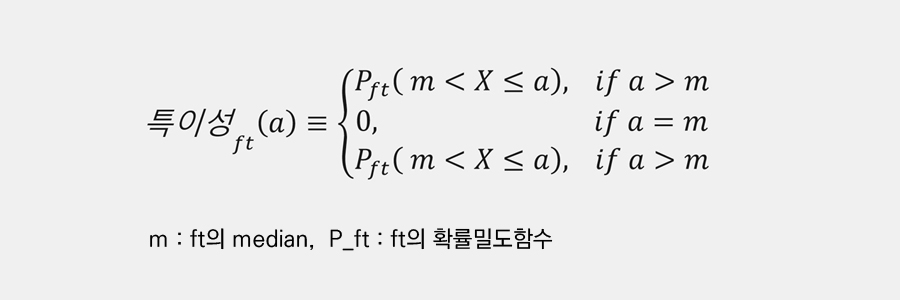AI에 대한 R&D를 선도하고 있는 엔씨소프트.
엔씨소프트는 AI센터와 NLP(자연어처리)센터를 주축으로 AI 연구개발을 진행하고 있습니다. 그 중 NLP센터 산하 언어(Language)AI랩과 지식(Knowledge)AI랩의 전문 연구진들은 각각 자연어처리(NLP) 기술과 지식 추론 기술을 활발히 연구하고 있습니다.
‘커뮤니케이션과 AI’ 세 번째 편에서는 야구 정보 서비스 ‘페이지(PAIGE)’의 기반이 되는 Knowledge AI 기술 중에서 재미있고 흥미로운 야구 소식과 정보를 찾아내는 과정을 다룹니다.
원활한 커뮤니케이션을 위한 Knowledge AI
엔씨소프트의 지식AI랩은 AI가 Knowledge를 수집/학습/추론하고 사용자의 의도에 적절하게 대응하는 Knowledge AI[1] 기술을 연구합니다.
일상에 존재하는 개별 데이터나 콘텐츠는 수집하는 대규모 용량에 비해, 개별적인 내용을 상세하게 담고 있거나 필요한 전체 Knowledge의 일부분만을 담고 있는 경우가 많습니다. 즉, 개별적으로 발생한 데이터를 단순히 수집한다고 해서 사람과의 원활하게 커뮤니케이션에 필요한 Knowledge를 확보했다고 하기 어렵습니다.
이러한 문제를 해결하기 위해 커뮤니케이션에 적합하게 Knowledge를 선별/요약/연결하는 Knowledge Structuring[2] 기술과 이를 적절하게 표현하고 설명하는 Knowledge Explanation[3] 기술을 중심으로 연구하고 있습니다.
Knowledge AI 기술은 적용 문제와 분석 대상 데이터에 따라 효과적인 방법이 다를 수 있습니다. 이뿐만 아니라 사람들도 동일한 내용을 보고/듣더라도 이해하고 생각하는 바가 달라 명확한 정답 데이터를 확보하기 어렵습니다. 따라서 Knowledge AI 기술을 확보하기 위해서 다소 추상적이면서 정답이 없는 문제를 구체적으로 정의하고, 이에 대한 합리적인 모델을 개발∙검증하면서 고도화하는 과정을 반복하고 있습니다.
[1] 유사한 기술 용어로 지식공학(Knowledge Engineering)이 있다.
[2] 수많은 개별 Knowledge를 연결하고 체계적으로 통합하여 구조화하고자 한다.
[3] Knowledge를 자연어로 표현하거나 시각화하여 효과적으로 전달하고자 한다.
흥미로운 소식 찾기
우리 주변에는 수많은 데이터와 다양한 읽을거리와 볼거리가 수시로 발생하고 있습니다. 페이지에서 다루는 야구 분야만 하더라도 많은 기록과 콘텐츠가 나옵니다. ‘어제 야구 경기 내용’은 물론 ‘한화 성적’이나 ‘김경문 감독 사퇴’ 등 너무도 많은 콘텐츠들이 쏟아져 나옵니다.
이때 여러 정보들 중에서 어떤 정보가 중요하고 재미있을지 판단하고, 보다 흥미로운 정보를 중심으로 커뮤니케이션 할 필요가 있습니다. 또 ‘어제 무슨 일 있었어?’, ‘재미있는 소식 없어?’ 등과 같이 사용자들의 불분명한 요청에 대응하기 위해서도 흥미로운 소식을 탐지해야 합니다. 이를 위해 데이터나 콘텐츠의 흥미도를 측정/추론하고, 사용자가 관심 있을만한 내용을 선정하는 방안을 마련해야 합니다.
페이지를 개발하면서도 선수 소개, HOT한 선수 보기, 경기 관전 포인트, 하이라이트 장면 선정 및 주요 정보 제공을 할 때 관련 기술을 적용했습니다. 아래 단락에서 좀 더 자세한 내용을 살펴보도록 하겠습니다.
다양한 관점에서의 흥미도 측정
흥미도를 정량적으로 측정하는 방법은 다양합니다. 데이터의 특성이나 흥미도에 대한 정의에 따라 다를 수 있습니다. 물론 흥미도의 기준에 정답이 없으며, 개인에 따라서도 차이가 있을 것 입니다.
그래서 흥미도를 여러 관점에서 정의하고, 이를 각각 정량적으로 모델링 하였습니다. 우선 흥미도를 크게 대표성, 최신성(Recency), 특이성, 변동성, 유용성, 미지성의 관점으로 구성하였습니다.
대표성
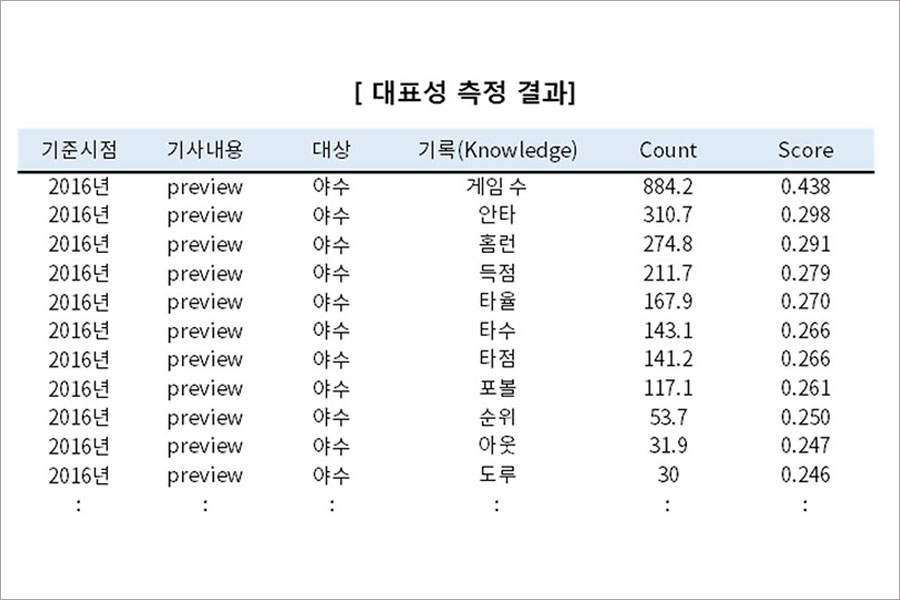
데이터의 대표성을 측정하기 위해 야구 뉴스기사에서 해당 데이터를 언급한 빈도를 통해 정량적으로 측정하였습니다.
