 Facebook
Facebook  KakaoTalk
KakaoTalk  LinkedIn
LinkedIn  Email
Email  Copy URL
Copy URL 게임 AI에 대한 R&D 연구를 선도해오고 있는 엔씨소프트.
엔씨소프트는 AI센터 내 스피치(Speech)랩을 설립, 전문 연구진들이 모여 음성 기술에 대한 연구 개발을 활발히 진행하고 있는데요.
‘게임과 AI’ 7편에서는 음성 기술에 대한 마지막 소개로, AI에서 꼭 필요한 음성 기술 중 하나인 화자 인식(Speaker Recognition) 기술의 큰 흐름을 핵심적인 원리와 함께 살펴보겠습니다.
게임 AI에 대한 R&D 연구를 선도해오고 있는 엔씨소프트.
엔씨소프트는 AI센터 내 스피치(Speech)랩을 설립, 전문 연구진들이 모여 음성 기술에 대한 연구 개발을 활발히 진행하고 있는데요.
‘게임과 AI’ 7편에서는 음성 기술에 대한 마지막 소개로, AI에서 꼭 필요한 음성 기술 중 하나인 화자 인식(Speaker Recognition) 기술의 큰 흐름을 핵심적인 원리와 함께 살펴보겠습니다.

중동의 구전 소설을 정리한 책 ‘천일야화’에는 ‘알리바바와 40인의 도둑’이라는 이야기가 있습니다. 알리바바라는 인물이 우연히 “열려라 참깨!”라고 외치면 문이 열리는 도둑의 소굴을 발견하고, 그곳에 있는 보물을 훔치는 내용입니다.
아마도 음성 인식 기반의 자동문을 다룬 최초의 이야기일 것입니다. 만약, 최근에 이 책이 출간됐다면 지문 인식이나 홍채, 얼굴 인식으로 열리는 동굴 문도 상상할 수 있을 겁니다. 이는 우리에게 익숙한 스마트폰 잠금 해제 기능이기도 하죠.

<그림 1> Open Sesame! 주문을 외치면 자동으로 열리는 동굴문
조금 더 상상의 나래를 펼쳐보겠습니다. 알리바바가 다시 동굴을 찾았습니다. 그는 도둑 무리들이 모두 자리를 비운 틈을 타서 “열려라 참깨!”라고 주문을 외칩니다. 그런데 더 이상 문이 열리지 않습니다. “열려라 참치!”, “열려라 땅콩!” 등 다른 주문을 외쳐봐도 소용이 없습니다. 무슨 일이 생긴 걸까요?
자동문의 기능이 업그레이드 된 것입니다. 이제 이 문은 40인의 도둑 목소리에만 반응합니다. 심지어, 주문이 틀려도 알아서 시스템이 목소리를 인식해 문을 열어줍니다.
이 이야기가 현실로 펼쳐진다면 얼마나 간편하고 안전할까요? ‘화자 인식(Speaker Recognition)’ 기술이 상상을 현실로 만들 수 있습니다. 시스템이 누군가의 목소리를 인식할 때, 미리 등록한 목소리인지 구별하는 것이죠. 이러한 과정을 통해 신뢰할만한 사람인지를 검증하는 시스템입니다.
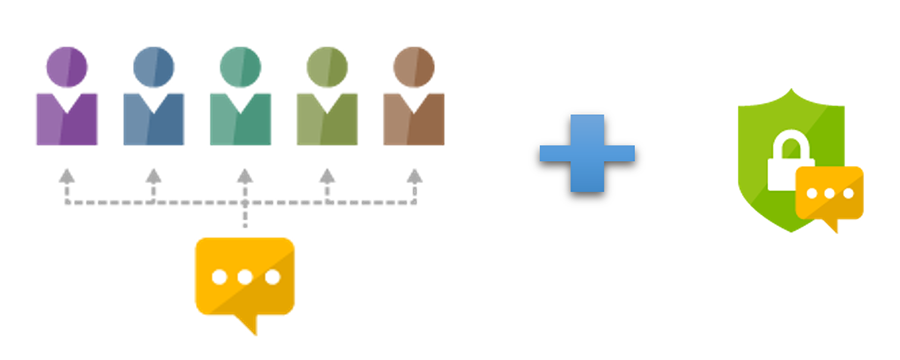
<그림 2> 화자 식별과 화자 검증의 결합으로 누구인지 알아내고 인증까지
1992년 개봉한 영화 ‘스니커즈(Sneakers)’에도 음성으로 신원을 확인하는 장면이 나옵니다.
