AI에 대한 R&D를 선도하고 있는 엔씨소프트.
엔씨소프트의 NLP(자연어처리) 센터는 언어(Language)AI랩과 지식(Knowledge)AI랩의 전문 연구진들이 각각 자연어처리(NLP) 기술과 지식 추론 기술을 활발히 연구하고 있습니다.
‘커뮤니케이션과 AI’ 다섯 번째 편에서는 방대한 야구 관련 데이터를 보기 좋고 이해하기 쉽게 요약하는 Knowledge 기술에 대해 자세히 살펴보겠습니다.
우리 주변에서는 수시로 다양한 일들이 발생합니다. AI는 이를 데이터나 문서 등을 통해 파악하고 사용자와 커뮤니케이션 할 수 있어야 합니다.
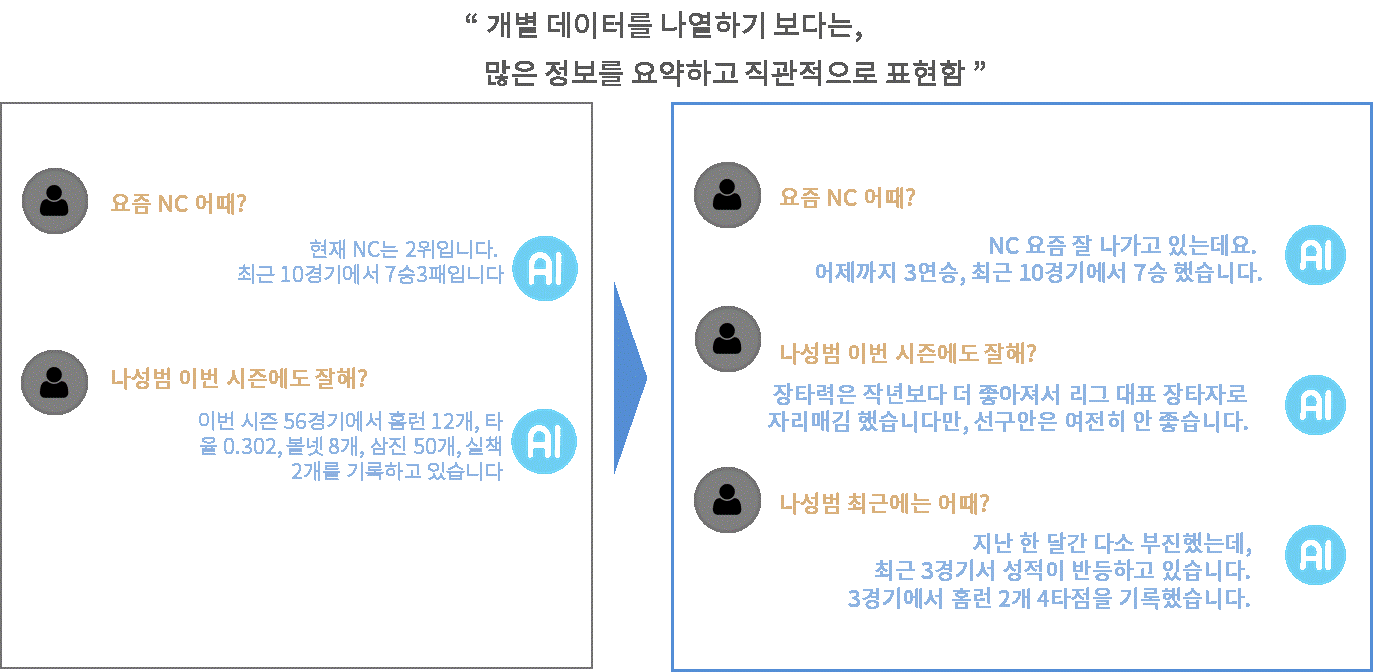
이때 원활한 커뮤니케이션을 위해서는 사용자들이 쉽게 이해할 수 있는 요약된 Knowledge가 필요합니다. 가령, 사용자들은 NC 다이노스의 승률, 홈런수, 방어율 등의 상세한 개별 데이터에 대해 이야기하지만, 동시에 “이번 시즌 NC가 잘하고 있는지” “NC의 최근 타격은 어떤지” 등과 같이 정성적이고 직관적으로도 이야기하기 때문입니다.
우리가 수집할 수 있는 대부분의 데이터는 상세로그, 정량수치, 개별문서 등이 있습니다. 따라서 이러한 원천데이터(Raw Data)를 필요에 따라 적절한 수준으로 요약하고 직관적으로 표현하여 커뮤니케이션을 위한 Knowledge를 생성할 수 있어야 합니다. Knowledge AI Lab에서는 이러한 목적으로 데이터 요약 및 직관적 표현 기술에 대해 연구하고 있습니다.
시계열 데이터 요약하기
시계열 데이터란 일정한 시간 간격으로 배열된 데이터입니다. 시계열 데이터의 예로는 주가 데이터, 센서 데이터, 클릭 스트림 데이터 등이 있으며, 현재 페이지 요약에서 볼 수 있는 ‘승리 팀의 승률 추이’도 시계열 데이터라고 할 수 있습니다.
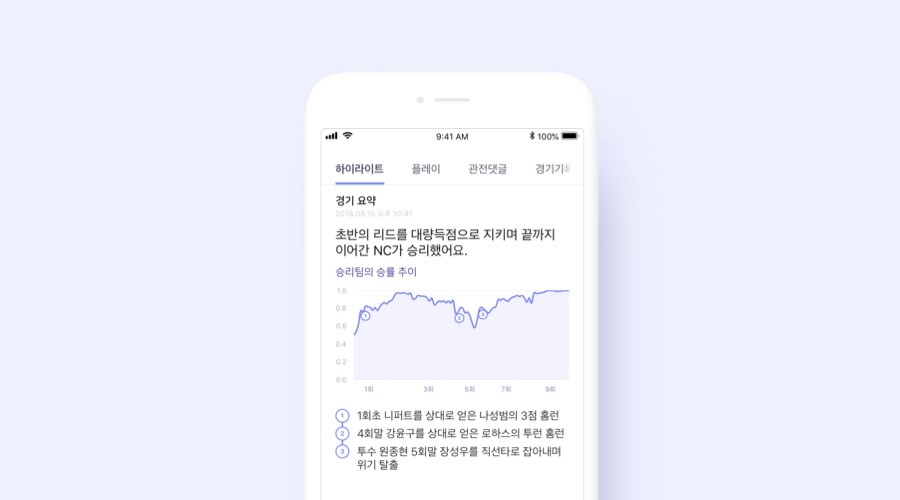
특히 숫자로 구성된 시계열 데이터를 사용자에게 바로 제시해서는 데이터에 담긴 의미를 전달하지 못하는 경우가 많습니다. 예를 들어, 엔씨의 지난 3달 간의 주가 움직임을 60개 숫자로 사용자에게 보여준다면, 주가가 어떻게 움직였는지 한눈에 파악하기 어렵습니다. 그보다는 ‘엔씨의 주가가 7월 중순 고점을 찍었다가 하락한 후 최근 다시 상승하고 있다’처럼 시계열 데이터가 가진 특징을 요약하여 표현하는 것이 사용자가 데이터를 이해하는 데 훨씬 도움이 될 것입니다.