1) 뉴스기사 텍스트에 대한 자연어 처리
뉴스기사 텍스트로부터 분석 대상 데이터를 추출하기 위해 개체명 인식, 형태소/품사분석 및 의존구조분석(Dependency Paring) 등을 진행합니다. 단순히 키워드의 노출 횟수를 집계하는 것이 아닌 문서의 주제와 언급되는 대상에 따라 대표성을 측정하였습니다.
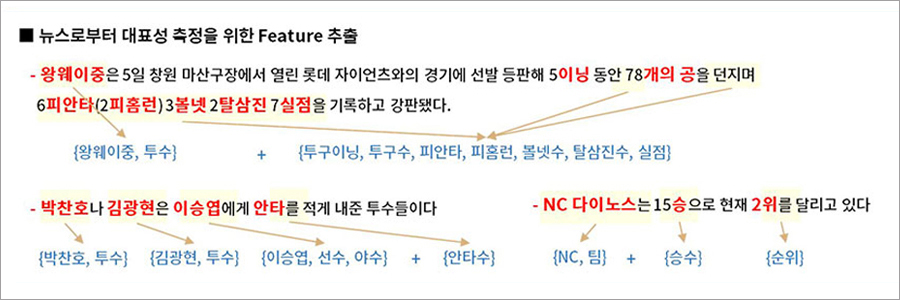
2) 기사의 내용/대상에 따른 대표성 집계 및 스코어링(Scoring)
- 뉴스기사의 내용(프리뷰/경기중/리뷰)과 대상(팀/투수/야수)에 따라서 언급되는 정보를 집계합니다. 문장 내에서 함께 언급되는 기록의 수, 문장내 명확한 주어가 없는 경우 등을 고려하였습니다.
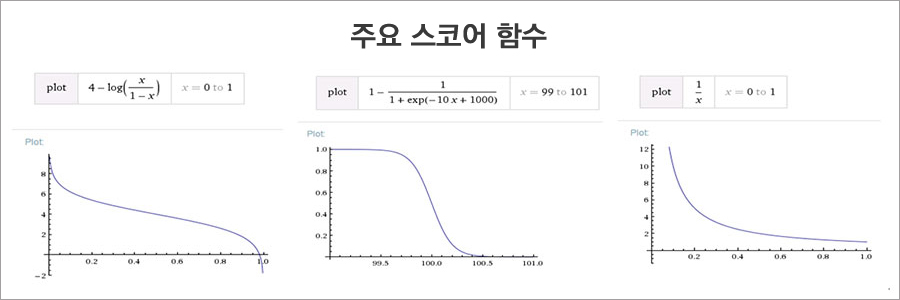
- 다른 관점에서의 흥미도 지표와 결합하기 위해 대표성을 정규화하여 스코어링합니다. 데이터 분포의 특성을 고려하여 아래의 함수를 대상으로 적합하여 스코어링하였습니다.
최신성(Recency)
시간의 흐름에 따라 최신성 관점에서의 흥미도는 감소하는 것으로 가정하였습니다. 이벤트의 화제성이 얼마나 유지되는지를 관련 데이터로 확인해보고 이를 참고하여 적절한 스코어링 함수(Scoring function)를 도출하는 과정으로 진행했습니다.
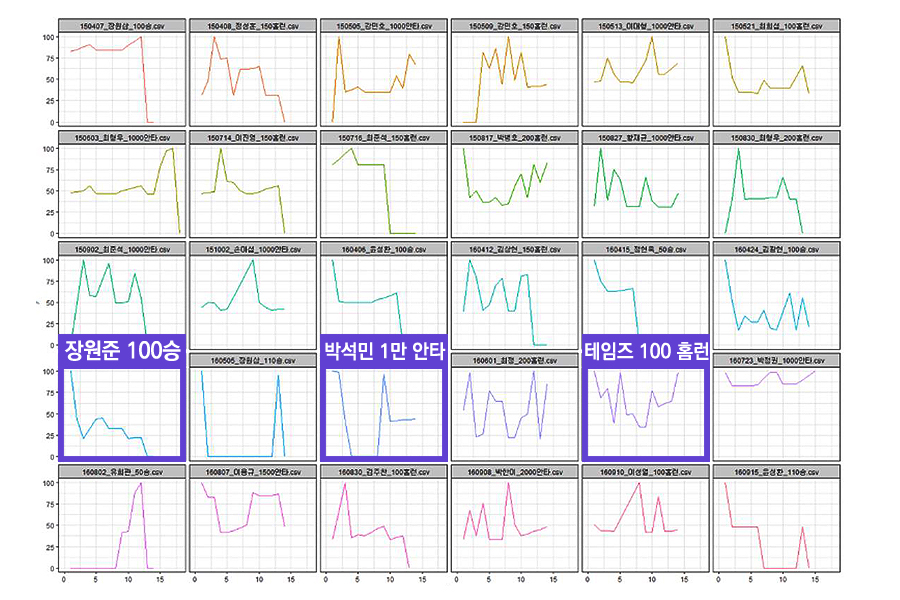
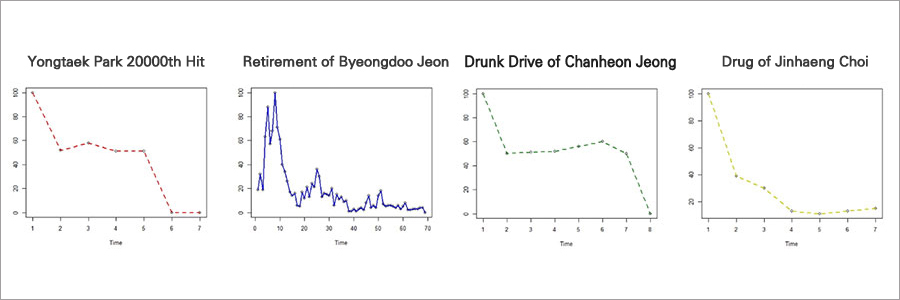
1) KBO 야구 이벤트의 화제성 감소 패턴 조사
- 박석민 1,000안타, 테임즈 100홈런, 장원준 100승과 같은 KBO의 이벤트에 대한 시간 흐름에 따른 구글 트렌드 패턴 조사
- 박용택 2만 번째 히트, 전병두 은퇴, 정찬헌 음주운전, 최진행 도핑사건 이슈 등의 사건/사고에 관련된 키워드의 시간 흐름에 따른 노출 패턴 조사
2) 최신성을 표현하는 스코어링 함수 적합
이벤트의 화제성, 유형 등에 따라 Decaying Curve의 베리에이션(Variation)이 크게 나타납니다. 하지만 대체적으로 ▲초반에 급격히 감소하다 중간에 유지하는 경우 ▲초반에 유지되다가 이후 급격히 감소하는 경우 ▲1/x 함수 형태로 급격히 감소하는 경우로 분류할 수 있습니다. 이러한 패턴에 따라 적절한 함수를 선정하여 최신성을 스코어링하였습니다.