영화 속 장면에서, 잠긴 문 앞 모니터에는 ‘안녕, 내 이름은 ********야. 내 목소리가 나의 열쇠야. 인증해줘(My name is ********. My voice is my passport. Verify me)’ 문장을 읽으라는 안내문이 보입니다.
그러자 주인공이 인증된 목소리가 담긴 녹음기를 켭니다. 이때 꼬인 목소리가 나오는 바람에 깜짝 놀랍니다. 시스템은 꼬인 목소리도 인식합니다. 친절하게도 ‘천천히 말해주세요(Please speak more slowly)’라고 답을 하죠.
주인공이 다시 녹음기를 켭니다. 그러고는 “안녕, 내 이름은 워너 브란데스야. 내 목소리가 나의 열쇠야. 인증해줘(My name is Werner Brandes. My voice is my passport. Verify me)”라는 음성을 입력하죠.
시스템은 녹음된 목소리를 인식합니다. 인증을 진행한 뒤 닫힌 문을 열어주죠. 영화에 그치지 않습니다. 이는 화자 인식 시스템에서 자주 샘플로 사용하는 문장이기도 합니다.
<영상 1> 영화 ‘스니커즈’에서 음성으로 신원 인증을 하는 장면
‘나의 목소리가 암호입니다(My voice is my password)’는 제목의 TED 영상에는 ‘나의 목소리가 암호입니다’라는 수많은 사람들의 목소리가 울려 퍼집니다.
이 역시 화자 인식의 대표적 사례라고 할 수 있습니다. 단순한 기호들의 조합이 아니라 음성 생체 정보를 사용한다면 스마트폰에서 목소리만으로 간단하게 자신의 신원을 확인할 수 있다는 점을 보여주는 영상입니다.
<영상 2> TED 속 수많은 인증용 목소리
화자 인식 기술은 기능에 따라 화자 식별(Speaker Identification)과 화자 검증(Speaker Verification)으로 분류됩니다.
우선, 화자 식별 과정부터 살펴보겠습니다. <그림 3>에는 미리 N명의 화자 모델(Voiceprint)을 등록한 시스템의 화자 식별 과정이 그려져 있습니다.
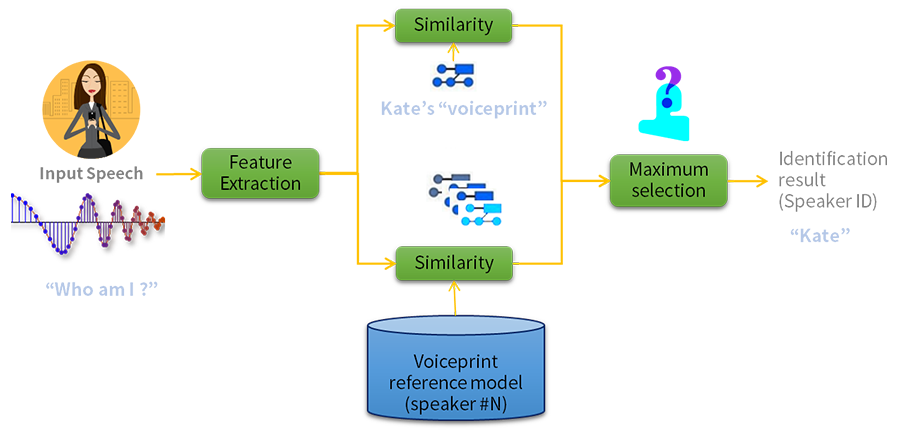
<그림 3> 화자 식별
누군가가 이 시스템에 음성을 입력하면, 등록된 화자 모델을 검색해 음성과 가장 일치하는 화자를 찾아줍니다.
하지만 치명적인 단점을 갖고 있는데요. 시스템에 등록되지 않은 화자의 음성을 구분하지 못합니다. 등록된 음성 중 가장 유사한 화자로 인식할 뿐이죠. 이는 시스템에 등록하지 않은 목소리를 통해서도 인증을 할 수 있다는 의미입니다. 보안에 문제가 생길 수밖에요.
