 Facebook
Facebook  KakaoTalk
KakaoTalk  LinkedIn
LinkedIn  Email
Email  Copy URL
Copy URL 게임 AI에 대한 R&D 연구를 선도해오고 있는 엔씨.
엔씨는 AI센터 내에 비전(Vision) AI랩을 설립, 컴퓨터 비전 기술과 게임 개발 과정의 접점을 찾기 위해 다양한 연구 개발을 진행하고 있습니다.
‘게임과 AI’ 8편에서는 시각 정보를 처리하고 판단을 내리는 인공지능 기술인 컴퓨터 비전의 개념을 살펴보며, 엔씨의 게임 아트 개발에 도움을 주기 위해 어떤 노력을 하고 있는지 살펴보겠습니다.
게임 AI에 대한 R&D 연구를 선도해오고 있는 엔씨.
엔씨는 AI센터 내에 비전(Vision) AI랩을 설립, 컴퓨터 비전 기술과 게임 개발 과정의 접점을 찾기 위해 다양한 연구 개발을 진행하고 있습니다.
‘게임과 AI’ 8편에서는 시각 정보를 처리하고 판단을 내리는 인공지능 기술인 컴퓨터 비전의 개념을 살펴보며, 엔씨의 게임 아트 개발에 도움을 주기 위해 어떤 노력을 하고 있는지 살펴보겠습니다.

컴퓨터 비전(Computer Vision)은 사람이 시각 정보를 처리하고 이를 기반으로 판단을 내리는 과정을 기계가 대신할 수 있도록 만드는 기술입니다. 사람이 시각 정보를 이용해서 판단을 내리는 일에는 무엇이 있을까요? 가장 쉬운 예로, 사람의 얼굴을 인식하는 일이 있습니다.
사람은 얼굴을 인식하는 행동이 익숙하기 때문에, 여기에 ‘과정’이 필요하다는 사실을 느끼기 어렵습니다. 하지만 기계가 사람 얼굴을 인식할 수 있도록 만드는 것은 매우 어려운 문제였습니다. 컴퓨터 비전 연구자들은 이 문제를 해결하기 위해 많은 노력을 기울여왔습니다. 그 결과, 사람보다 더 정확하게 사람의 얼굴을 인식하는 수준에 이르렀습니다.
요즘 많이 사용하는 얼굴 인식을 통한 핸드폰 잠금 해제 기능이 그러한 연구의 결과물 중 하나입니다. 지문 인식을 통한 잠금 해제 기능도 컴퓨터 비전 기술을 기반으로 구현된 기능입니다. 요즘 백화점이나 마트의 주차장에 진입할 때 적용되는 번호판 인식 시스템도 마찬가지고요. 많은 회사에서 연구와 테스트를 진행하고 있는 자율주행차에도 다양한 컴퓨터 비전 기술이 적용되고 있습니다.

컴퓨터 비전 기술의 실생활 적용 사례.
조금 더 기술적인 얘기를 해보도록 하겠습니다. 사람처럼 영상에서 필요한 정보를 추출할 수 있도록 기계를 만드는 일은 절대 쉽지 않습니다. 사람이라면 쉽게 다른 사람의 얼굴을 인식하고 다른 사람이 쓴 글씨를 인식하지만, 기계가 인식하기 위해서는 많은 연구자들의 노력이 필요했습니다.
이러한 노력 중의 하나가 ImageNet Large Scale Visual Recognition Challenge(ILSVRC, 이하 ImageNet Challenge)였습니다. 이는 2010년부터 2017년까지 진행된 대회로, 영상에 어떤 사물이 있는지를 인식하는 사물 인식(Object Recognition) 문제를 푸는 과제를 수행해야 합니다.
2012년에는 ImageNet Challenge를 통해 딥러닝(Deep Learning) 기반 컴퓨터 비전 알고리즘의 기본이 되는 Convolutional Neural Network(CNN)가 제안되었습니다. 또 많은 연구자들이 다양한 방식으로 CNN 구조를 개선한 끝에 2015년에는 드디어 사물 인식 문제에서 사람보다 우수한 성능을 기록했습니다. ImageNet Challenge는 2017년 대회를 마지막으로 더 이상 진행되지 않고 있습니다.