그러므로 시계열 데이터가 어떤 형태들을 가지고 있는지 파악하여 각각의 형태에 맞게 데이터를 요약하는 기술을 개발하는 것이 필요합니다. 이러한 경우에 시도할 수 있는 방법론이 군집화 (clustering)입니다. 비지도(Unsupervised) 기법인 클러스터링을 통해 시계열 데이터가 주로 가지는 형태가 어떤 것들이 있는지를 데이터의 종류에 크게 구애 받지 않고 쉽게 파악할 수 있습니다. 시계열 데이터의 대표적인 형태들을 각각의 군집으로 표현할 수 있습니다.
클러스터링은 데이터 샘플 간 유사도를 이용하기 때문에, 데이터 간 유사도를 어떻게 정의하느냐가 중요합니다. 만약 유사도를 계산해야 하는 두 시계열의 길이가 똑같다면, 유클리드 거리(Euclidean distance)나 코사인 유사도(cosine similarity)를 사용해서 시계열 간 유사도를 정의할 수 있습니다. 그러나 두 시계열의 길이가 서로 다른 경우까지 고려하면 DTW(Dynamic Time Warping)와 같은 방법을 사용하여 시계열 간 유사도를 계산합니다.
여기서는 DTW 방법을 보완한 ‘ERP(Edit distance with Real Penalty)’ 기법을 사용하여 야구 경기별 진행 양상을 군집으로 묶어 요약하는 기술과, 일정 기간 동안의 종목별 주가 데이터를 RNN Autoencoder를 이용해 동일한 크기의 representation vector로 표현한 후 여기에 코사인 유사도를 계산하여 주가 간 유사도를 측정하는 기술을 소개하겠습니다.
승리 기대값(Win expectancy)이란 야구 경기 중에서 현재 몇 회인지, 팀이 몇 점을 득점했는지, 현재 아웃카운트가 몇 개이고 주자 상황이 어떤지를 가지고 팀이 현 시점에서 경기를 이길 확률을 계산한 값입니다. 야구 경기는 승리 기대값으로 이루어진 시계열로 표현할 수 있습니다. 그리고 같은 경기라고 해도 이긴 팀의 시계열과 진 팀의 시계열은 서로 반대 모양을 보일 것이고, 개별 경기의 시계열 길이는 상황에 따라 서로 다르게 됩니다.
이렇게 서로 다른 길이의 시계열 간 유사도를 계산하기 위해 DTW 방안을 적용합니다만, DTW 방법은 triangle inequality를 만족하지 않아 수학적 거리로 사용할 수 없다는 한계가 있습니다. 그래서 이를 개선한 ‘Edit distance with Real Penalty(ERP)’ 기법을 승리 기대값 시계열로 표현된 경기 양상 유사도 계산에 사용하였습니다. 아래 그림은 이 방법으로 2014년 3월 31일에 있었던 한화-롯데 경기와 유사하게 진행된 경기들을 선정한 것입니다.
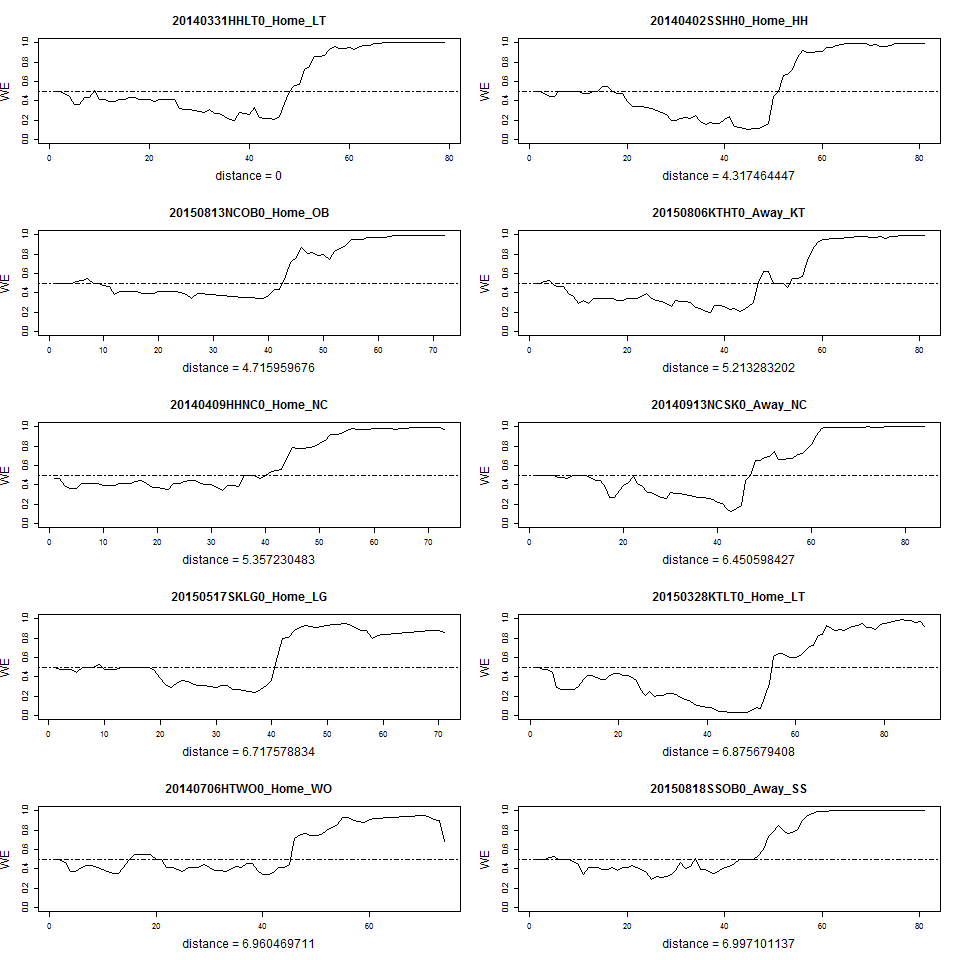
최근 3년의 정규 시즌 동안 있었던 야구 경기들을 승리팀 기준으로 승리 기대값 시계열로 표현한 후 이 데이터에 대해 계층적 군집화(hierarchical clustering)를 적용해 경기 양상을 유형화할 수 있게 됩니다.