특이성
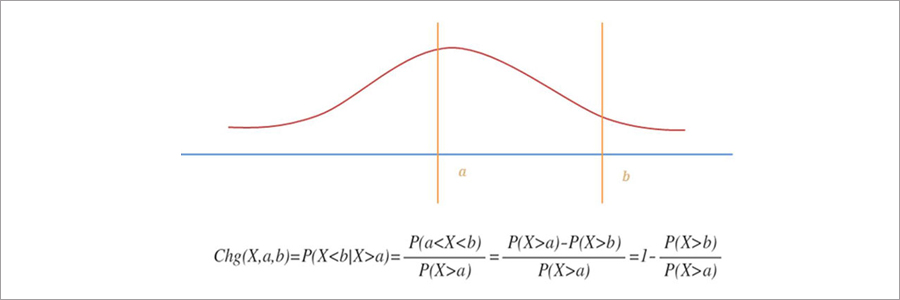
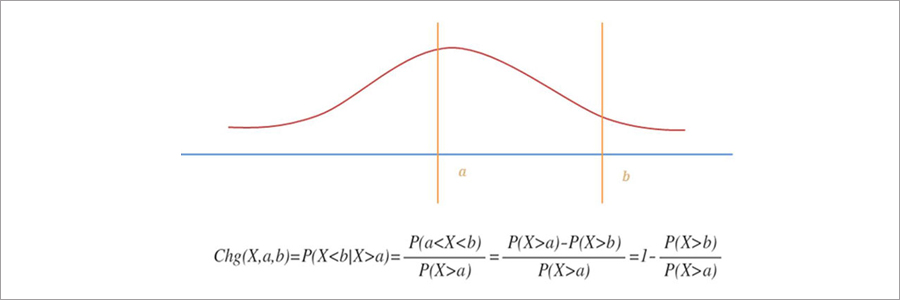
사건의 발생 확률이 낮을 수록 해당 사건의 특이성이 높아지고 흥미로울 것으로 생각하였습니다. 특이성을 측정하기 위해서 각 사건이 발생할 확률분포를 추정하고, 해당 확률분포의 중앙값(median)이 가장 덜 특이하고 발생 확률이 낮을수록 특이하도록 스코어링 함수를 적용하였습니다.
타율과 같은 임의의 기록 ft가 P_ft라는 확률밀도함수를 가지는 확률 변수라면, 이 때의 특이성을 다음과 같이 정의하였습니다.
위의 그림은 (타율이 엄청 높거나 낮은 것처럼) 발생하기 어려운 사건이 발생할수록 특이성이 높아지도록 정의된 함수입니다. 이 함수는 각 기록의 확률밀도함수만 추정할 수 있다면 서로 다른 기록간에도 비교가 가능하다는 장점이 있습니다. 이러한 정의에 따라 특이성을 계산하기 위해 각 기록의 확률밀도함수(혹은 distribution)를 추정했습니다.
1) 특정 시점의 데이터로 구한 empirical distribution의 활용
단순하게 생각할 수 있는 방법으로는 현재 시점 t에서 기록된 모든 선수들의 데이터를 이용하여 distribution F를 추정하는 방법입니다. 예를 들어 특정 시점에서 타율이 0.35이하인 선수가 전체 선수의 90%라면 타율이 0.35이하일 확률을 0.9로 추정하는 방식입니다. 그 식은 아래와 같습니다.
하지만 한 시즌에 활동하는 선수의 수가 많지 않아 특정시점에 활용할 수 있는 데이터 수가 너무 적고, 3루타∙도루∙병살타와 같이 실제 발생하는 경우가 드문 기록들이 많아 Empirical Distribution으로 분포를 추정하기 어려운 문제가 있었습니다.
2) 기록별 발생 특성을 고려한 분포 추정
Empirical Distribution으로 분포를 추정하기에 어려워 적절한 분포형태를 가정한 후 분포를 추정하는 방법을 사용했습니다. 기록에 관련된 이벤트의 발생 특성을 고려하여 크게 베르누이(Bernoulli) 특성, 누적 특성, 비율 특성으로 분류하고 각각의 특성에 따라 분포 형태를 달리 가정하여 추정했습니다.
(A) 누적 특성을 가지는 기록의 분포추정
- 타석 수, 투구이닝 등과 같이 경기 시간에 따라 증가하는 기록은 한 경기에서 0~10회 내외의 값을 가집니다.
- 이런 누적 특성을 가지는 기록은 1경기에서 발생되는 횟수를 이산형 확률변수로 가정한 후 해당 기록의 분포를 다항분포(Multinomial Distribution)로 추정했습니다. Multinomial의 모수 확률p는 선수 별로 다르다는 점을 반영하기 위해 Dirichlet-multinomial 분포와 Mixture multinomial 분포 두 가지 안을 검토해보았습니다.