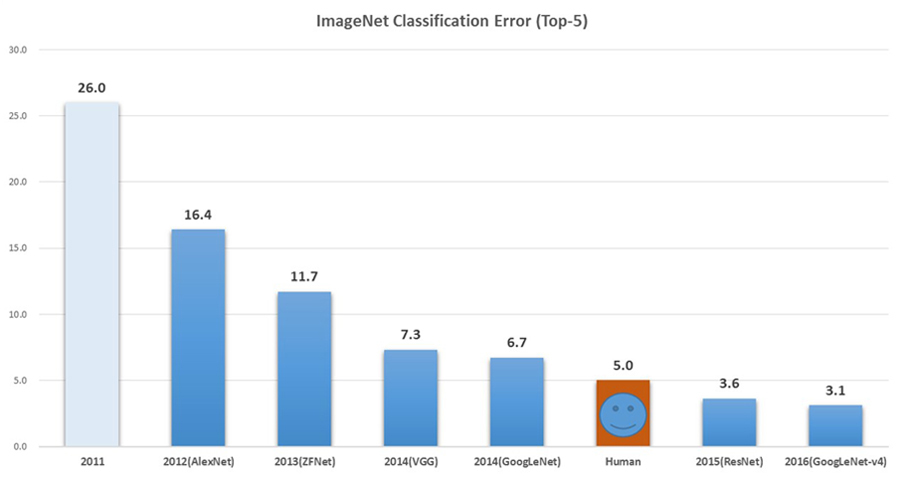
ImageNet Challenge 인식 오류 변화를 나타낸 그래프로, 수치가 낮을수록 좋음.
2015년 딥러닝 알고리즘이 사물 인식 문제에서 사람보다 우수한 성능을 기록했다고 해서 기계가 사람보다 시각 정보를 더 잘 처리하게 되었을까요? 물론 그렇지는 않을 겁니다.
이는 ImageNet Challenge 문제를 더 잘 맞추게 되었다는 의미일 것입니다. 좀 더 의미를 확장하면, 충분한 양의 정제된 데이터가 있을 경우에 선택지가 주어진 영상 인식 문제를 잘 풀 수 있게 된 것입니다.
실제로 ImageNet Challenge를 통해 제안된 다양한 CNN 구조들은 컴퓨터 비전의 다른 문제들, Semantic Segmentation, Object Tracking 등의 문제에 적용되어 기존 알고리즘을 뛰어넘는 성능을 보여주었습니다. 또 컴퓨터 비전뿐만 아니라 다른 AI 분야에서 딥러닝이 대세로 자리매김하는 데에 많은 공헌을 해왔습니다.
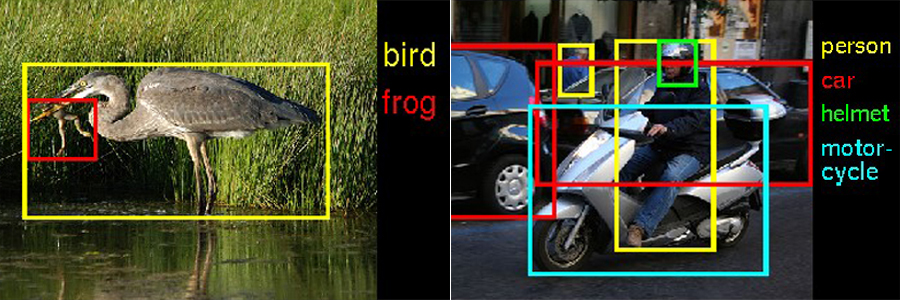
ImageNet Challenge 데이터 예시.
기계가 사람처럼 영상을 생성할 수 있다고 가정해보면 어떨까요.
