 Facebook
Facebook  KakaoTalk
KakaoTalk  LinkedIn
LinkedIn  Email
Email  Copy URL
Copy URL AI에 대한 R&D를 선도하고 있는 엔씨소프트.
엔씨소프트의 NLP(자연어처리) 센터는 언어(Language)AI랩과 지식(Knowledge)AI랩의 전문 연구진들이 각각 자연어처리(NLP) 기술과 지식 추론 기술을 활발히 연구하고 있습니다.
‘커뮤니케이션과 AI’ 여섯 번째 편에서는, AI 야구 정보 서비스 페이지(PAIGE)를 기반으로 실제 사용자들이 작성하는 비문법적인 문장들을 처리하는 기술에 대해 자세히 살펴보겠습니다.
AI에 대한 R&D를 선도하고 있는 엔씨소프트.
엔씨소프트의 NLP(자연어처리) 센터는 언어(Language)AI랩과 지식(Knowledge)AI랩의 전문 연구진들이 각각 자연어처리(NLP) 기술과 지식 추론 기술을 활발히 연구하고 있습니다.
‘커뮤니케이션과 AI’ 여섯 번째 편에서는, AI 야구 정보 서비스 페이지(PAIGE)를 기반으로 실제 사용자들이 작성하는 비문법적인 문장들을 처리하는 기술에 대해 자세히 살펴보겠습니다.

그 동안 페이지에 적용된 NLP 기술을 자연어 이해와 생성이라는 큰 분류로 나누어 소개하였습니다. 자연어로 된 사용자의 말을 이해하는 기술, 그리고 대량의 정보를 수집하고 요약해서 전달하는 방법, 데이터로부터 자연어 문장을 생성하고 문체를 변환하는 방법 등에 대해 설명하였습니다.
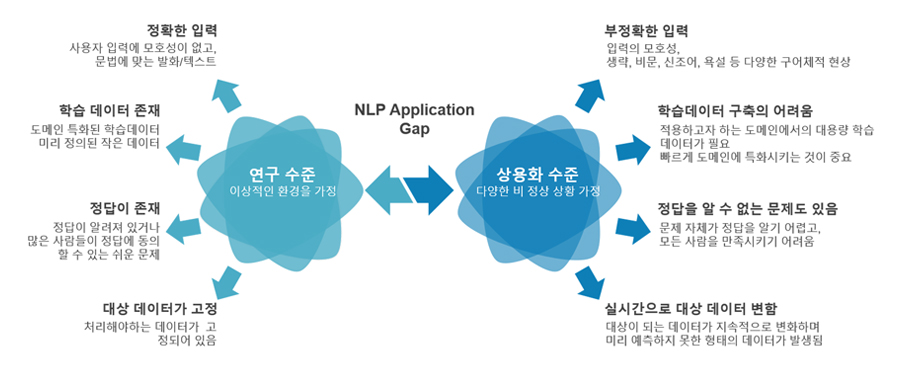
그러나 앞서 소개한 NLP 방법론들은 비교적 정상적인 환경에서 사용할 수 있는 방법입니다. 사용자는 비교적 문법적인 문장을 말하고, 이를 학습하는 AI 모듈들에는 잘 구축된 학습 데이터가 이미 많이 구축되어 있으며, 사람이 생각해도 정답을 알 수 있는 잘 정의된 문제를 풀고 있다고 가정한 것인데요. 물론 시스템을 개발할 때, 사용자의 요구사항을 최대한 고려하여 많은 양의 학습데이터를 구축하고 이를 기반으로 연구를 진행합니다. 또 AI를 사용하는 사용자가 적절히 시스템에 적응하면서 문법적인 문장을 말해주는 것을 기대할 수도 있겠죠.
하지만 보다 견고한(Robust) 소통을 하기 위해서는 비문법적인 문장들도 잘 처리할 수 있어야 하고, 보다 빠른 도메인 확장을 위해 학습데이터가 부족한 상황에서도 학습할 수 있어야 합니다. 아래 그림은 자연어처리 연구를 하는 연구자들이 실제 문제에 부딪히게 되는 상황입니다. 이 글의 제목에서는 Extreme Setting이라고 했는데요. 어렵지만 꼭 풀어야 하는 연구 영역이기도 합니다.