이렇게 추출한 경기 양상별 유형에 대한 맞춤 표현을 준비하여 사용자에게 전달하면, 현재 페이지에서 서비스 중인 것처럼 그날 있었던 야구 경기의 진행 양상을 직관적 표현으로 요약하여 사용자에게 전달할 수 있게 됩니다.
DTW나 ERP 같은 기법은 유사도를 계산하기 위해 동적 프로그래밍(Dynamic Programming) 접근을 취하게 되는데, 이는 두 시계열 간 유사도 계산을 하기 위해 시계열 길이의 제곱 번만큼의 계산량이 필요합니다. 한국 야구 경기의 경우에는 경기수가 많지 않아 계산량이 큰 문제가 되지는 않습니만, 주식이라면 어떨까요? 한국의 증권 시장에 상장된 회사의 수는 17년 기준 2,040개에 이르고, 10년 넘게 주식 시장에서 거래된 종목도 많습니다. 지난 1년 간의 일별 주가 시계열 데이터를 대상으로 하더라도, 40만 개가 넘는 시계열을 대상으로 유사도를 계산해야 합니다.
만약 서로 다른 길이의 주가 시계열을 별도의 공간에 있는 한 점으로 표현할 수 있다면 시계열을 동일한 크기의 벡터로 표현하게 되므로 ERP 기법보다 필요 계산량이 훨씬 적은 방법으로 유사도를 측정할 수 있습니다. 또한 주가 시계열의 좌표 공간 상 위치에 따라 추가적인 분석도 가능해지는 장점이 있습니다.
이를 위해서 저희는 RNN auto-encoder(Recurrent Neural Networks auto-encoder) 방법을 주가 시계열 데이터에 적용해보았습니다. Autoencoder란 주어진 데이터를 인코딩하고 디코딩하는 과정을 반복하면서 데이터를 representation 벡터로 표현하는 방법입니다. 서로 다른 길이의 시계열을 동일한 크기의 representation 벡터로 인코딩할 수 있는데 이 구조를 RNN autoencoder 혹은 seq2seq 모델이라고 합니다.
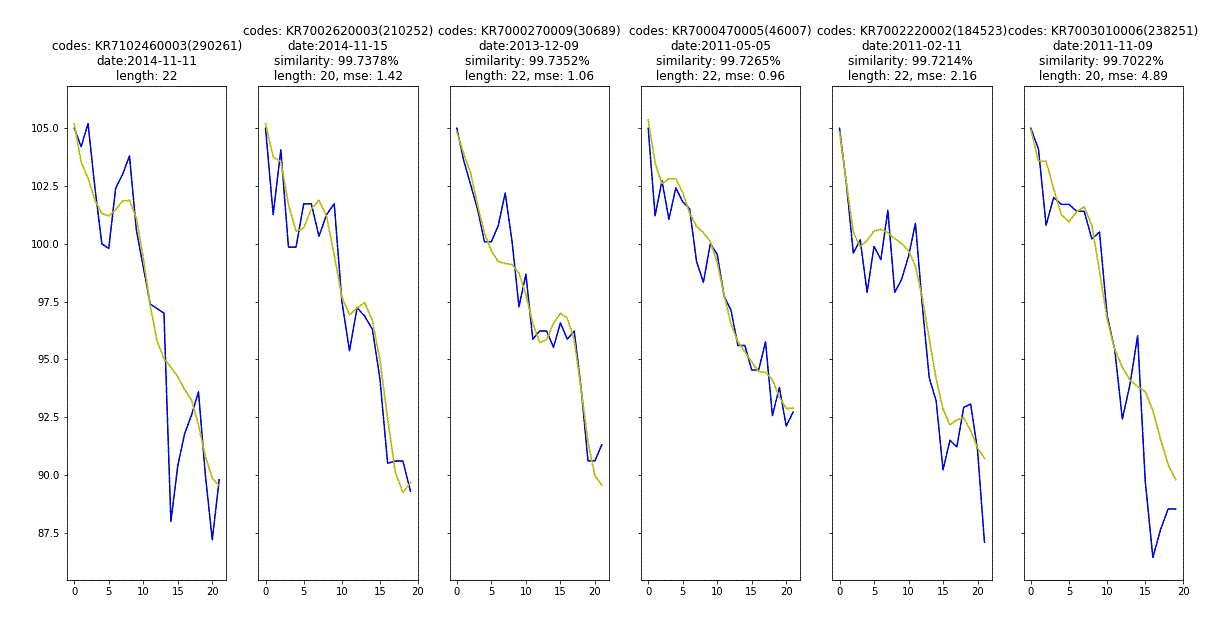
주가 시계열 데이터를 대상으로 RNN autoencoder를 학습한 결과, 유사한 시계열을 representation 공간의 유사한 지점에 매핑해주는 것을 확인할 수 있었습니다. 다음은 임의로 뽑은 시계열 1천 개에 대한 좌표를 t-SNE 기법을 이용해 2차원으로 표현한 그림으로, 빨간 점은 t-SNE로 줄인 2차원 공간에 대한 시계열의 좌표를 의미하고 검은 선은 시계열의 원래 형태를 나타낸 것입니다. 확실히 비슷한 시계열들이 가까이에 위치하는 것을 알 수 있습니다.

또한, 테스트 집합에서 임의의 시계열을 선택해 representation 공간 상에서 가장 가까이에 위치한 시계열 5 개를 뽑아 그려보면 아래와 같은 결과를 확인할 수 있습니다.
이 그림에서 파란 실선은 원래 주가 시계열을 나타내며, 노란 실선은 RNN autoencoder가 representation 벡터를 디코딩해서 만든 시계열입니다. 파란 실선의 개략적인 형태를 노란 실선이 충실히 모사하는 것으로 보아 모델이 원 시계열 데이터의 특징을 잘 추려내 representation 벡터로 저장했음을 알 수 있으며, representation 공간에서 가깝게 위치한 시계열들은 실제로도 유사한 형태임을 확인할 수 있습니다.