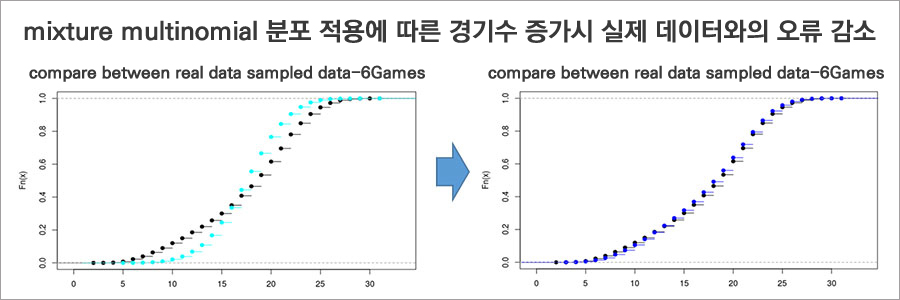
- Dirichlet-Multinomial 분포에서 추정된 모수(p ̃와 α ̃)를 이용하여 1경기에서 발생하는 ft값을 샘플링한 분포와 실제 데이터 분포를 비교한 결과, 두 분포가 유사한 것을 확인할 수 있었습니다. 그런데 여기서 사용한 모수를 이용하여 3경기 또는 6경기에 대한 데이터를 생성한 후 실제 데이터의 분포와 비교해보면 상당한 차이가 발생하는 것을 확인하였습니다.
- 선수별 기록 확률p가 Dirichlet 분포를 따른다는 가정을 버리고, 선수별 경기 참여 횟수를 바탕으로 한 Mixture Multinomial 분포를 가정하여 발생 확률p를 추정했습니다. 이렇게 추정된 모수를 이용해 생성한 분포는 Dirichlet 가정의 분포보다 실제 데이터를 잘 표현하는 것을 확인할 수 있습니다.
(B) 베르누이 분포 특성을 가지는 기록의 추정
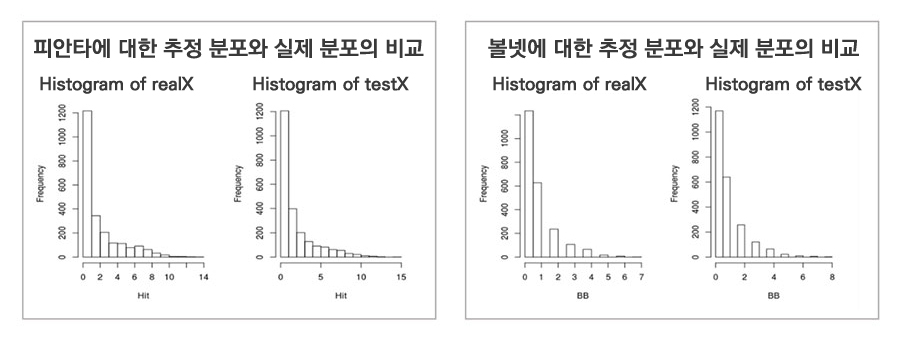
- 삼진, 볼넷, 피안타, 피홈런 등과 같이 주어진 기회(타석 등)에서의 성공률을 추정해야 하는 기록들이 있습니다.
- 이러한 특성을 보이는 기록 ft는 이항분포(Binomial Distribution)를 따른다고 가정하고 분포를 추정했습니다. 이는 x ~ binomial(n, p)를 의미합니다.
- Binomial 분포의 모수인 기회 n과 성공 확률 p 또한 선수별로 달라질 수 있기 때문에 확률변수라고 생각할 수 있습니다.
∙ n은 타석, 투구 수 등 누적 특성의 기록에 해당하므로 ‘(A) 누적 특성의 기록’을 이용하여 분포를 추정합니다.
∙ 선수별 이벤트 성공 발생확률 p(홈런확률, 삼진확률 등)는 계산상의 편의를 위해, 일반적으로 많이 사용하는 beta 분포를 가정했습니다. 이는 p ~ beta(α, β)를 의미합니다.
- 아래의 그래프를 통해 추정된 데이터와 실제 데이터의 분포가 유사하다는 것을 확인할 수 있습니다.
(C) 비율 및 연속변수 기록의 분포추정
- WHIP[4], OPS[5] 등과 같이 다른 기록의 연산을 통해 만들어지는 기록 등은 별도의 방법을 활용해야 합니다.
- (A), (B)를 통해 추정된 기록 분포를 기반으로 샘플링을 통해 해당 기록에 대한 분포를 추정하는 방안을 생각할 수 있지만 이렇게 추정된 분포와 실제 분포는 큰 차이가 있습니다. 예를 들어 ‘삼진’과 ‘볼넷’은 통상적으로 연관성이 높은 기록인데(볼넷이 많으면 삼진이 적고 볼넷이 적으면 삼진이 많은), 이를 각각을 샘플링하여 ‘볼넷 대비 삼진수’ 비율의 분포를 추정하면 실제 분포와 차이를 보입니다.
- 연산에 사용된 두 개 이상의 기록을 동시에 샘플링하여 분포를 계산하기 위해서는 두 기록의 join distribution을 알아야 정확하게 분포를 추정할 수 있는데 이는 어려운 작업입니다. 이렇게 분포를 추정하기 어려운 기록들은 작업의 편의상 empirical distribution을 사용했습니다. 이러한 기록들은 이슈가 상대적으로 적어 특이성 측정에 큰 문제가 없었습니다.
[4] Walks plus Hits per Inning Pitched. 이닝당 출루 허용율
[5] On-base Plus Slugging. 출루율 + 장타율
변동성
변동성 관점에서의 흥미도를 측정하기 위해 기록이 이전 시점에 비해 얼마나 많이 변했는지를 측정해서 변동량이 클수록 높아지도록 정의하였습니다.
이때 ‘평균 자책점 1.2점 감소’나 ‘이닝당 삼진 개수 0.4개 감소’ 등 서로 다른 특성들의 변화량을 함께 비교할 수 있어야 할 뿐만 아니라 이전 시점이 어땠는지를 반영할 수 있도록 설계했습니다. 앞선 3경기에서 안타를 3개 치던 선수가 최근 3경기에서 4개 치는 것보다, 앞선 3경기에서 안타를 5개 치던 선수가 안타를 6개 치는 게 현실에서 더 일어나기 힘들기 때문입니다.
두 가지 이슈를 모두 해결하기 위해, 앞에서 특이성을 계산할 때 추정한 각 기록별 분포로부터 이전 시점의 기록 a 에서 b 로 변경된 경우에 대한 조건부 확률을 계산함으로써 변동성을 측정하였습니다.