이번 글에서는 이러한 고민에서 출발해서 수행했던 엔씨소프트 언어(Language)AI랩의 세 가지 연구를 소개하겠습니다. 먼저 소개할 두 가지는 최근 제30회 한글 및 한국어 정보처리 학술대회(관련 링크)에서 발표한 것이고 또 하나의 연구는 엔씨소프트와 산학과제를 통해 협력하고 있는 KAIST User&Information Lab의 협동 연구(EMNLP 2018 발표, 관련 링크)입니다.
이 연구는 온라인의 실제 구어체 한국어 텍스트를 대상으로 텍스트의 품질과 관계없이 감성을 견고하게(Robust) 인식하기 위한 방법입니다. 온라인 구어체 텍스트는 줄임말이나 맞춤법 오류가 많고 띄어쓰기가 맞지 않는 등 잘 작성된 문어체와는 다릅니다. 또한 신조어나 은어들은 OOV(Out-Of-Vocabulary) 문제를 발생시키기도 합니다.
이러한 구어체를 처리하기 위해 별도의 교정기나 형태소 분석기 등을 사용하여 정련된 데이터를 상위 어플리케이션에 전달할 수도 있지만, 이러한 분석기 역시 성능이 100%가 아니기 때문에 오류 전파의 위험이 있고, 구어체의 특성상 계속 변화하는 구어체 현상을 모델에 반영하기도 쉬운 일이 아닙니다.
아래는 야구 댓글과 영화 리뷰에서 긍정, 혹은 부정적인 감성을 가진 댓글에 대한 예시입니다. 띄어쓰기는 물론, 문법 오류를 다수 포함하고 있고, 심지어 도메인 전문가만이 알 수 있는 다양한 은어들이 포함되어 있습니다.

사실 이러한 환경이 실제 온라인 구어체 환경에서는 더 일반적인 경우라고 할 수 있고, 심지어 사용자는 이러한 비문과 기호 입력을 통해 문어체에서 표현하기 어려운 많은 정보를 함축적으로 전달하고 있기도 합니다. (당연히 이러한 입력을 고려할 수 있는 시스템 설계가 필요한 것이죠)
다음은 이러한 입력에 대응하기 위한 간단한 모델을 소개하겠습니다. 2018년 언어(Language)AI랩에서 국내 한글 자연어처리학회에 발표한 내용으로, 네트워크 구조는 다음과 같습니다.