반면에 화자 검증 기술은 이 단점을 보완합니다. <그림 4>는 시스템이 케이트(Kate)라는 화자의 음성 정보를 저장한 뒤 타인의 음성과 비교해 목소리 정보(Voiceprint)의 일치 여부를 판단하는 검증 과정을 보여줍니다.
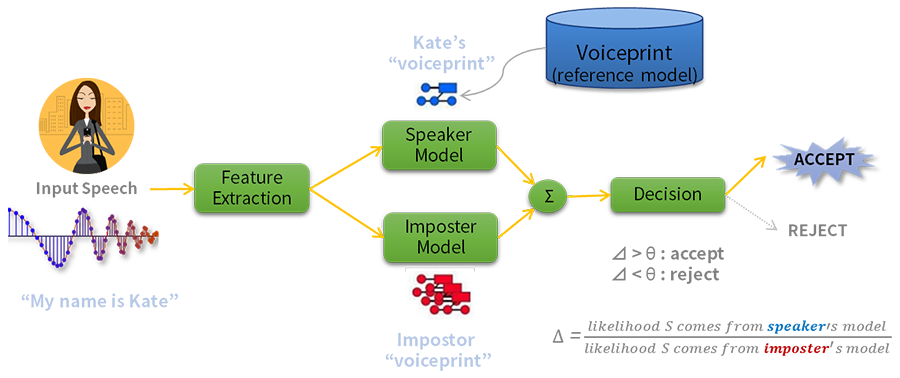
<그림 4> 화자 검증
화자 검증 시스템은 저장한 화자의 음성과 입력 음성 사이의 유사도(Likelihood)를 구하는데요.
저장되지 않은 목소리의 화자를 의미하는 ‘사칭자(Imposter 또는 background) 모델’과 ‘유사도 간 비율(Δ)’을 측정합니다. 그리고 사칭자 대비 신뢰할 수 있는 비율에 해당하는 ‘기준값(Θ)’에 따라 화자 일치 여부를 검증합니다. 시스템은 이를 통해 등록되지 않은 목소리를 구별할 수 있습니다.
화자 식별 및 화자 검증 기술은 발성하는 문장의 제한 범위에 따라 ‘문장독립(Text-independent) 방식’과 ‘문장종속(Text-dependent) 방식’으로 구분합니다.
문장독립 방식은 발성하는 문장 형식이나 종류에 제한을 두지 않습니다. 즉, 형식이 정해지지 않은 문장을 발성하더라도 화자를 인식할 수 있다는 의미입니다. 문장독립 방식은 표현의 자유도를 보장합니다. 시스템이 인식하는 문장의 형식이 다양하기 때문입니다. 대신 이를 구현하기 위한 기술 난이도가 높습니다.
문장종속 방식의 경우 시스템이 제시된 문장을 읽은 음성에 한해 화자를 인식할 수 있습니다. 사용자가 제시 어구를 사전에 숙지한 뒤 말해야 하기 때문에 편의성이 다소 떨어질 수 있습니다.
장점도 있습니다. 발성 문장에 대한 사전 정보를 확보할 수 있죠. 이를 통해 화자 음성의 통계 모델을 신뢰성 있게 구축할 수 있습니다. 시스템이 입력된 음성에 대한 높은 인식률을 보여준다는 의미입니다. 화자 등록을 위한 음성 데이터 분량을 줄일 수도 있습니다.
만약, ‘알리바바와 40인의 도둑’ 이야기에서 “열려라 참깨!” 외에도 “열려라 참치”나 “열려라 땅콩”을 외치더라도 시스템이 화자의 목소리를 인식해 문이 열린다면 문장독립에 해당합니다. 등록된 문장인 “열려라 참깨!”라는 발성에만 작동하는 건 문장종속 방식을 의미하죠.

<그림 5> 주문을 외울 필요 없는 문장독립 방식
문장독립과 문장종속 방식 외에 추가로 고려할 사항들이 더 있습니다.
화자 인식 시스템의 안내에 따라 음성을 발성하는 ‘협조적인 화자(Cooperative speakers)’가 있습니다. 하지만 적절한 발성을 하지 못하는 등 ‘예상치 못한 반응을 보이는 화자(Unwitting speakers)’도 있습니다. 이 경우 다시 발성을 할 수 있게끔 안내하거나, 발성한 음성에 대한 예외 처리를 할 필요가 있습니다.
