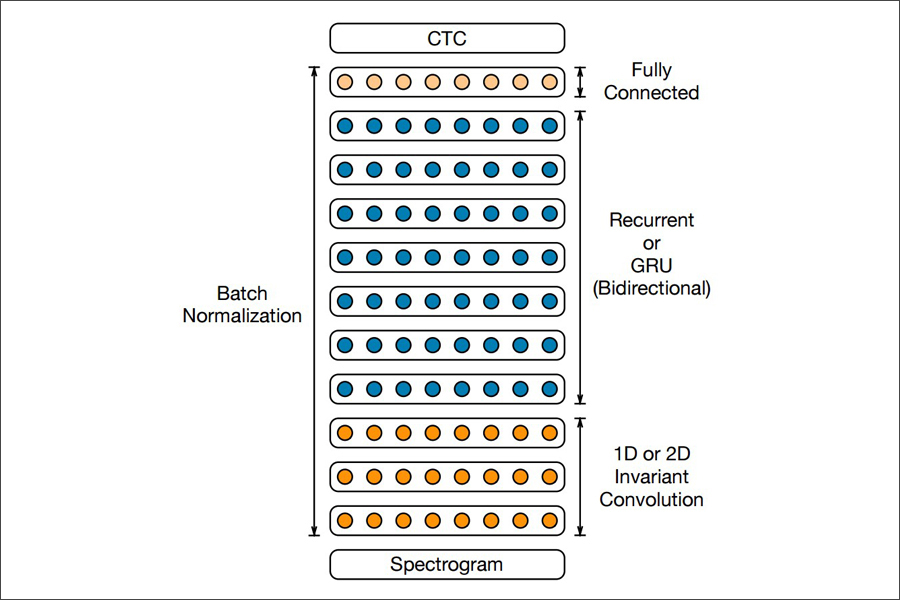
최근 구글이나 바이두 등 글로벌 기업은 앞서 설명한 음성 인식 과정 전체를 딥러닝으로 통합 처리하는 연구를 진행 중입니다. 이런 방법을 ‘종단 간 방식(end-to-end)’이라고 하는데, 사람처럼 음성을 듣고 곧장 단어와 문장으로 인식하는 방식입니다.
물론 단계적으로 처리하는 방법에 비해 더 많은 데이터와 연산이 필요하다는 난점이 있지만, 단계마다 필요한 준비 작업을 생략하고 시스템을 하나로 통합해 복잡도를 낮출 수 있어 앞으로 대세로 자리잡기 않을까 예상합니다. 딥러닝 기법의 발전도 여기에 중요하게 작용하겠죠.
바이두의 종단 간 방식(end-to-end)방식 딥 스피치 2(Deep Speech 2)
빠르게 달리는 기차에서 음성을 정확히 인식하려면 - 잡음 제거 및 원거리 인식 기술
다시 광고 이야기로 돌아가 볼까요?
안성기 씨가 악당과 몸싸움을 하다가 휴대전화를 떨어뜨린 공간은 빠르게 달리는 기차의 지붕입니다. 당연히 엄청나게 센 바람이 불겠죠. 잡음이 심할 수 밖에 없는 조건이죠. 그나마 다행인 건 사방이 뻥 뚫린 공간이라는 점입니다.
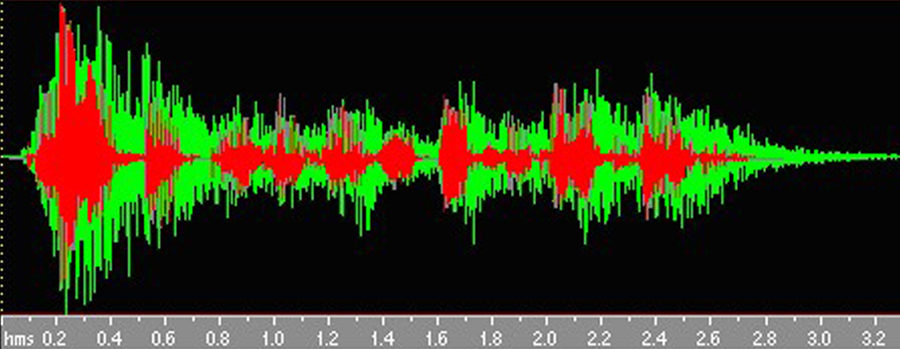
실내였다면 쉽지 않았을지도 모릅니다. 실내에서는 휴대전화와 2~3m만 떨어져 있어도 신호의 왜곡이 심하게 일어날 수 있기 때문입니다. 마이크에 들어오는 신호에는 입에서 곧장 마이크로 입력되는 음성 신호 이외에도, 사방의 벽과 천장에 반사된 후 들어오는 음성 신호들(반향)도 있기 때문입니다. 여러 벽에 반사되어 들어오기에 모두 다른 시간차로 입력되고 따라서 소리가 울리게 됩니다. 이런 반향음(reverberation)도 역시 잡음입니다.
이렇게 되면 신호대잡음비(SNR: Signal-to-Noise Ration)가 낮아져 음성 인식 자체가 불가능에 가깝게 될 수도 있습니다. 이런 문제는 수많은 음성 인식 개발자들이 밤잠을 설치게 하는 아주 골칫덩어리 중 하나죠.