예를 들어, 사진 속에 들어 있는 동물이 개인지 고양이인지를 맞출 수 있는 기계와 개나 고양이를 그릴 수 있는 기계가 있다고 할 때, 어떤 기계가 더 시각 정보에 대한 이해가 깊다고 할 수 있을까요. 아마도 사물의 영상을 인식할 수 있는 쪽보다, 영상을 생성할 수 있는 쪽이 더 컴퓨터 비전 연구의 목표에 가까울 것입니다.
하지만 이미지 생성은 그 목표 수준이 더 높은 만큼, 인식 문제보다 훨씬 더 해결하기 어렵다는 것이 많은 연구자들의 생각이었습니다. 컴퓨터 비전 분야에서는 이미지 생성 기술의 중요성을 강조하기 위해 물리학자인 리처드 파인만(Richard Feynman)의 "만들 수 없다면 이해하지 못하는 것이다.(What I cannot create, I do not understand.)"는 문구를 종종 인용합니다. 이미지를 만들 수 있어야 이해도 가능하다는 의미입니다.

(이미지를) 만들 수 없다면 이해하지 못하는 것이다!
이런 상황에서 2014년 Generative Adversarial Networks(GAN)가 등장해 컴퓨터 비전 연구의 흐름에 큰 변화를 불러왔습니다.
생성기(Generator)와 분류기(Discriminator)가 별도로 존재하여 서로 다른 목표를 갖고 적대적으로 학습되도록 하는 GAN 구조는 생성 문제의 훌륭한 해결책이 되어주었습니다. GAN의 등장 이후에 많은 컴퓨터 비전 연구자들이 생성 기술 연구에 참여하였고, 그 결과 2015년 ~ 2016년에 나온 생성 연구 결과물들은 많은 사람을 놀라게 했습니다.
사람의 얼굴 이미지를 생성하고(Deep Convolutional Generative Adversarial Networks; DCGAN) 텍스트 입력을 받아서 꽃 이미지를 생성하는(Stacked Generative Adversarial Networks; StackGAN) 등 빠르게 생성 기술의 발전이 이루어지게 되었습니다.

얼굴 이미지 생성. (DCGAN, 2015. 11)

텍스트 입력 기반 꽃 이미지 생성. (StackGAN, 2016. 12)
전통적인 컴퓨터 비전 연구는 영상에서 정보를 추출하는 데에 초점을 맞춰왔습니다. 언뜻 보기에는 게임 개발 과정에서 고민하는 것 중에 하나인, ‘실제처럼 보이는 영상 생성’과는 큰 접점이 없는 것 같습니다. 하지만 생성 기술의 발전을 통해 컴퓨터 비전 기술이 게임 개발에 큰 도움이 될 수도 있겠다는 인식이 생기기 시작했습니다.
개인적으로도 CNN의 등장을 가져온 ImageNet Challenge 결과들과 GAN을 기반으로 하는 많은 생성 연구 결과들을 보면서, 기존 기술에 비해 엄청난 발전이고 매우 흥미로운 결과물들이지만 산업적 성공까지 이어진 사례는 많지 않다고 느꼈는데요. 때문에 더더욱 게임 개발 과정에 컴퓨터 비전 기술을 적용해볼 만한 요소가 많겠다는 생각도 들었습니다.
그래서 컴퓨터 비전 기술과 게임 개발 과정의 접점을 찾아서 산업적 성공 사례를 만들어 보자는 목표를 갖고 엔씨에서 컴퓨터 비전 연구를 시작하게 되었습니다.
엔씨의 비전(Vision) AI랩에서의 초기 프로젝트는 이미지 인식 기술을 이용한 그래픽 리소스 태깅 프로젝트와, 생성 기술을 이용한 스케치 이미지 채색 및 캐릭터 이미지 생성 프로젝트였습니다.
과거 게임에 사용됐던 그래픽 리소스 관리를 위해서는 개별 그래픽 리소스에 태깅 작업이 필요한데요. 여기에 인식 기술을 이용해서 도움을 주기 위해 시작했던 프로젝트가 그래픽 리소스 태깅 프로젝트입니다.