사용자 입력 품질에 따라 ‘고품질의 음성(High quality speech)’이 있겠지만, 상황이 늘 그렇지는 않습니다. 잡음이 포함될 가능성이 있는 ‘다양한 환경으로부터 입력(Variable quality speech)’도 고려해야 합니다.
전화망이나 원거리 입력의 경우에 따라 소리 값의 왜곡이 생기기 때문입니다. 개발 환경에 따른 차이도 있습니다. 마이크의 종류와 채널, 주변 환경에 따른 고려사항과 제약사항에 따라 학습 환경(Training condition)과 테스트 환경(Testing condition)이 다를 수도 있습니다.
이밖에 사람의 목소리가 바뀔 가능성도 있습니다. 가령, 2년 전 화자 검증 시스템에 등록한 목소리와 현재 목소리가 다를 수 있습니다. 이 경우에는 화자 모델(Voiceprint)을 갱신해야 합니다.
화자 식별 및 화자 검증 시스템을 구성하기 위해서는 미리 화자 모델을 학습(Training)하는 과정과 특정 화자의 목소리를 등록(Enrollment)하는 과정이 필요합니다. 학습에 필요한 문장뿐만 아니라 등록에 필요한 발성 문장들도 필요한데요. 녹음한 문장이 다양하고 많을수록 등록된 화자를 정확하게 인식할 수 있습니다.
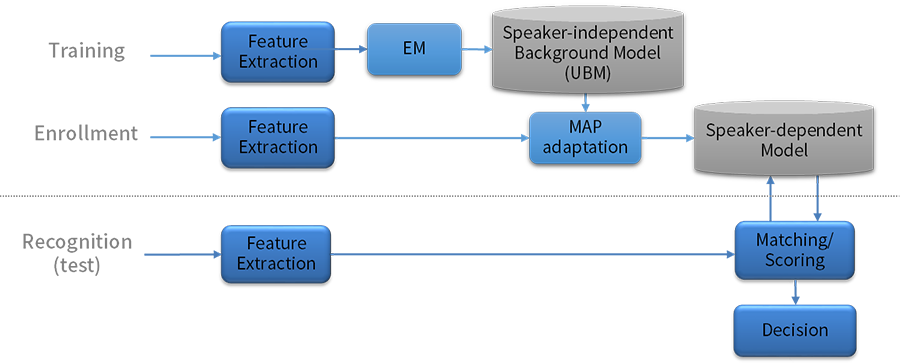
<그림 6> 학습(Training), 등록(Enrollment), 인식(Recognition) 과정
켑스트럼(Cepstrum), LPC(Linear Predictive Coding), MFCC(Mel-Frequency Cepstrum Coefficients), PLP(Perceptual Linear Predictive Analysis) 등과 같은 특징 추출 방식은 음성 인식 과정에서 사용하는 대표적인 방법입니다. 이를 활용해 음성 신호로부터 추출한 입력 패턴을 모델링할 수 있는데요. 대표적으로 GMM-UBM(Gaussian Mixture Model - Universal Background Model) 기법이 널리 사용됩니다.
GMM-UBM 기법은 화자 인식 시스템의 학습 데이터 확보에 도움을 줍니다. 수천 명에 이르는 다양한 화자의 목소리 특징을 반영한 ‘화자독립(Speaker-independent) 모델’을 백그라운드(Background) 통계 모델로 두기 때문입니다. 또한, 등록 과정에서 입력된 목소리로 ‘최대사후(MAP; Maximum a Posterior) 적응 기법’을 적용합니다. 이를 통해 개별로 등록한 화자에 대해 화자종속 (Speaker-dependent) 모델을 구성할 수 있습니다.
또한, GMM-UBM 방법에 비선형 기법인 SVM(Support Vector Machine) 분류기를 추가로 적용하는 방법도 있습니다. 화자 적응을 통해 생성된 GMM 모델의 평균 벡터를 입력으로 하는 슈퍼벡터(Super-vector)를 사용하는 ‘GMM-SVM’ 방법을 식별과 검증에 활용하여 더 나은 성능을 확보할 수 있습니다.
마지막으로 정규화 기법으로 잘 알려진 z-norm(Zero normalization), t-norm(Test normalization) 및 zt-norm 방식으로 유사도값에 대해 스코어 기반 정규화를 수행합니다. 특히 스코어값은 화자 검증 시 인증 수단으로 주로 사용합니다. 그래서 승인과 거부를 결정하는 기준점(<그림 5>의 Θ값)을 설정하기 위한 스코어 값이 매우 중요합니다.