반향음이 섞인 녹색 음성에서 원래 음성(빨간색)만을 뽑아내야 합니다
이를 해소하기 위해 음성 인식 전문가들은 다양한 기법을 연구했는데요. 잡음 제거 및 원거리 인식 기술이 여기에 해당합니다.
이 기술을 구현하기 위해서는 통계적인 처리 방법이 여전히 우세하지만, 최근에는 딥러닝도 사용됩니다. 딥러닝을 통해, 음성의 고유 특징을 추출 단계나 음소 인식 단계에서부터 고려해야 할 요소로 통합해 좀 더 정확한 음성 인식을 구현합니다.
음성보다 빠르게 상황을 인식하는 라이프 로깅(Life Logging) 기술
안성기 씨가 악당과 몸싸움을 하고 있다는 상황 자체를 인식하는 방법은 없을까요?
아마도 광고 속에서 안성기 씨는 분노에 찬 목소리로 거친 숨을 몰아쉬었을 것입니다. 바람 소리 같은 주변 환경도 다르겠죠. 이 역시 음성 및 음향신호에 포함돼 있는 정보입니다.
누군가가 안성기 씨의 직업(특수요원)과 벌어지는 상황을 안다면 ‘지금 몸싸움을 벌이는 위급한 상황’이라는 걸 인식할 가능성이 높습니다. 정황을 알 수 있는 정보가 주어진다면 더 명확히 음성을 인식할 수 있습니다. 우리가 감탄과 함께 말한 “예쁘다”와 실망스러운 어조로 말한 “예쁘다”를 서로 정반대의 의미로 해석할 수 있는 것처럼요.
음성 인식 시스템 역시 화자의 상황을 인식할 수 있습니다. 라이프 로깅(Life Logging) 기술이 대표적인데요.
화자에게 발생하는 일상을 계속 지켜보면서(들으면서) 중요한 사건(event)을 저장한 뒤 이에 맞게 대처합니다. 화자를 지켜보는 친구가 항상 붙어 다니는 것입니다.
가령, 길거리에서 “배고프다”고 할 때는 가까운 음식점을 추천하겠지만 음식점에서 “배고프다”고 하면 그 음식점의 메뉴를 추천하는 방식입니다. 라이프 로깅 기술을 적절하게 적용한다면 “본부에 전화 걸어!”, “즉시 지원 바람!” 혹은 “본부!”라고 외치지 않아도 현재 상황을 명확히 전달할 수 있습니다.
라이프 로깅 기술을 실현시키는 음성 인식 기술
휴대전화를 열지 않고도 상황을 전달할 수 있다면 - 핵심어 검출 기술
안성기 씨가 악당과 몸싸움을 하다가 휴대전화를 떨어뜨리는 장면에는 중요한 사실이 하나 더 있습니다. 휴대전화가 떨어지면서 플립이 열린 뒤 음성 인식을 할 준비 상태가 되죠.
여담이지만 현실은 달랐습니다. 당시 저는 광고 속에서 안성기 씨가 썼던 바로 그 휴대전화를 사용했는데, 떨어뜨릴 때마다 배터리가 분리되면서 전화기가 꺼졌습니다. 그래서 고객센터에 문의하니 “고가의 휴대전화를 충격으로부터 보호하기 위해 본체와 배터리를 일부러 분리되게 설계했다.”는 답이 돌아왔습니다.
광고와 달리 ‘본부’에 전화 걸기 위해서는 휴대전화를 절대로 떨어뜨리면 안된다는 의미입니다. 휴대전화를 떨어뜨려서도 안되고, 플립조차 열 수 없는 상황이라면 어떻게 해야 할까요?
다행히 방법이 있습니다. 바로 핵심어 검출(Keyword-spotting, Wake-up) 기술을 적용하면 됩니다.
핵심어 검출은 사람들의 일상적인 언어 생활 가운데 미리 정의한 ‘핵심어’만 골라 인식하는 기술입니다. 미리 정의한 단어를 사용해 음성 인식 시스템 전체를 깨우거나(wake-up), 대화 중에서 중요한 몇몇 단어를 인식(keyword-spotting)하는 게 이 기술에 해당합니다.
요즘 출시되는 휴대전화나 인공지능(AI) 스피커를 사용하려면 “오케이 구글(Ok google)”, “시리(Siri)야”, “알렉사(Alexa)”, “아리아” 등과 같은 단어를 먼저 말하는 게 대표적인 예입니다.
이렇게 미리 정의해 놓은 핵심 단어를 발음하면, 장치의 지시등 혹은 화면이 켜지고 다음 명령을 위해 전체 시스템을 잠에서 깨워 준비 상태로 전환합니다. 당연히 시스템은 음성을 항상 듣고(Always Listening) 있어야겠죠.
구글홈(Google Home)과 아마존 에코(Amazon Echo)가 서로의 이름을 애타게 부릅니다
아마도 지금 다시 광고를 제작한다면, 휴대전화를 떨어뜨리기 전 미리 “애니콜!”이라며 불러 깨운 후 ‘본부’를 말해 전화를 걸지 않았을까 예상합니다.