이렇게 만들어낸 시계열별 representation 벡터에 앞서 야구 경기 양상 군집화에서 했던 방법론을 적용하면, 야구 경기 양상 요약과 동일하게 주가 움직임에 대해서도 사용자에게 요약 정보를 제공할 수 있습니다.
시퀀스 데이터 요약하기
시계열 데이터가 일정한 시간 간격으로 발생하는 데이터라면, 일정하지는 않지만 시간의 순서에 따라 나타나는 시퀀스 데이터도 있습니다. 사람의 행동이나 개입에 따라 발생하는 대부분의 데이터는 시퀀스 데이터라고 할 수 있습니다. 게임 데이터의 대부분도 시퀀스 데이터입니다.
이러한 시퀀스 데이터를 효과적으로 요약하기 위한 연구도 진행하고 있습니다. 엔씨는 게임 플레이 로그를 분석하여 사용자들이 어느 구간에서 어려움을 겪고 있는지, 기획 의도대로 플레이를 하고 있는지 탐색하고 분석하여 사용자 경험을 개선하고자 합니다. 하지만, 아래의 두 가지 이유로 이런 유저 행동 로그를 이용한 탐색 및 분석 과정은 지난한 과정으로 인식되고 있습니다.
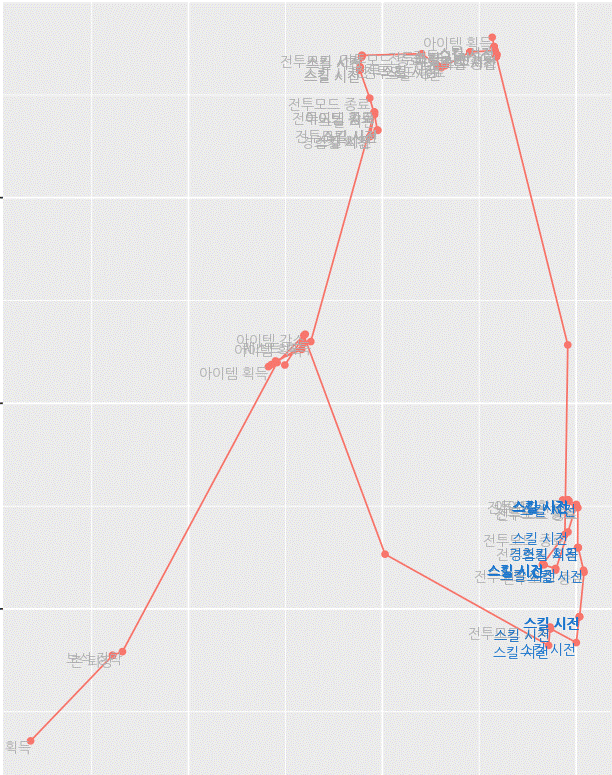
우선, 사용자 개개인의 로그는 길고 노이즈가 많습니다. 오른쪽의 그림은 실제 게임 내 특정 미션을 진행하는 사용자의 경로 및 행동 정보를 표시한 것입니다. 파란색으로 표시된 행동이 해당 미션 수행에 있어서 중요한 행동이지만 이 외의 행동들이 다수 존재하기 때문에 어떤 것이 탐색해 볼만한 행동인지 확인이 어렵습니다.
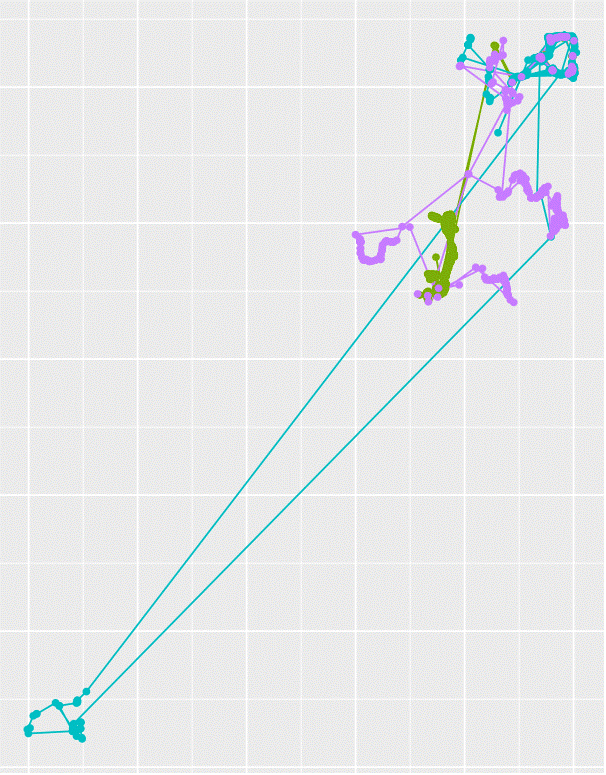
두 번째 이유는 사용자가 많고 행동이 다양해서 일반적인 패턴을 확인하기 어렵다는 점입니다. 아래의 그림은 4명의 사용자 행동을 하나의 그래프에 나타낸 것입니다. 동일한 퀘스트를 진행하고 있지만 사용자가 남기는 행동의 수, 경로 등에 차이가 있습니다. 하루에 하나의 서버에서도 수천 건의 동일한 퀘스트가 진행되는데, 이러한 다수의 로그에서 공통적인 특징을 찾아내고 탐색하는 것은 쉽지 않습니다.
이런 두 가지 이유로 인해 사용자 행동 탐색 업무는 효율이 떨어지고 어려움이 많았습니다. 우리는 이런 업무의 난점을 해결하고 개선하기 위해 세 개의 Task로 세분하여 업무를 진행했습니다.
우선, 우리가 대상으로 한 시퀀스 데이터는 사용자가 하나의 미션을 완료하기 위해 남긴 일련의 행동 로그입니다. 사용자 행동 로그는 일종의 시퀀스 형태의 데이터로서, 사용자가 수행한 미션별로 하나의 시퀀스가 발생됩니다. 사용자가 만약 총 27개의 미션을 수행했다면 총 27개의 시퀀스가 발생됩니다.