표준적인 접근 방법인 GMM과 SVM 기법 이외에도 요인분석 기법의 일종인 결합요인분석(JFA; Joint Factor Analysis), 또는 i-벡터 기법을 SVM과 결합시키는 방법도 있습니다. 이를 통해 화자 인식 성능을 높이는 방향의 연구가 많이 진행됐습니다.
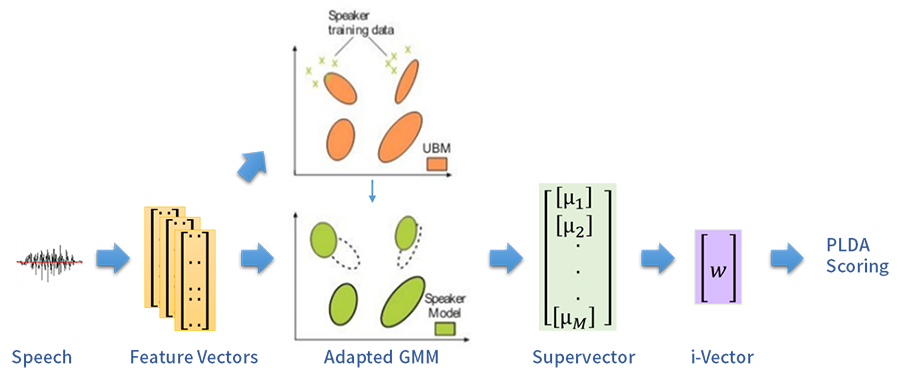
<그림 7> i-벡터 기반 화자 인식
JFA 기법은 화자/세션 독립의 백그라운드 모델에 기반합니다. 이는 <그림 7>의 슈퍼벡터(m)를 바탕으로 각 ‘고유 음성(Eigenvoice) 행렬’을 갖는 화자종속 요소와 채널종속 요소로 구성 요인들을 분리한 모델입니다.
고유값 분해(Eigenvalue Decomposition)를 위해서는 복수의 화자가 다양한 채널에서 녹음한 음성 데이터가 필요합니다. 하지만 현실적으로 사용되는 환경마다 말뭉치(Corpus) 구축이 어렵습니다. 실제 사용되는 환경도 제한적이므로 적용하는 데에 한계가 있습니다.
이를 개선해 i-벡터(w)를 기반으로 화자를 인식하는 기법도 있습니다. 채널 정보를 제거한 뒤 발화 단위의 슈퍼벡터(s)를 화자와 세션 정보를 하나 낮은 차원의 변환 행렬T(Total-variable Matrix)에 표현하는 기법입니다. 이는 화자 인식 연구 중 가장 효율적인 방법으로 알려져 있습니다.
화자 인식 성능은 인식을 시도한 전체 횟수 대비 성공 비율(Recognition Rate)로 구분할 수 있습니다.
화자 검증 평가 방법으로는 ‘오거부율(FRR; False Rejection Rate, 제 1종 오류)’과 ‘오인식률(FAR; False Acceptance Rate, 제 2종 오류)’을 사용합니다. 오거부율은 시스템이 등록된 화자를 잘못 거부하는 비율을 의미하고, 오인식률은 등록되지 않은 화자를 잘못 승인하는 비율을 뜻합니다. 보통 DET(Detection Error Tradeoff) 곡선을 통해 성능을 분석하며, 오거부율과 오인식률이 같아지는 지점을 EER(Equal Error Rate)이라고 합니다.
일반적인 시스템에서는 오인식률에 집중합니다. 하지만 높은 수준의 보안을 필요로 하는 금융거래나 강화된 생체인증이 필요한 경우에는 본인임에도 신뢰도가 높은 경우에만 승인을 하도록 조정해야 합니다.
승인을 잘못 거부하는 오거부율이 높아지더라도 승인 기준점을 높여 오인식률을 낮출 수 있습니다. 반대로 편의성 면에서 화면 잠금과 같은 간단한 인증 기능이 추가된 경우 오거부율을 낮춰 적용할 수 있습니다.
오류율은 신호대잡음비(SNR)가 높은 조용한 환경일수록, 학습 및 등록 문장을 많이 녹음할수록, 문장독립보다는 문장종속 방식이, 학습 채널과 테스트 채널의 차이가 적을수록 낮아집니다.