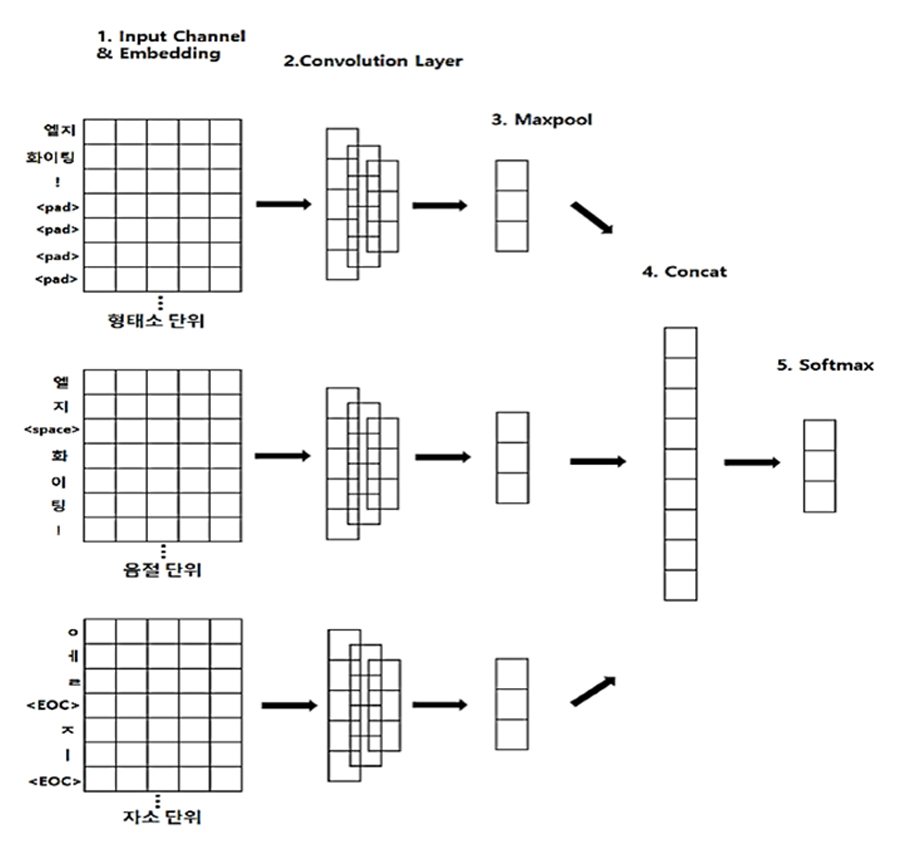
Multi-channel CNN 모델은 세 개의 입력 채널을 가지고 있으며 하나의 문장이 형태소, 음절, 자소로 나눠져서 세 개의 채널의 입력으로 사용됩니다. 그림에서와 같이 “엘지 화이팅!” 이라는 문장은 형태소로 나누면 [“엘지”, “화이팅”, “!”]이 되고 이는 첫 번째 채널로 들어가게 됩니다. 또 위의 문장을 음절로 나눌 시에는 [“엘”, “지”, “”, “화”, “이”,”팅”, “!”] 이 되며 이를 두 번째 채널의 입력으로 사용합니다. 마찬가지로 위의 문장을 자소로 나누어 [“ㅇ”,”ㅔ”,”ㄹ”,””, “ㅈ”,”ㅣ”, ……]를 마지막 채널의 입력으로 사용하게 됩니다.
이 네트워크는 자소와 음절에서 특징 벡터를 추출함으로써 자소 단위의 오타 및 문법적 오류와 음절 단위의 합성어와 줄임말에서 손실된 정보를 추출할 수 있습니다. 그리고, 학습하지 못한 새로운 단어에 대해서 형태소가 추출하지 못하는 특징을 자소와 음절에서 추출할 수 있게 됩니다.
이 방식으로 야구 댓글 및 한국어 영화 리뷰 데이터의 감성을 분석한 성능은 아래와 같습니다. 야구 댓글은 약 1만5천 문서, 영화 리뷰는 15만 문서로부터 학습한 결과이고, 영화의 경우 비교적 긍/부정 평가가 명확한 데이터를 사용한 것이기 때문에 성능상에서 많은 차이를 보입니다.
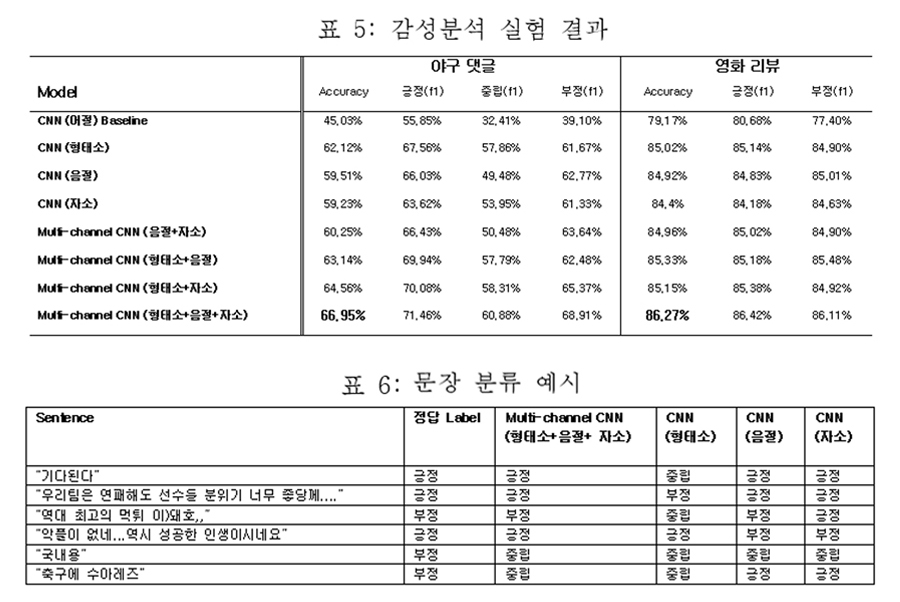
야구의 경우 문장을 이해하는데 도메인 지식이 많이 필요하기 때문에 학습데이터가 부족한 상황에서 아주 좋은 성능을 기대하기는 어려운데요. 그래도 예제를 보면, “먹튀”라던가 “좋당께…” 등의 구어체 표현에서 형태소와 더불어 음절, 자소를 함께 고려한 CNN이 더 좋은 결과를 보임을 알 수 있습니다.