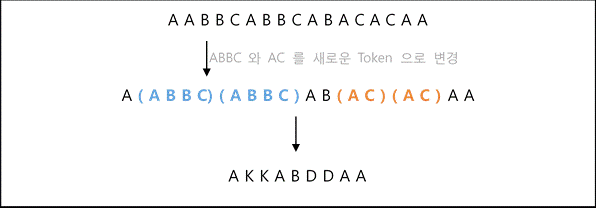
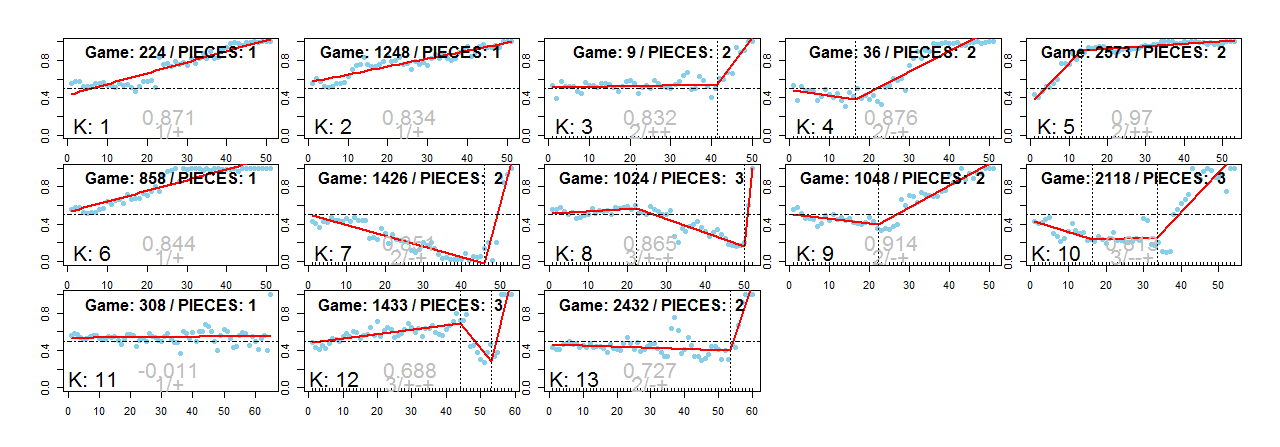
이러한 데이터를 가지고 시작한 첫 번째 Task는 사용자의 행동 로그 길이를 줄이는 것입니다. 기존 로그 sequence가 가지고 있는 정보의 손실은 최소한으로 줄이면서 sequence의 길이는 최대한 줄이는 것입니다. 이런 목적을 달성하기 위해서 반복적으로 나타나는 sub sequence를 찾고 이를 새로운 Token으로 대체하는 방법을 적용할 수 있습니다.
이를 위해서 연관관계 분석에서 사용되는 support와 confidence 개념을 이용해볼 수 있습니다. 만약, 사용자 행동 ‘A’와 ‘C’가 연달아 나오는 경향이 크다면 행동 A에 대한 행동 C의 confidence가 높을 것입니다. 그리고 이런 행동 A, C 패턴이 자주 발생하는 패턴이라면 support 또한 높게 나타날 것입니다. 하지만 이렇게 subsequence를 다른 Token으로 대체하는 것에도 이슈가 있습니다.
위의 두 예제는 동일한 시퀀스를 서로 다르게 표현한 것입니다. 왼쪽에서 반복되는 subsequence를 몇 개 추출하여 새로운 문자 D F G K로 대체했습니다. 반복되는 subsequence를 새로운 Token으로 변경했음에도 불구하고 오른쪽이 왼쪽보다 더 이해하기 쉽다고 확신하기 힘듭니다. 오른쪽이 왼쪽에 비해 전체 로그의 길이는 줄었지만, 사용된 문자가 3개에서 7개로 늘었기 때문에 더 복잡해진 면이 있습니다.
즉, subsequence를 모두 새로운 Token으로 대체하는 것이 아니라, 전체 sequence 길이와 이 sequence를 표현하기 위해 사용되는 코드의 개수를 결정하기 위한 기준이 필요합니다. 우리는 이러한 문제를 해결하기 위해 정보량이라는 개념을 도입했습니다.
위의 식에서 S는 사용되는 코드의 개수, N은 Sequence 전체의 길이를 의미합니다. 앞의 예제로 설명하자면 왼쪽은 N = 43, S = 3 이며 오른쪽은 N = 23, S=7로 그 정보량은 각각 20.51, 19.43이 되어 오른쪽의 정보량이 더 낮다는 것을 알 수 있습니다. 정보량 계산시, 코드의 개수와 시퀀스의 길이가 서로 trade off되기 때문에 정보량을 이용하여 적절한 N과 S를 찾을 수 있었습니다.
다음으로 진행한 Task는 유저 행동 로그 안에서 중요한 유저 행동을 찾는 작업이었습니다. 이 Task에서는 일련의 행동 중에 어떤 행동이 중요한 지 Tagging한 정보가 있었다면 supervised classification 문제로 풀 수 있었을 테지만, 중요한 행동이라는 명확한 정답을 가지고 있지 않습니다. 이러한 상황을 해결하기 위해 ‘어떤 미션의 Sequence를 다른 미션의 sequence와 구분하기 위해 더 많이 참고되는 행동’을 ‘sequence 내에서 사용자의 중요한 행동’으로 정의했습니다. 어떤 미션의 sequence를 다른 미션의 로그 sequence와 구분할 때 많이 활용되는 사용자의 행동이 있다면 이는 해당 로그 Sequence에서 중요한 행동일 것입니다.
우리는 이러한 정의에 따르는 각 단위 행동의 중요성을 측정하기 위해 attention이 포함된 RNN classification 모델을 이 문제에 적용시켰습니다. 이 모델은 사용자의 행동 로그를 입력으로 받아 해당 행동 로그가 어떤 미션을 수행한 로그인지 추정하는 모델로써 여기서 같이 추정되는 attention을 각 단위 행동의 중요도라고 판단했습니다.
이 모델에서 attention은 모형의 최종 아웃풋을 판단할 때 사용되는 각 Token별 가중치이기 때문에 이 값이 높다면 아웃풋에 영향을 더 많이 준다고 판단할 수 있습니다. 이는 ‘사용자의 중요한 행동’의 정의와 동일한 의미를 가집니다. 아래 그림의 로그에서 attention이 높은 로그를 녹색으로 표현한 것으로써 특정 퀘스트의 중요 로그들이 잘 선정되고 있음을 확인할 수 있습니다.