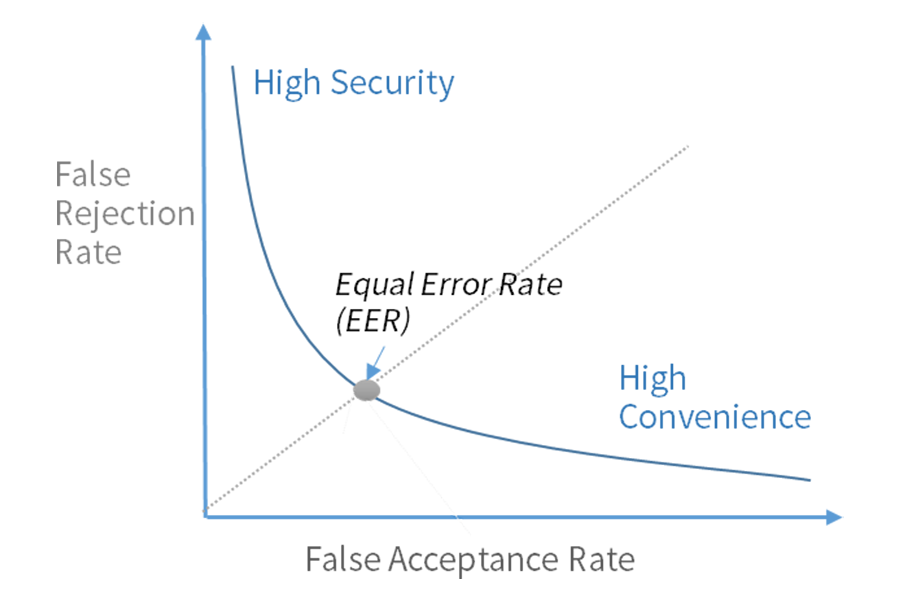
<그림 8> 성능 평가 DET 곡선
화자 인식 영역에서도 딥러닝 기술을 적용할 수 있습니다.
딥러닝 특성상 화자 별로 대량의 데이터가 필요한데요. 성능 개선의 측면에서 아직까지는 기존 접근 방식과 비교해 한계가 있습니다. 이 과정에서 기존 접근 방법에서 일부 기능을 딥러닝 방식으로 교체하거나 일부만 딥러닝 기법을 적용하는 ‘하이브리드 방식’으로 접목하는 연구들도 등장합니다.
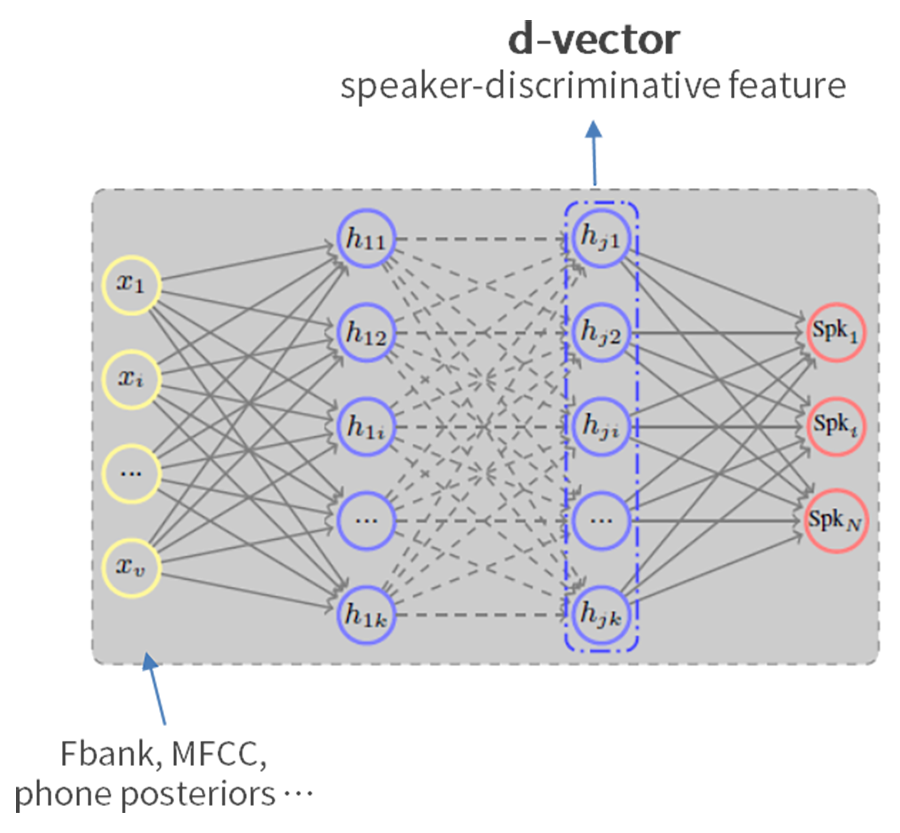