이번에 소개하고자 하는 연구는 학습데이터가 거의 없거나 많지 않은 상황에 대한 연구입니다. 이전에 회차에서 딥러닝 기반의 Seq2Seq NLG(Sequence-to-Sequence Natural Language Generation)연구에 대해 소개한 바가 있는데요.
예를 들면 질의 응답 시스템에서 사용자 질문에 대해 내부적으로 처리를 한 뒤 시스템 결과부터 자연어 응답을 생성한다든가, 생성되거나 추출된 문장을 다른 문체로 변환하는 등의 태스크들이 이 NLG 연구에 속합니다.
특히 아래에서 소개할 연구는 자연어 문체 변환(Style Transfer)에 관한 것입니다. 딥러닝 기반의 자연어 문체 변환에서는 크게 두 가지 이슈를 해결해야 하는데요.
우선 학습을 위해 대량의 학습 말뭉치, 즉 동일한 의미이나 문체만 다른 문장 쌍을 대량으로, 구축해야 합니다. 또 한 가지는 이러한 학습 말뭉치를 학습할 수 있는 네트워크 구조인데, 무엇보다 중요한 것은 스타일은 변화시키면서 실제 문장의 콘텐츠, 의미는 유지해야 한다는 것입니다. 스타일과 함께 의미가 변화된다면 잘못된 정보를 전달하게 되므로, 상용 시스템에서는 사용이 불가능하게 될 것입니다. 그러나 현실적으로는 일관되게 스타일만 다른 대용량 병렬 말뭉치를 만들기가 쉽지 않고, 딥러닝 기반의 Seq2Seq Generation[1, 2] 과정에서 생성 자유도를 컨트롤하기가 쉽지 않습니다.
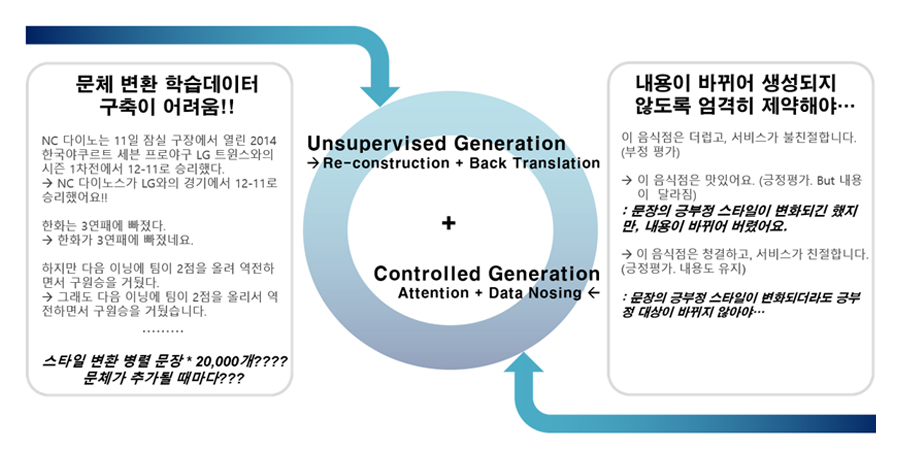
이러한 문제를 해결하기 위해 우리는 Reconstruction과 Back Translation을 기법[3]을 활용한 일종의 Unsupervised Learning을 개발하였습니다. 즉, 문체 변환 병렬 말뭉치가 없이 학습하는 것인데요. 예를 들면, 문어체를 구어체로 변환하기 위한 Supervised Learning이 <문어체 문장1, 구어체 문장2>, <문어체 문장2, 구어체 문장2>로 이루어진 대량의 학습데이터가 필요로 된다면, 제안하는 방법은 문어체 문장 왕창, 구어체 문장 왕창 따로따로 있기만 하면 된다는 것이죠.