사물 인식 기술의 정확도가 100%가 될 수 없다는 것을 잘 알기 때문에, 태깅 작업자를 대체하기보다는 작업자의 작업을 도와준다는 제한된 역할을 목표로 잡았습니다. 그래서 이미지 태그와 함께 Confidence Score를 출력해서 작업자가 이를 참고하여 작업할 수 있는 시스템을 구성했습니다.
또 클래스의 종류에 비해 데이터의 양이 많이 부족한 상황이라 Data Augmentation 방법을 활용해서 학습 데이터를 늘리는 것도 중요한 연구 주제였습니다.

그래픽 리소스 태깅 결과물.
스케치 이미지 채색 프로젝트는 Pix2Pix(관련 링크)를 비롯한 Image-to-Image Translation 기술과 Style2Paints(관련 링크)를 비롯한 Image Colorization 기술에서 힌트를 얻어 시작했던 프로젝트입니다. 아티스트의 작업을 돕기 위해, 스케치 이미지와 채색 레퍼런스 이미지를 입력으로 넣으면 스케치 이미지에 색을 칠해주는 시스템을 개발하는 것이 목표였습니다.
캐릭터 이미지 생성 프로젝트는 기획자들에게 도움을 주는 것을 목표로 시작한 프로젝트였습니다.
새로운 캐릭터 콘셉트 아트 제작에 도움을 주고자 머리카락의 색, 눈동자의 색, 얼굴 모양 등을 입력으로 받아서 입력 조건을 만족하는 다양한 캐릭터 이미지를 생성하는 시스템을 만들기로 했습니다. 수집 과정의 한계 때문에 생성되는 결과물은 여자 캐릭터 얼굴로 제한하여 진행했습니다.
초기 프로젝트 결과를 공유하고 작업자들의 피드백을 받으면서 많은 것을 배웠습니다.
우선 창작에 있어서 아티스트들의 수준이 매우 높다는 점이었습니다. 생성 기술의 결과물만 볼 때는 그 자체로 놀랍다가도 막상 아티스트들의 결과물과 비교해보면, ‘아직 갈 길이 멀다’는 생각을 하게 되었습니다. 특히 최종 결과물로 사용하기에는 이미지의 해상도가 많이 부족하여 Super Resolution 기술을 적용해서 해상도를 키우는 작업도 함께 진행했습니다.
또 AI Assistant를 위해서는 작업자들의 요구를 정확하게 파악하는 것이 중요하다는 점도 배웠습니다. 작업자들로부터 스케치 이미지 채색 결과물의 품질에 대해서는 좋은 평가를 받았지만, 딱히 활용할 곳은 없다는 피드백을 받기도 했습니다.
누구나 그렇듯이, 작업자들은 본인이 원하는 만큼 컨트롤할 수 있고 대신에 주어진 일은 확실하게 해내는 Assistant를 원하는데, 당시 시스템은 그렇지 않았기 때문입니다. AI Assistant의 결과물에서 마음에 들지 않는 부분이 있어서 수정을 하게 되면 오히려 작업 효율이 떨어질 것 같다는 의견도 들었습니다.
초기 프로젝트를 통해 얻은 교훈은 연구 방향을 구체화하는 데 큰 도움이 되었습니다. 막연히 컴퓨터 비전 기술을 이용해서 게임 개발에 도움을 주는 것에 그치지 않고, 현재는 ‘컴퓨터 비전 기술 연구를 통해, 게임 개발 및 영상 제작 과정을 효율화할 수 있는 기술을 개발하고 실용화하는 것’을 목표로 삼고 연구 개발을 진행하고 있습니다.
위의 목표를 이루기 위해, 세 가지 측면에 중점을 두고 연구 개발을 진행하고 있습니다.