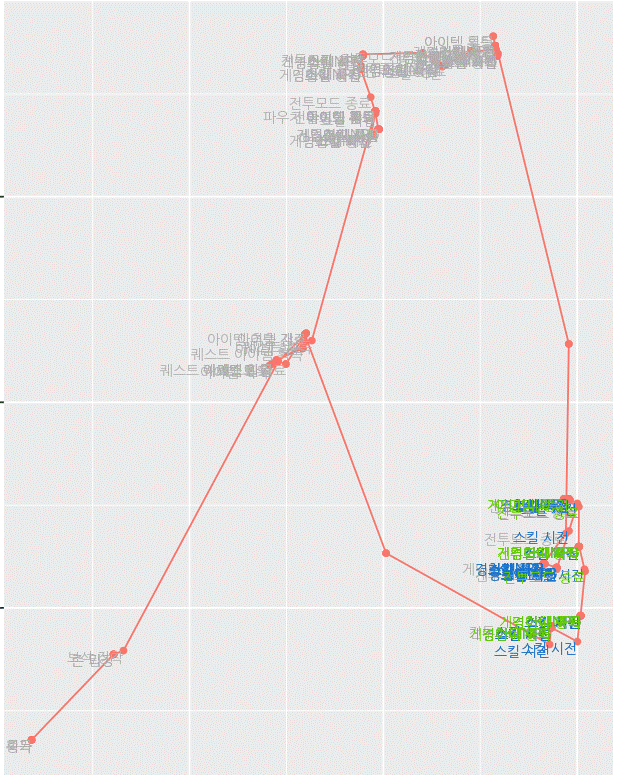
마지막으로 진행한 Task는 다양한 유저의 행동로그를 몇 개의 유형으로 분류하는 Task였습니다. 이 Task에는 두 가지 어려운 점이 있었습니다. 하나는 Clustering 대상이 되는 로그의 길이가 다르다는 점이며, 또 다른 하나는 로그의 각 Token(행동)이 범주형 데이터라는 점이었습니다. 기존의 clustering 방법론은 고정된 차원의 실수공간에서만 적용가능하기 때문에 길이가 다른 범주형 data의 sequence를 고정된 차원의 실수공간으로 옮기기 위한 방법을 고민했습니다. 다양한 방법이 있겠지만, 이 분석에서는 앞서 사용한 RNN 모델의 결과를 다시 사용했습니다.
우리가 사용한 RNN 모델에서는 LSTM Layer가 포함되어 있습니다. 이 모델에 유저 행동로그를 입력으로 주면 해당 로그는 LSTM layer를 통과하여 하나의 벡터로 표현이 됩니다. 모델에서는 이 벡터를 바탕으로 최종적으로 어떤 미션의 로그인지 판단합니다. 즉, 우리의 모델을 이용하면 유저 행동 로그를 고정된 크기의 다차원 실수 공간에 표현할 수 있게 되고, 이를 통해 기존의 클러스터링 방법론을 적용할 수 있었습니다.
우리는 hierarchical clustering 방법론을 적용했고 t-SNE를 이용하여 아래의 그래프에 그 결과를 그려보았습니다. 각 숫자는 미션 ID를 의미하는데, 동일한 미션ID별로 군집이 형성되어 있고, 일부 미션의 경우, 각 미션 안에서도 소규모 군집이 생성되어 있는 모습을 확인할 수 있었습니다.
도입부에서 언급한 것처럼 개별 사용자의 행동 로그에서 정보를 추출하면 게임 개발에 유용하게 활용할 수 있습니다. 뿐만 아니라 유의미한 수준으로 게임 플레이를 요약할 수 있다면, 본인의 게임을 복기하거나 다른 사람들과 플레이 내용을 손쉽게 공유할 수 있을 것 입니다.
정량 데이터에 대한 직관적으로 요약하기
앞에서는 시간의 흐름에 따라 발생하는 시계열 데이터와 시퀀스 데이터를 요약하여 표현하는 방안을 살펴보았습니다. 이번에는 다양한 차원으로 집계된 정량 데이터를 직관적으로 요약하는 방안에 대한 연구 내용을 소개하고자 합니다.
시계열/시퀀스 데이터를 포함하여 AI가 수집하는 대부분의 데이터는 이후에 정량 데이터로 집계하여 축적/관리합니다. 야구 경기로그는 선수/팀/경기, 그리고 특정 기간과 상황에 따른 기록으로 집계합니다. 예를 들면, 야구 선수 ‘박민우’의 데이터는 개별 경기 로그로부터 이번 시즌의 출전경기수, 타석수, 안타수, 볼넷수, 삼진수, 홈런수, 도루수, 타율, 출루율 등의 기록을 생성하여 관리합니다. 물론 대상기간, 상황 등에 따라 집계 기준을 변경할 수도 있습니다.
그런데 AI와 사용자가 원활한 커뮤니케이션을 하기 위해서는 이를 한번 더 직관적으로 요약할 필요가 있습니다. 사용자가 ‘타율’, ‘안타수’ 등과 같이 개별 기록에 대해서도 관심이 있지만, 박민우 기록이 “우수한 편인지”, “타격은 잘하는지”, “장타력은 좋은지”, “최근 성적은 어떤지” 등과 같이 개별 기록에 대한 요약/평가된 결과를 원하는 경우가 많습니다. 이를 위해 선수/팀/경기에 대한 정량 데이터를 요약하여 ‘잘한다’, ‘부진하다’ 등의 정성적 표현을 생성하고자 합니다.
이러한 정성적 요약/표현(Opinion)을 생성하기 위해서는 도메인 전문가를 통해 기록 데이터를 적절하게 요약하는 규칙을 수립해 해결하는 게 가장 간단합니다. 타율이 0.310을 넘으면 타격 정확도가 좋다고 할 수 있고, 9이닝당 삼진수가 6개 이상이면 구위가 우수하다고 규칙을 정하는 방법입니다. 그러나 이러한 경우에는 특정 전문가의 견해로 인한 왜곡이 있을 수 있고, 주변상황의 변화(예시: 전반적으로 수비력보다 공격력이 강해진 투고타저 현상 발생)에 따라 규칙을 수정해줘야 하는 한계가 있습니다.
다른 방안으로는 Opinion Mining 방법론을 활용하여 뉴스 기사나 커뮤니티 게시글 등을 통해 정성적 요약 표현이라고 할 수 있는 오피니언을 추출하여 활용하는 방법이 있습니다. 그러나 이러한 경우에는 작성되어 있는 오피니언에 국한되기 때문에 최신 결과라고 할 수 없고, 사람들이 언급하는 일부 선수/팀에 대해서만 오피니언이 존재하여 전체를 커버할 수 없다는 어려움이 있습니다. 따라서 이러한 한계를 해결하고, 선수/팀에 대한 기록에 대해 적합한 정성적 표현을 추론하기 위한 방안을 모색하였습니다.