악당이 내 휴대전화에 명령하지 못하도록 - 화자 인식 기술
광고를 보면 안성기 씨가 악당과 싸우는 도중 휴대전화가 깨어나 “이름을 말하세요.”라며 음성안내를 합니다.
그런데 말입니다. 이 때 몸싸움을 벌이던 악당이 먼저 “우리집”이라고 말해 안성기씨의 집으로 전화를 연결하면 어떻게 될까요? 참으로 난감한 상황이 펼쳐지겠죠.
본인의 휴대전화로 전화를 걸 수 있는 사람은 오로지 휴대전화 주인 밖에 없어야 합니다. 이렇게 만들려면 음성 인식 시스템이 지금 말하는 사람이 누구인지 인식하고, 그 사람의 음성 명령에만 작동해야 합니다. 이렇게 특정인의 음성만을 인식하는 기술을 화자 인식 기술이라고 합니다.
물론 화자에 구애 받지 않는 음성 인식 기술도 있습니다. 이른바 화자독립형(speaker independent) 기술인데요. 이런 상황은 앞서 설명한 화자 인식 기술로 방지할 수도 있습니다.
필요에 따라 두 기술을 적절히 사용하면 됩니다. 각 기술은 다음 편에 보다 자세히 다루겠습니다.
음성 인식 기술의 미래
지금까지 휴대전화 광고와 함께 음성 인식 기술의 종류와 기능을 살펴봤습니다. 여기에 더해 더 많은 기술이 지속적으로 개발되고 있으며 그 중 일부는 AI 기술로도 구현되고 있습니다.
최근 음성 인식 기술이 더욱 현실적으로 쓸만하다는 평가를 받은 데에는 비약적으로 발전한 딥러닝 기술의 역할 덕분입니다.
음성 인식 기술이 주목받는 또 하나의 이유는 인터페이스 방식에서 혁신을 이루고 있기 때문입니다.
지금까지 인간이 기계에 말을 걸기 위해서는 키보드나 터치패드를 접촉하는 방식을 사용했습니다. 그러면 기계는 텍스트와 이미지로 답을 해줬죠.
그런데 이제는 인간이 음성을 통해서도 기계에 자신의 의도를 전달할 수 있습니다. 기계 역시 음성으로 답을 해주기도 합니다. 인간과 인간이 말로 커뮤니케이션하는 방식을 그대로 사용할 수 있습니다.
사람끼리 대화하듯 기계와 사람이 음성과 음성으로 커뮤니케이션!
AI 기술을 이용한 음성 인식 기술과 음성합성 기술 덕분입니다. AI의 궁극적 목표가 사람을 닮은 기계이기에 인간-기계 인터페이스 역시 이렇게 발전해가는 건 어쩌면 너무도 당연합니다.
그렇다면 미래에는 음성 기술을 기반으로 한 인터페이스가 모든 걸 대체할까요? 우리에게 너무나도 익숙한 SF작품인 ‘스타트렉(1966년)’과 ‘스타워즈(1977년)’에서 실마리를 찾아볼 수 있을 듯합니다.
스타트렉과 스타워즈를 보신 분이라면 ‘데이터(Data) 소령’과 ‘C3-PO’를 기억하실 겁니다. 두 캐릭터 모두 인간과 닮은 모습이지만, 인간이 아닌 기계라는 공통점을 지닙니다. 그래서 몸체에 키보드나 화면을 지니지 않았죠.
극 중 등장 인물들은 너무나도 익숙하게 이들과 모두 음성으로 대화를 나눕니다. 두 캐릭터를 보면 음성 인식 기술이 어디까지 발전해 나갈 것인지 엿볼 수 있습니다.
스타트렉이나 스타워즈에서 인간이 기계를 사용할 때 오로지 ‘음성만으로’ 명령을 내리거나 결과를 얻지 않는 것도 유의해서 봐야 할 부분입니다.
우주선 곳곳에는 손만 뻗으면 언제나 쉽게 사용할 수 있는 단추와 키보드 그리고 터치스크린이 설치돼 있습니다. 미래에는 지금보다 월등히 성능 좋은 음성 기술 기반 인터페이스가 보편화되겠지만, 모든 인터페이스를 대치하지는 않으리라고 조심스레 예측해 볼 수 있습니다. 각각 용도와 효율성에 맞는 방식이 적절히 균형을 이루며 사용되지 않을까 싶습니다.
다음 편에서는 AI 음성 기술 시리즈의 마지막으로 ‘화자 인식 기술’을 자세히 살펴보겠습니다.
김희만
AI Center Speech Lab 음성인터페이스팀. AI와 음성 인식의 발전에 기여하고 있는 많은 연구개발자 중 한 명입니다.
AI Center Speech Lab 음성인터페이스팀. AI와 음성 인식의 발전에 기여하고 있는 많은 연구개발자 중 한 명입니다.
 Facebook
Facebook  KakaoTalk
KakaoTalk  LinkedIn
LinkedIn  Email
Email  Copy URL
Copy URL