흥미도 추정
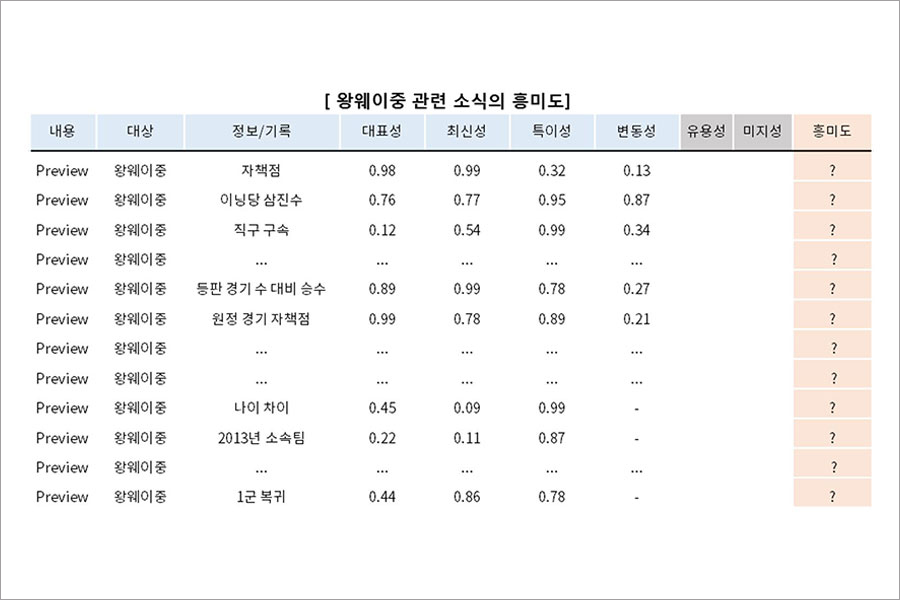
앞서 정리한 대표성, 최신성, 특이성, 변동성에 대한 모델링 결과를 왕웨이중 기록 Knowledge에 적용한 결과는 아래와 같습니다.
흥미도에 대한 정의 중에서 유용성과 미지성은 개인의 상황 요인이 매우 큰 요소이므로, 추후 연재할 개인화/큐레이션(Curation) 부분에서 공유하도록 하겠습니다.
대표성, 최신성, 특이성, 변동성 등에 대한 스코어가 측정이 되면, 이를 조합하여 최종 흥미도를 추정하는 문제가 남습니다. 초반에 언급한 Knowledge AI 기술에서 정답 데이터를 확보하기 어렵다는 이슈가 여기에도 동일하게 존재합니다.
이를 위해 페이지 서비스를 출시하였고 실제 사용자들의 이용로그를 바탕으로 다양한 통계기법이나 강화학습을 포함한 기계학습을 활용하여 접근하고 있습니다. 실제 사용자 피드백 활용을 통한 최적화 과정 또한 다음 연재에서 공유할 예정입니다.
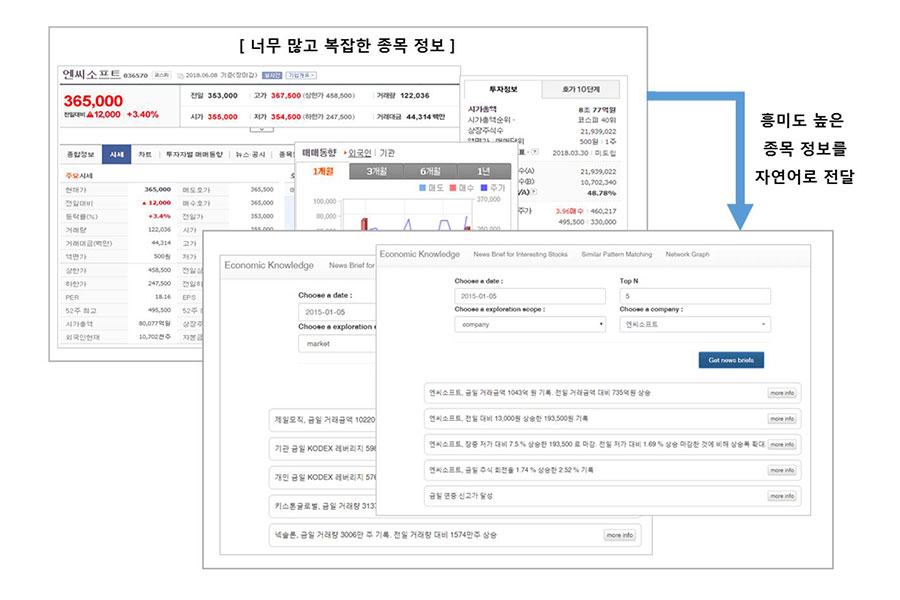
증권 시장 내 개별 종목에 대한 흥미로운 종목 정보 생성
앞서 살펴본 야구 Knowledge에 대한 흥미도 측정 모델은 경제/금융 분야에 확대 적용할 수 있습니다. 증권 시장에는 야구보다 훨씬 많은 데이터와 정보가 있고, 그 특성도 야구 분야와는 다른 점이 많기 때문에 흥미도 측정 모델을 보다 고도화하기 할 수 있습니다.
야구 기반으로 구축한 흥미도 측정 모델을 증권시장에 적용하는 과정에서 여러 이슈를 확인하였으나 그 중에서 가장 큰 이슈 두 가지는 ▲데이터 분포의 차이 ▲변동성 측정에서의 이슈였습니다.
- 데이터 분포의 차이: 선수들의 플레이를 통해 발생하는 야구 데이터는 대부분 널리 알려진 확률 분포를 기반으로 모델링 할 수 있었고, 주요 지표들이 가운데가 볼록한 형태의 분포를 따르기 때문에 이러한 가정을 바탕으로 흥미도 측정 모델을 구성하였습니다. 그러나 증권시장의 경우에는 훨씬 다양한 데이터 분포를 보여 야구 흥미도 측정 모델을 그대로 적용하기 어려웠습니다.
- 변동성 측정에서의 이슈: 변동성 관점에서는 야구 데이터와 다른 특성을 보이는 종목 정보 데이터가 있습니다. 52주 최고/최저가, 목표주가, 상장주식수 등 자주 변동하지는 않지만, 변동하면 매우 유의미한 정보인 경우에 대한 추가 모델링이 필요하였습니다.
이러한 이슈의 해결을 통해 매우 복잡하고 수많은 정보가 노출되고 있는 증권시장의 종목정보를 흥미도 기준에 따라 좀 더 효과적으로 제공하는 방안을 시도하고 있습니다.
