엔씨소프트는 대한민국 게임회사 최초로 AI Lab을 구축, 게임 AI에 대한 R&D 연구를 선도해 왔습니다. 미래의 핵심 경쟁력으로 꼽히는 AI에 대한 연구를 체계적으로 수행하여 게임 산업에 긍정적 시너지를 내기 위해 노력하고 있는데요.
엔씨소프트가 게임 AI에 대해 지금껏 연구해 온 정보를 공유하고 환기시키고자 새로운 연재 ‘게임과 AI’를 시작합니다. 또한 게임 AI에 이어서 Speech, Knowledge, Computer Vision, Language 등 엔씨소프트 AI 센터 내 각 분야 전문 연구진들이 AI에 대한 흥미로운 이야기를 들려드릴 예정입니다.
그 첫 번째로 소개할 내용은 '심층강화학습과 AI'에 대한 이야기입니다.
“인간이 진 것이 아니라 이세돌이 진 경기다.”
알파고의 충격이 있었던 지난 해, 이세돌 9단이 인터뷰에서 한 이야기입니다. 그러나 오늘 이 시점에는 이세돌 9단이 거둔 1승이, 사람이 바둑으로 거둔 유일한 승리가 되어버렸습니다.
다가올 미래는 인공지능의 시대입니다. 벌써 인공지능이 사람보다 잘하는 영역이 하나둘씩 계속 등장하고 있습니다.
알파고가 대중들에게는 인공지능에 대한 호기심과 충격을 심어줬다면, 머신러닝(Machine Learning) 관점에서 보면 강화학습(Reinforcement Learning)을 현실 세계에 등장시킨 사건이었습니다. 정말 충격적인 데뷔였습니다.
강화학습이란, 알려지지 않은 환경에서 액션(Action)을 수행하는 경험을 반복하며 얻는 보상(Reward)을 통해 학습해 나가는 방법입니다.
AI가 직접 시행착오(Trial-and-Error)를 반복하면서 자신이 한 행동에 대해 평가 받고, 점점 자신의 성능을 향상시켜 나가는 방식이지요.
강화학습에 의해 팬케이크 뒤집는 일을 학습하는 로봇
이번 기회에 심층강화학습(Deep Reinforcement Learning)에 대해서 같이 살펴볼 필요가 있다고 생각합니다.
심층강화학습은 강화학습(Reinforcement Learning)에 딥러닝(Deep Learning)을 적용한 기술을 일컫는 것으로, 2013년부터 본격적으로 소개되었고 알파고에도 핵심 기술로 적용됐습니다.
심층강화학습이란?
우선, 심층강화학습이란 무엇인지 알아보겠습니다.
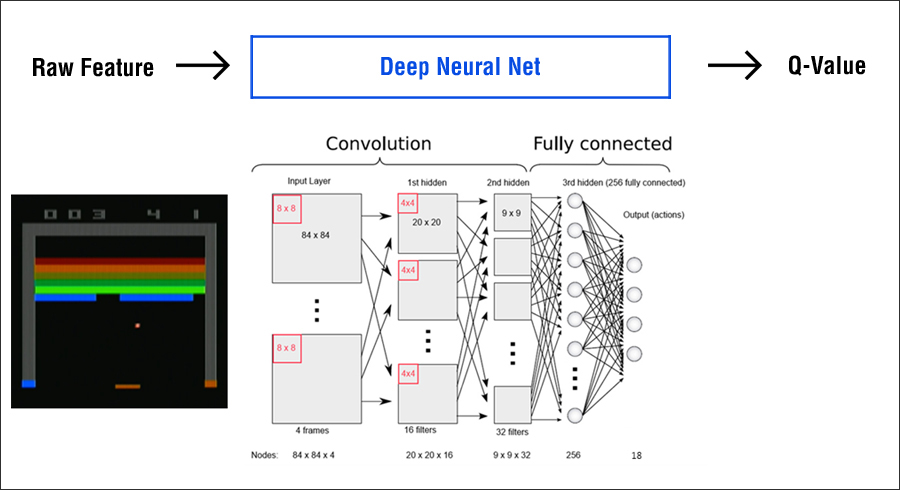
먼저 2013년에 발표된 논문 “Playing Atari with Deep Reinforcement Learning”의 Deep Q-Learning 을 기준으로 설명해보겠습니다.
이 논문은 사람이 게임을 하는 방식과 같이, 게임 화면의 Raw Image를 보여주고 스스로 경험을 통해 학습하게 하는 기술을 소개하였습니다.
아타리(Atari) 중 Breakout을 학습하는 영상
물론 심층신경망(Deep Neural Network)을 어떻게 활용하는지는 논문에 따라 다르지만 여기에서는, 한마디로 표현하자면 ‘Q-Value Approximation에 심층신경망(Deep Neural Network)을 사용한 것’이라고 할 수 있습니다. (※ Q Value: 특정 상태에서 액션을 수행했을 때 기대되는 보상의 총합)
강화학습 AI는 현재 상태에서 앞으로 얻을 수 있는 보상(Reward)이 얼마인지 알고 있고, 앞으로 얻을 수 있을 것으로 기대되는 보상(Reward)이 가장 높은 액션(Action)을 선택합니다.
가장 간단한 형태로는 아래와 같은 테이블처럼 만들고 업데이트 해나가면 됩니다. 그러나 이런 형태는 당연히 State가 너무나 방대하고 테이블이 너무 커지기 때문에, 이렇게 AI를 만드는 것은 사실상 불가능합니다.
Tabular Representation
대신 상태(State)와 액션(Action)을 입력해주면 기대 보상(Reward)을 Return해주는 함수를 학습을 통해 만들면 됩니다. 즉 이런 함수를 신경망(Neural Network)을 사용해서 만들어주는 것입니다.
Q Value를 회귀(Regression)하는 네트워크를 만드는 것이죠. 당연히 신경망(Neural Network)에 사용되는 입력 데이터(Feature)를 정교하게 직접 선별해야 하겠죠.
NFQ, Neural Fitted Q Learning
이 논문에서는 여기에 더 나아가서, 심층신경망(Deep Neural Network 또는 CNN, Convolutional Neural Network)을 활용해 게임 화면을 그대로 Raw Video Input으로 입력 받아 사용해서 Handcrafted-Feature를 선별하는 과정 없이 학습을 할 수 있도록 한 것이 Deep Q Learning입니다.
 Facebook
Facebook  KakaoTalk
KakaoTalk  LinkedIn
LinkedIn  Email
Email  Copy URL
Copy URL