<그림 9> 딥러닝 기반 화자 식별
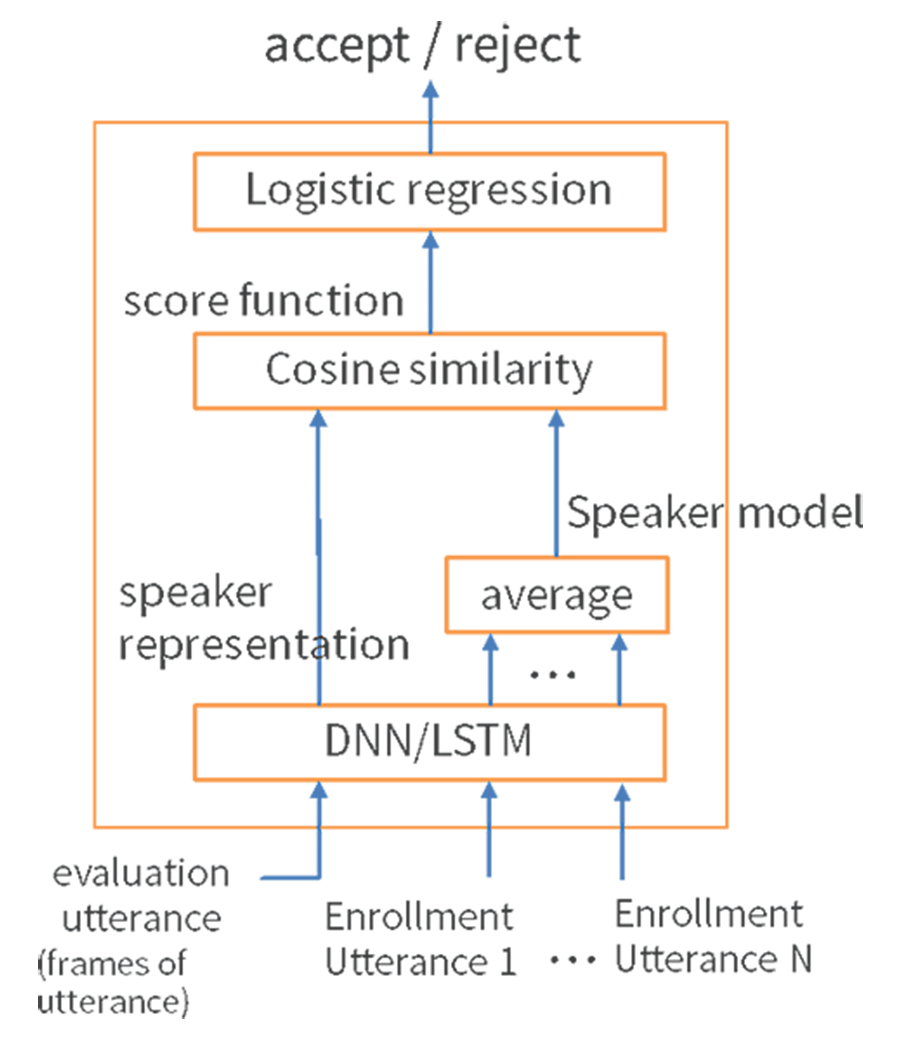
<그림 10> 딥러닝 기반 화자 검증
<그림 9>와 같이 기존에 사용하는 다양한 음성 특징 벡터들을 혼합해 입력하고, 심층신경망(DNN)을 통해 학습한 특징 벡터를 사용하는 화자 식별 방식이 있습니다. 아울러 <그림 10>은 DNN/장단기메모리(LSTM) 결합을 통해 등록된 입력 음성과 인식 평가 음성의 스코어를 비교하는 방식으로 구성한 구조입니다.