앞에서 공유한 방법 외에도 다양한 데이터 형식에 대해 보다 정교하게 모델링하고 일반화할 수 있는 흥미로운 Knowledge 탐지 방안들을 시도하고 있습니다.
Big Tensor Mining[6]을 통한 상황(Context)에 따른 흥미로운 정보 탐색
대부분의 분석 대상 데이터들은 많은 상황 변수를 갖고 있는 다차원 데이터입니다. 야구 데이터도 상대팀, 상대선수, 이닝, 점수, 주자상황, 볼카운트 등의 다양한 상황을 포함하고 있습니다.
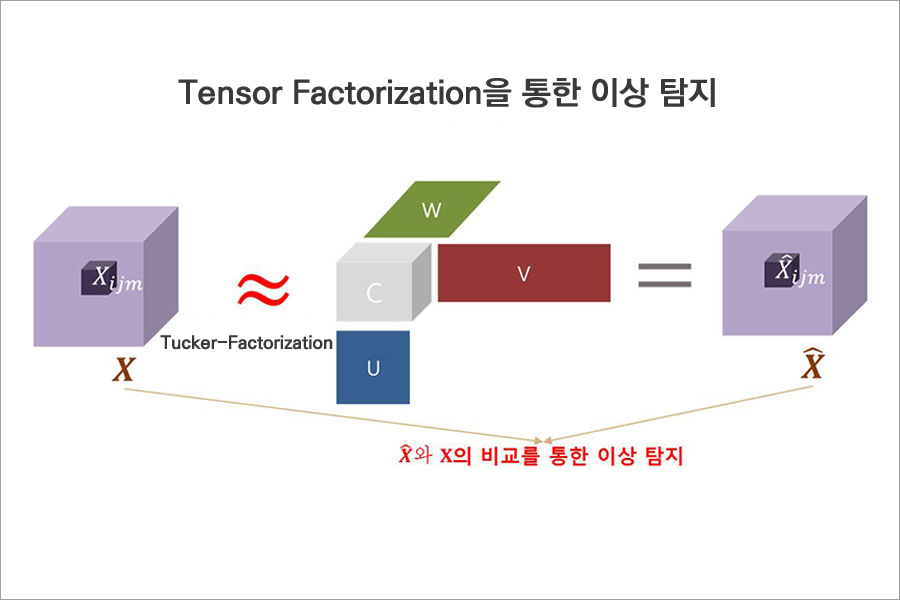
이러한 고차원 데이터를 효과적으로 표현하고 분석하기 위해 Tensor Mining을 진행하였습니다. 특히 Tensor Factorization[7]을 통해 고차원 데이터의 경향성을 모델링하고, 이에 벗어나는 특이 패턴을 탐지하여 흥미로운 정보 탐색에 적용하였습니다.
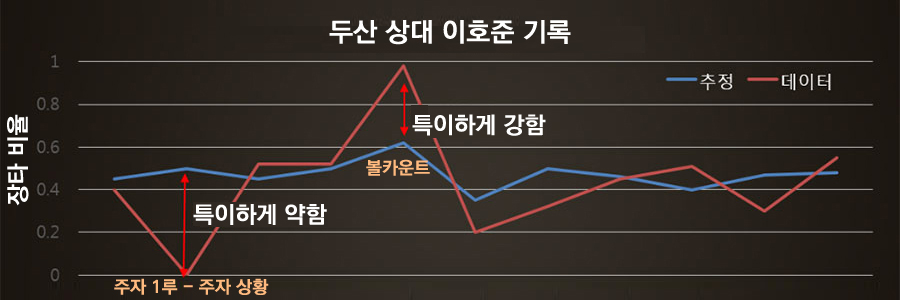
타자의 상황별 데이터에서 특이한 기록 패턴을 탐지하는 모델을 개발하였습니다.
1) 타자의 상황별 기록 Tensor 구성
2) Tensor Factorization을 통해 실제 데이터의 일반적인 경향성을 모델링
3) 실제 Tensor와 재구성된 추정 Tensor의 비교를 통해 특이한 결과 도출
결과 도출 예시) 이호준은 두산 상대로 타자가 유리한 볼카운트 상황에서는 유독 장타율이 높아 강한 모습을 보이고 있으며, 주자 1루 상황에서는 특히 낮은 장타율을 기록했습니다.
[6] 데이터 분석 기술인 Data Mining에서 다차원 데이터인 Tensor를 강조한 기술 용어
[7] 주요 참고 문헌: Cichocki, A., Zdunek, R., Phan, A. H. and Amari, S., “Nonnegative Matrix and Tensor Factorizations: Applications to Exploratory Multi-Way Data Analysis and Blind Source Separation”, John Wiley and Sons, 2009
Sequence 데이터에서의 흥미로운 정보 탐색
야구 경기 데이터, 게임 플레이 데이터와 같이 시간의 흐름에 따라 발생하는 시퀀스(Sequence) 데이터를 대상으로 흥미도를 추정하고 흥미로운 정보를 선정하기 위한 모델을 개발하였습니다.
1) 야구 하이라이트 장면 탐지
경기가 진행되면서 발생하는 야구 데이터에서 하이라이트(중요한/흥미로운) 상황을 탐지하는 방안을 고민하였습니다.
기존에는 매번 사람이 편집하거나, 야구 통계에 기반한 경기 상황 중요도를 나타내는 LI(Leverage Index)를 기준으로 주요 장면을 선정하였습니다. 그러나 LI값은 승부에 영향을 주는 정도만을 평가하기 때문에, 승부에 미치는 영향은 적더라도 사용자들이 관심 있어 할만한 3타자 연속 삼진, 병살플레이, 보살 등과 같은 상황을 탐지하는 데는 한계가 있습니다.