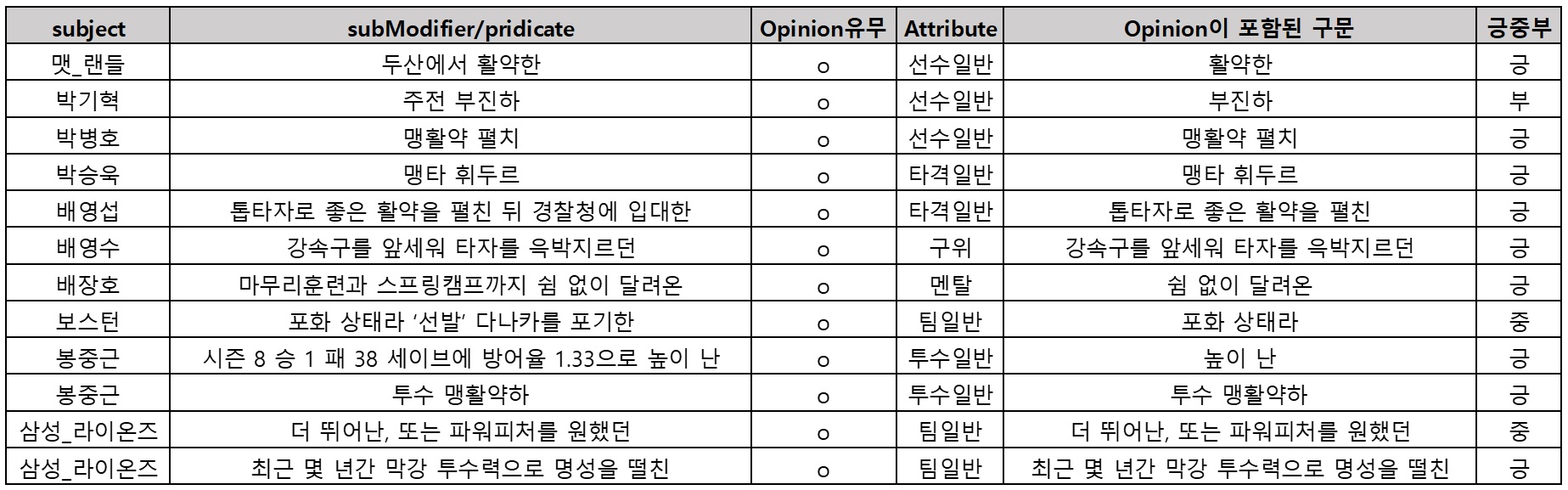
팀, 선수, 경기의 정량 데이터에 대한 정성적 표현을 추론하는 기술도 있습니다. 아래와 같이 테임즈의 타격에 대해 뛰어나다고 표현하거나 나성범의 최근 성적에 대해 타격 컨디션은 좋으나 장타력은 부진하다고 추론하는 것입니다.

이를 위해 실제 사람들이 작성한 문서로부터 정성적으로 요약된 표현을 추출하고, 이러한 표현의근거가 되는 정량 데이터를 기반으로 정량 데이터와 정성적 표현 간의 추론 관계를 모델링하고자 합니다. 이를 통해 수시로 발생하는 정량 데이터에 적합한 정성적 표현을 생성하여 Knowledge로 활용할 것입니다.
우선, 실제 사람들이 작성한 문서로부터 정성적으로 요약된 표현을 추출합니다. 선수나 팀에 대한 객관적인 표현 정보를 확보하기 위해 커뮤니티 게시글이나 댓글이 아닌, 뉴스 기사를 대상으로 하였습니다. Language AI Lab에서 개발하고 있는 Relation Extraction 기술을 활용하여 Relation Triple (Subject, Predicate, Object)에서 subject에 선수/팀/경기와 같이 표현 대상이 되는 개체가 있는 부분을 추출하였습니다.
이러한 표현들 중에서 우리가 의도하는 정성적 요약에 해당하는 표현만을 추출하기 위해 CNN 기반의 문장 분류 모델을 활용하여 오피니언 표현 분류기를 개발하였습니다. Precision 88%, Recall 84% 정도의 정확도를 보이는 오피니언 표현 분류기를 확보할 수 있었습니다. 추가적으로 오피니언 표현을 대상(팀/타자/투수/경기)과 평가요소(장타력, 선구안, 주력, 구위, 제구력 등)에 따라 분류하는 모델을 추가하여 아래와 같이 오피니언을 자동으로 추출/분류하였습니다.
대상과 평가요소에 따라 정성 표현을 확보한 후에는, 정량 데이터와의 관계를 추론해야 합니다. 예를 들어, 나성범의 수비력에 대한 정성표현이 아래와 같이 추론되는 모델을 구성합니다.