딥러닝 기반 화자 식별과 검증 방식은 화자 인식 분야에서 아직 뛰어날 만한 성능을 보이고 있지는 않습니다. 하지만 딥러닝 네트워크 구조를 공유하고, 단일 음성 입력을 입력으로 한다는 강점이 있습니다. 이를 통해 무슨 말을 했는지(음성 인식), 누가 말했는지(화자 식별), 그리고 어떤 감정 상태인지(감정 인식) 등 다양한 정보를 일원화할 수 있습니다.
또한, 화자 인식의 영역을 ‘화자 분할(Speaker Diarization)’과 ‘화자의 연령대(Speaker Age) 분류’, ‘남녀성별 (Male and Female) 분류’ 문제로 확장할 수 있습니다.
화자 분할은 동일 화자의 음성 구간을 구분하고 여러 명의 화자 중 누구인지를 식별하는 문제입니다. TV 뉴스나 토론 프로그램에서 진행자와 토론자가 태그된 스크립트 작성이나 영화나 드라마의 화자 정보 색인에 활용될 수 있습니다.
연령 인식은 음성 구간 영역이라기보다는 연령에 따른 분류를 의미합니다. 현재의 분류 정확도를 단일 정보로 활용하는 데는 한계가 있습니다. 보조수단이나 음성로그에 대한 통계 정보 정도로 참고할 수 있습니다.
지난 2017년 1월 미국에서 아마존의 AI 스피커 ‘에코’가 오작동해 화제가 된 적(관련 기사)이 있습니다. 에코가 TV에서 나오는 소리를 주인의 목소리로 착각하고 물건을 주문했던 일인데요. 꼬마 아이가 에코에게 ‘인형의 집’과 놀고 싶다고 말하자 에코가 부모도 모르게 이 제품을 주문한 사건이 발생합니다.
샌디에이고 지역 뉴스의 앵커 짐 패튼이 이 사건을 두고 “알렉사에게 인형의 집을 달라고 말하다니 참 사랑스러운 아이네요”라고 보도했습니다. 그런데 일부 가정의 에코가 앵커의 음성을 주인의 말로 착각해 인형의 집을 주문하는 소동이 발생했습니다. 만약, 에코에 화자 인식 기술이 미리 적용했다면 주문을 하지 않았을 겁니다.

<그림 11> 아마존 에코 관련 에피소드
많은 기업이 화자 인식에 관심을 갖는 이유는 보안과 개인 맞춤형 서비스를 제공하기 위해서입니다. AI 대화형 시스템의 출현으로 말 그대로 '손가락 하나 움직이지 않고 목소리만으로' 원하는 정보부터 쇼핑, 집안 전자제품 제어까지 음성 명령으로 가능해졌는데요. 이 역시 해결해야 할 과제일 것입니다.
더 나아가 앞서 이야기했던 남성과 여성, 그리고 대략의 연령대에 따른 음성 차이를 통해 가족 구성원 파악도 할 수 있다면 어떠할까요. 만약, 프로필을 등록하는 형태로 화자 인식이 가능해진다면 여러 명이 동시에 사용하는 공유 단말 및 서비스에서도 편리하고 안전하게 개인 용무를 볼 수 있을 것입니다. 어느 장소에서 어떤 기기를 사용하게 되던 연속성 있는 맞춤형 서비스가 가능할 수 있겠죠.
시장 조사 기관 가트너(Gartner)는 2020년까지 개인용 기기는 70억 대, 웨어러블 기기는 13억 대, 그리고 사물 인터넷(IoT) 기기는 57억 대로 늘어날 것으로 전망했습니다. 이 중 최소 20억 대의 기기 및 장비가 ‘제로터치 사용자 인터페이스(UI)’ 기반으로 작동할 것이라는데요. 생태계가 활성화되면 음성 기반 서비스의 무한한 확장도 기대할 수 있을 것입니다.
지금까지 총 네 편에 걸쳐 현재 엔씨소프트의 스피치(Speech)랩에서 중점을 두고 있는 주요 연구 분야를 소개했습니다. 이밖에 음성을 통한 음성 압축·전송·복원 기술, 음향 이벤트 검출 및 분류, 음성 감정 인식, 외국어 학습 등 흥미로운 음성 기술 관련 연구 주제들도 있습니다. 추후에 또 소개할 기회가 생기면 좋겠습니다. 😀

이경님
RELATED