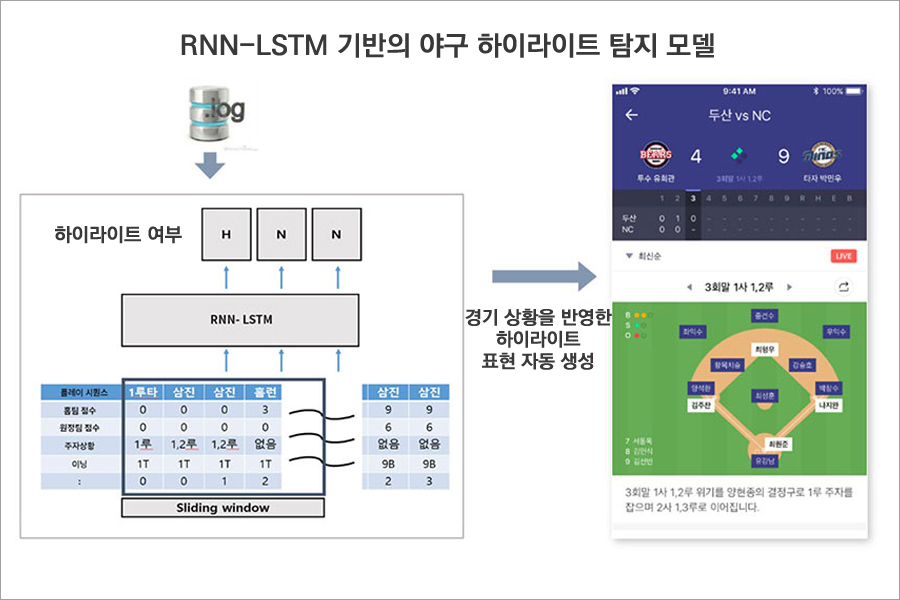
이를 개선하기 위해 사람들이 선정한 하이라이트 장면을 기계학습(딥러닝)을 통해 학습하여 새로운 야구 시퀀스 데이터에 대해서 수작업 없이 실시간으로 하이라이트 장면을 선정하는 모델을 개발하였습니다.
경기 상황과 플레이 결과를 입력 데이터로 하여 사람에 의해 평가된 하이라이트 상황 여부를 분류하도록 학습하였습니다. 전후 상황을 반영하기 위해 경기 흐름에 따른 RNN-LSTM(Recurrent Neural Networks & Long Short-term Memory) 모델을 활용하였습니다. 좋은 성능을 확보하기 위해서는, 딥러닝 모델의 수많은 파라미터를 최적화하는 것은 물론, 경기 중에 발생하는 여러 상황을 플레이 단위 학습 데이터에 반영하기 위한 많은 실험과 노력이 필요하였습니다.
2) 게임에서의 흥미로운 플레이 탐지
야구 하이라이트 탐지 모델을 게임 도메인에 확대 적용하고 있습니다. 게임 플레이에서는 사람에 의해 하이라이트 상황을 탐지하여 활용하기 보다는, 게임 도메인에 적합한 흥미로운 플레이를 별도로 도출하였습니다.
게임 플레이에서 흥미로운 상황을 (A) 퀘스트/미션을 수행하는데 중요한 플레이, (B) 통상적이지 않는 특이한 플레이 패턴으로 정의하였습니다. 이러한 의도에 부합하도록 아래와 같이 야구 하이라이트 탐지 모델을 수정/보완하였습니다.
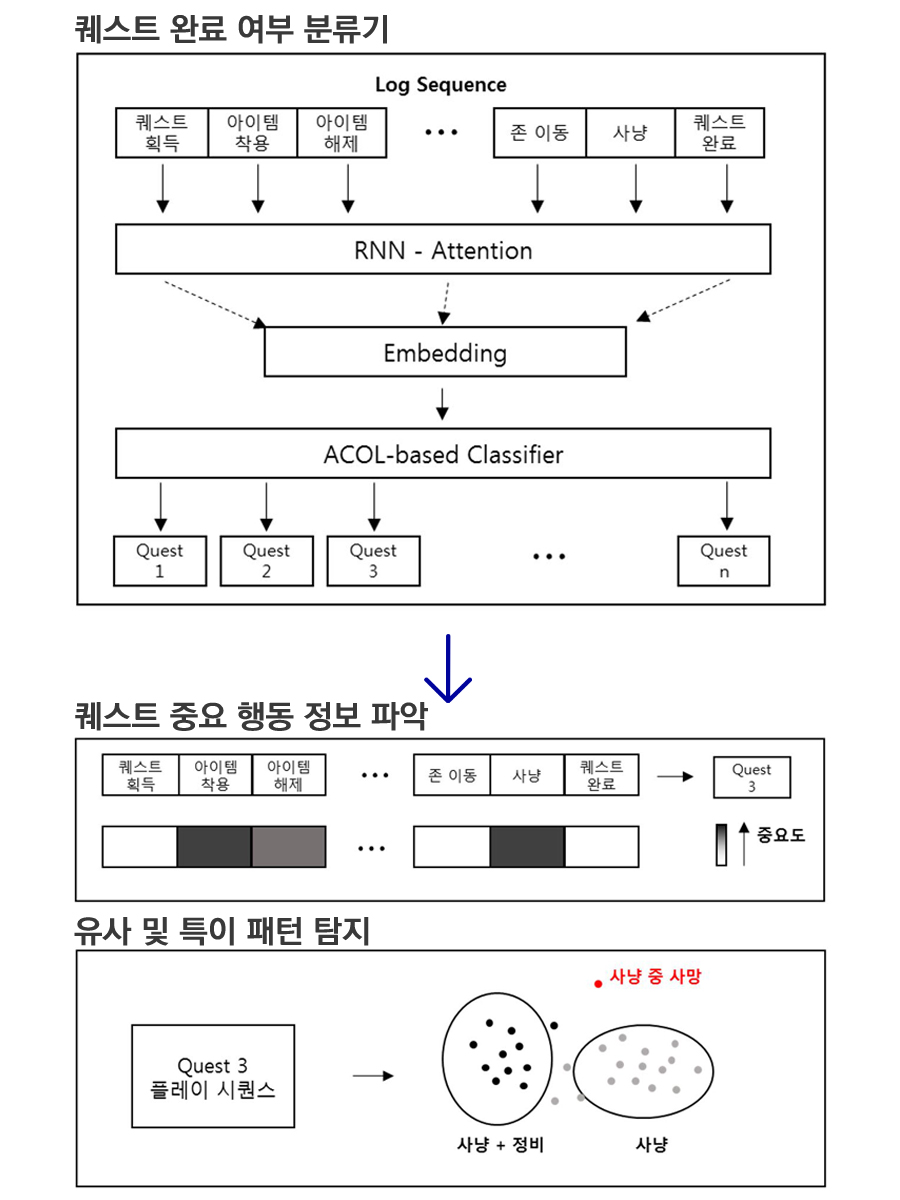
(A) 퀘스트 수행에 중요한 플레이 탐지
플레이 시퀀스가 퀘스트를 완료하는데 중요한지를 판별하기 위해, RNN-Attention모델 기반으로 플레이 이후에 완료한 퀘스트 분류기를 구성하고, Attention 수치를 통해 퀘스트 완료에 중요한 영향을 주는 시퀀스를 탐지하였습니다.