f (나성범,수비력) = {'불안함' , '외야 수비만 가능', ...}
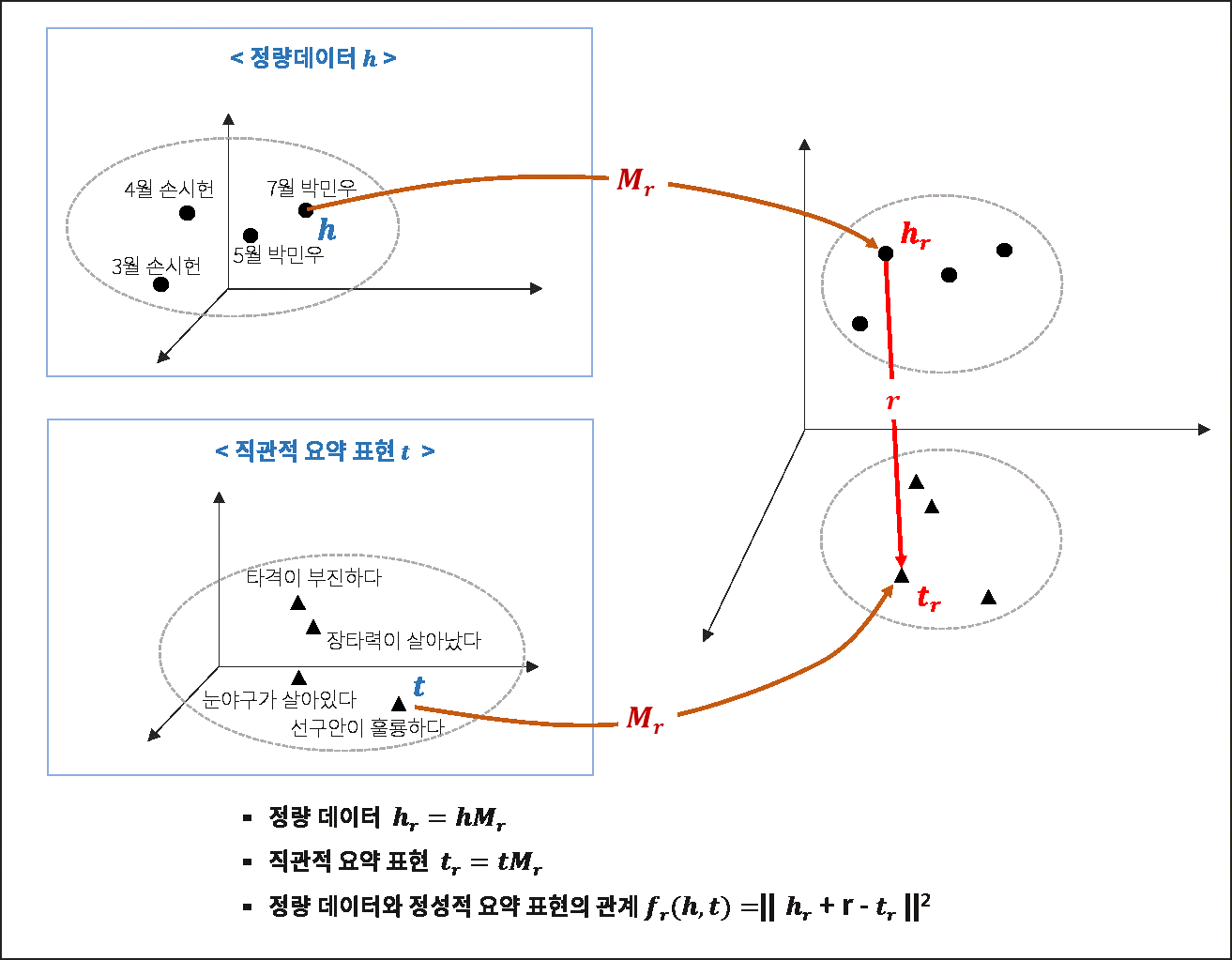
정량 데이터와 정성적 표현 간의 관계를 매핑하기 위해서는 각각을 다차원 벡터로 임베딩하는 과정을 거쳐 연산이 가능하도록 합니다. 이때 정량 데이터와 정성표현이 평가요소에 의한 관계로 연결되는 Semantic Triple (정량 데이터, 평가요소, 정성표현)로 정의하여 추론 모델을 개발했습니다.
정량 데이터 h와 직관적 요약 표현 t를 평가요소에 의한 관계 r로 매핑하는 모델을 구성하기 위하여 아래의 Loss Function을 최소화하는 방향으로 최적화합니다. 즉 우리가 원하는 semantic triple에 대한 score가 최대한 Incorrect triple보다 작아지도록 학습시키고자 합니다.
다만, 이 방법론을 진행하는데 있어 충분한 학습 데이터 확보에 어려움이 있었습니다. 관계 추론 모델의 객관적인 학습 데이터를 확보하기 위해 커뮤니티 게시글이나 댓글을 제외하고 기자들이 작성한 뉴스 기사만을 대상하니, 기사에 표현되어 있는 직관적 요약 표현이 많지 않기 때문입니다. 현재도 이러한 이슈를 해결하기 위한 다양한 시도를 진행하고 있습니다.
이렇게 추론된 정성표현을 자연스러운 대답이나 Knowledge로 생성하기 위해 Language AI Lab에서 개발하고 있는 NLG(Natural Language Generation) 과정을 거치게 됩니다. 해당 결과의 예시는 아래와 같습니다.
지금까지 원활한 커뮤니케이션을 위해 Knowledge AI Lab에서 진행한 데이터의 요약 및 직관적 표현 방안에 대한 연구 내용을 설명드렸습니다.
아직까지 원천 데이터를 최대한 자동화하여 요약하고 직관적으로 표현하는 부분에 많은 부족함이 있습니다. 그러나 우리 주변에서 수시로 발생하는 일들을 데이터나 문서를 통해 파악하고 이에 대해 사용자와 AI가 자연스럽게 커뮤니케이션 하기 위해서는 반드시 필요한 기술이라고 생각합니다. 앞으로도 관련 연구 결과를 페이지 서비스에 활용하고 지속적으로 고도화할 예정입니다.
다음 연재에서는 수많은 Knowledge나 Content를 사용자의 선호도나 상황에 맞춰 적절하게 제공하기 위한 Curation 기술에 대한 내용을 소개하겠습니다.
박희환
NLP Center Knowledge AI Lab Application팀.
기계에 데이터를 주고 학습시키면
멋진 일들을 할 수 있다는 것에 마음을 반해
겁도 없이 인공지능과 데이터 과학의 길에 들어 선,
데이터를 통해 인간을 더 잘 이해하고 싶은 연구자입니다.
NLP Center Knowledge AI Lab Application팀.
기계에 데이터를 주고 학습시키면
멋진 일들을 할 수 있다는 것에 마음을 반해
겁도 없이 인공지능과 데이터 과학의 길에 들어 선,
데이터를 통해 인간을 더 잘 이해하고 싶은 연구자입니다.
김건수
NLP Center Knowledge AI Lab Mining팀.
통계학을 전공했고 데이터 마이닝 방법론을 연구 중입니다.
지금은 복잡한 시퀀스 데이터에서
유용한 정보를 찾아내는 방법에 관심을 갖고 있습니다.
NLP Center Knowledge AI Lab Mining팀.
통계학을 전공했고 데이터 마이닝 방법론을 연구 중입니다.
지금은 복잡한 시퀀스 데이터에서
유용한 정보를 찾아내는 방법에 관심을 갖고 있습니다.
정세희
NLP Center Knowledge AI Lab 실장.
이동통신, 커머스, 제조, 음악, 금융, 게임 등
다양한 비즈니스의 데이터를 분석하고 모델링하여
더욱 인텔리전트한 서비스를 만들어 왔습니다.
지금은 훌륭한 동료들과 즐겁게 연구하며
재미있는 AI를 만들어가고 있습니다.
NLP Center Knowledge AI Lab 실장.
이동통신, 커머스, 제조, 음악, 금융, 게임 등
다양한 비즈니스의 데이터를 분석하고 모델링하여
더욱 인텔리전트한 서비스를 만들어 왔습니다.
지금은 훌륭한 동료들과 즐겁게 연구하며
재미있는 AI를 만들어가고 있습니다.
 Facebook
Facebook  KakaoTalk
KakaoTalk  LinkedIn
LinkedIn  Email
Email  Copy URL
Copy URL