작업자들의 요구사항과 현재 기술 수준을 정확하게 파악하여 실제 시스템과 서비스를 개발하는 기술 실용화, 주어진 문제에서 요구되는 성능 수준을 만족시키기 위해 기술 수준을 향상시키는 원천 기술 연구, 그리고 기술 적용 분야의 확대를 위한 지속적인 신규 적용 분야 발굴을 세부 목표로 두고 있습니다.
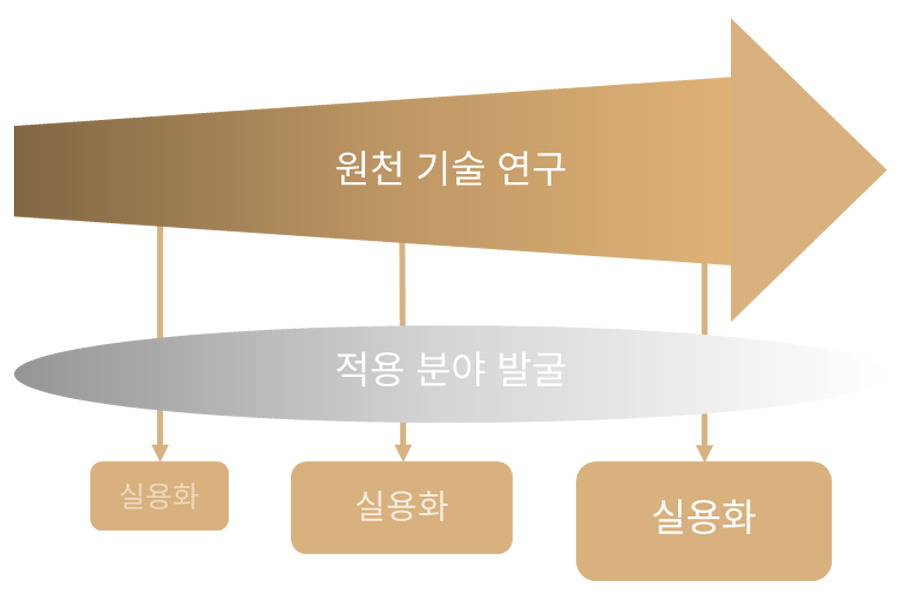
엔씨의 컴퓨터 비전 연구 목표 및 방향.
초기 프로젝트의 결과를 기반으로, 현재는 실사 이미지로부터 게임 캐릭터의 3D 얼굴 모델을 생성하는 캐릭터 변환 프로젝트, 실사 이미지로부터 게임 아이콘 이미지를 생성하는 아이콘 변환 프로젝트, 추상적 태그로부터 캐릭터 이미지를 생성하는 캐릭터 이미지 생성 프로젝트 등을 진행하고 있습니다.
또한 사내에서 컴퓨터 비전 기술에 대한 수요가 늘어남에 따라 다양한 부서와의 협업 프로젝트도 진행하고 있습니다.
AI 기반의 야구 정보 서비스 PAIGE를 만드는 NLP Center와의 협업 프로젝트로 야구 하이라이트 추출 프로젝트를 진행하고 있습니다. 또 QA팀과 함께 텍스트 QA 자동화 목적으로 게임 클라이언트 화면에서 문자를 인식하는 문자 인식 프로젝트도 진행하고 있습니다.
게임 화면 문자 인식 중간 결과물.
이외에도 사람 수준으로 시각 정보를 인지하는 Human-level Inference에도 관심을 갖고 Video Understanding 분야에 대해서도 연구하고 있습니다.
아직 초기 단계이지만, 사람처럼 시각 정보를 처리하고 이를 기반으로 판단하는 기술은 반드시 필요하고, 앞으로는 더욱 비디오 데이터가 중요해질 것이라는 생각으로 Video Understanding 분야의 요소 기술인 Temporal Event Localization, Video Summarization, Video Captioning에 대한 연구를 진행하고 있습니다.
다음 편에서는 현재 진행하고 있는 컴퓨터 비전의 개별 프로젝트들에 대해서 더욱 구체적으로 소개하겠습니다.

이준수
RELATED