(B) 특이한 플레이 패턴 탐지
(A) 모델에서 시퀀스로그를 임베딩(embedding)하고, 임베딩 공간에서 시퀀스 로그를 클러스터링(clustering)하여 특이한 패턴을 보이는 아웃라이어(Outlier) 플레이를 탐지하고자 하였습니다. 특히 동일한 클래스에 존재하는 하위 클러스터를 효과적으로 구성하기 위해 Auto-Clustering Output Layer[8]를 추가하여 모델을 개발하였습니다.
[8] 주요 참고 문헌: Ozsel Kilinc, Ismail Uysal, “Auto-clustering Output Layer: Automatic Learning of Latent Annotations in Neural Networks”, Proceedings of IEEE Transactions on Neural Networks and Learning Systems, 2017
문서 내용의 흥미도 추정 모델
앞에서는 개별 데이터에서 사용자들이 흥미 있어 할만한 정보를 추론하는 과정에 대해 정리해보았습니다.
이제는 개별 데이터뿐만 아니라 자연어로 표현되어 있는 문서의 내용에 기반하여 흥미도를 추정하는 시도에 대해 설명하겠습니다. 문서 내용의 흥미도 추정을 통해서 뉴스 기사뿐만 아니라 실시간으로 쏟아지고 있는 커뮤니티 게시글, SNS글 중에서 관심 있을만한 재미있는 내용을 Knowledge로 활용하거나 사용자들에게 전달하고자 합니다.
1) 야구 커뮤니티에서 흥미로운 게시글 찾기
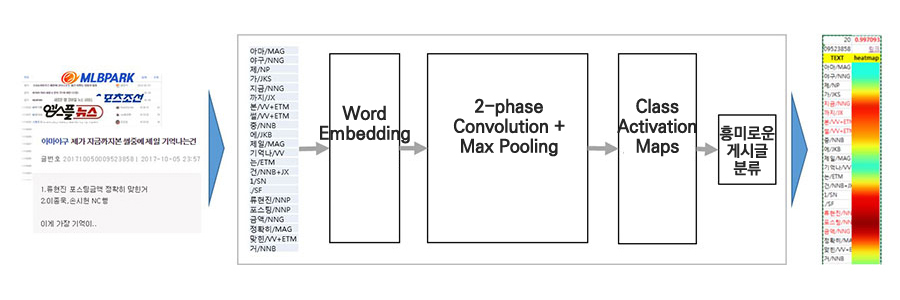
온라인 커뮤니티에서, 사용자들은 커뮤니티 게시글의 흥미로운 제목에 끌려 게시글을 읽고 댓글을 달게 됩니다. 이러한 근거를 바탕으로 우리는 커뮤니티 게시글의 제목을 분석하여 이후 조회수/댓글수가 많을 것이라 예측하는 ‘CNN+CAM’ 모델을 구성하였습니다.
두 개의 층으로 쌓은 2-phase CNN(Convolutional Neural Networks) 모델을 구축하여, 야구 커뮤니티에서 과거 1년간 조회수/댓글이 많았던 제목들을 학습하였습니다. 추가적으로 CAM(Class Activation Map)[9] 기법을 바탕으로 사용자들이 제목의 어떤 부분을 흥미롭게 보고 있는지 Heatmap으로 시각화하여 분석했습니다.
이를 통해 글의 내용만으로 조회수/댓글수 기준 상위2%에 해당하는 흥미로운 글을 80% 이상의 Precision 정확도[10]로 예측할 수 있었습니다. 페이지에서의 흥미로운 콘텐츠 큐레이션에 이러한 모델이 적용될 예정입니다.
2) 게임 커뮤니티에서 흥미로운 게시글 찾기
야구 커뮤니티에서 흥미로운 게시글 찾는 모델을 게임 커뮤니티(리니지M)로 확대 적용해보았습니다. 데이터 전처리 및 Feature Engineering[11] 측면에서 장점이 있는 딥러닝 모델을 기반으로 하고 있어 비교적 간단한 파라미터 최적화 과정만으로도 유사한 성능을 확보할 수 있었습니다.
또한 CAM을 바탕으로 야구커뮤니티와는 다른 그 커뮤니티만의 흥미로운 상용구도 찾을 수 있고, 해당 기간 내에 커뮤니티의 핫이슈를 알아낼 수 있습니다. 이렇듯 명확하게 정의하기 어려운 자연어 문서의 경우에도 얼마든지 흥미도를 추정해 볼 수 있습니다.
[9] 주요 참고 문헌: Zhou, Bolei, et al. "Learning deep features for discriminative localization." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016
[10] Precision 정확도: 흥미로운 글로 예측한 것 중에서 실제로 흥미로운 글에 해당하는 정확도
[11] 유용한 입력 데이터를 구성하기 위한 변수 생성, 가공, 제외, 선택 등의 작업
지금까지 엔씨소프트의 지식AI랩에서 흥미로운 소식을 찾기 위해 진행한 주요 내용을 정리해보았습니다. 현재에도 다양한 영역에서 흥미로운 소식을 찾기 위한 추가적인 방법들을 시도하고 있습니다. 또한 정형 데이터, 자연어 문서뿐만 아니라 이미지∙동영상 콘텐츠에서도 흥미로운 내용을 파악하기 위해 연구하고 있습니다.
Knowledge AI 기술에 대한 다음 연재에서는 수많은 Knowledge를 효과적으로 요약하고 적절하게 표현하기 위해 진행한 내용들을 공유하겠습니다.
정세희
NLP Center Knowledge AI Lab 실장.
이동통신, 커머스, 제조, 음악, 금융, 게임 등
다양한 비즈니스의 데이터를 분석하고 모델링하여
더욱 인텔리전트한 서비스를 만들어 왔습니다.
지금은 훌륭한 동료들과 즐겁게 연구하며
재미있는 AI를 만들어가고 있습니다.
NLP Center Knowledge AI Lab 실장.
이동통신, 커머스, 제조, 음악, 금융, 게임 등
다양한 비즈니스의 데이터를 분석하고 모델링하여
더욱 인텔리전트한 서비스를 만들어 왔습니다.
지금은 훌륭한 동료들과 즐겁게 연구하며
재미있는 AI를 만들어가고 있습니다.
 Facebook
Facebook  KakaoTalk
KakaoTalk  LinkedIn
LinkedIn  Email
Email  Copy URL
Copy URL