이 문제를 수식으로 정의하자면 문체 s의 말뭉치 X={x1,x2,…,xM}와 문체 t의 말뭉치 Y={y1,y2,…,yN}가 주어졌을 때, Ps→t(y|x), Pt→s(x|y)의 조건부 확률 분포를 학습하는 것이 목표입니다. 여기서는 기본적으로 Attention 기반 Seq2seq 모델[1]을 도입하였는데요. 전체적인 시스템의 흐름은 1개의 인코더와 2개의 디코더로 이루어진 아래 두 그림으로 설명할 수 있습니다.
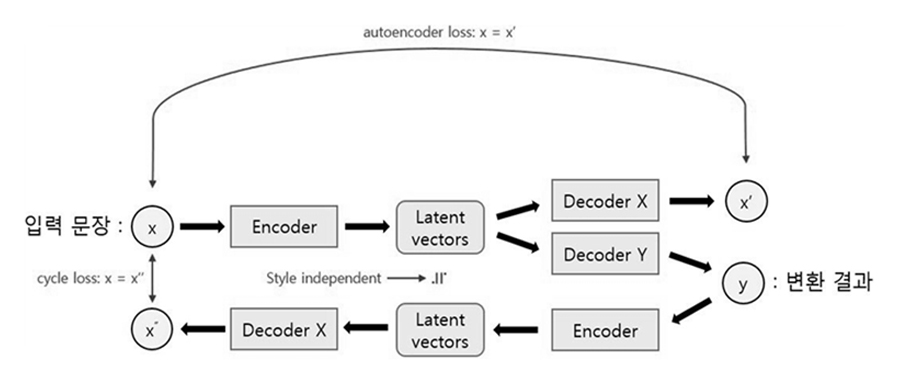
입력 문장 인코딩(Encoding)에 사용되는 한 개의 RNN 인코더는 문체와는 무관한 하나의 분포 공간에서 입력 문장을 벡터의 List로 표현합니다. 디코딩(Decoding)에 사용되는 디코더는 문체당 하나씩 총 2개의 RNN 디코더를 정의하여 각각의 문체에 의존적으로 학습되는데요.
예를 들면 문어체 디코더는 문어체를 생성하도록, 구어체 디코더는 구어체를 생성하도록 먼저 학습합니다. 그리고 나서, 문체 변환 학습 시에는 구어체 디코더의 생성 결과를 다시 원문 문어체로 변환하게 하여 그 내용이 유지되도록(Lcyc를 최소화하는 방향) 학습하는 것입니다.
또, 이 연구에서는 Controlled Generation을 위해 Attention과 Data Nosing 기법을 활용하였는데요.[6, 7] Attention 기법이 사용되지 않는 VAE등의 Autoencoder 또는 GAN 기반의 방법론[4, 5]은 스타일 변환 능력에 비해 정보 보존 능력이 매우 떨어지고 이런 현상은 특히 대상 문장이 길어질수록 확연하게 드러나는 것을 실험을 통해 볼 수 있었습니다.
따라서, Attention 기반의 생성 방법론을 도입하게 되었는데, 이 경우에는 정보 보존에서 강점을 가지지만 반대로 문체에 따라 변환되어야 할 어절들을 과도하게 보존하는 현상이 나타남도 확인할 수 있었죠. Copy mechanism[11, 12] 또한 비교사 환경에서는 직접 적용이 불가능해 이 문제를 더욱 해결하기가 어려웠습니다.
이 연구에서는 Attention을 활용하되, 과보존을 방지하기 위해 확률적 word drop-out을 사용했습니다. 여기서 확률이라는 것은 문체의 특성이 뚜렷한 어절들에 대해 높은 빈도로 word dropout하게 하는 것입니다. 이를 위해 임의의 어절 w의 중립도를 아래와 같이 정의했습니다.
N(w) = 1 –ㅣP (sㅣw) - P (tㅣw)ㅣ
임의의 문장 ?={?1,?2,…,?m}에 대해, 각 어절 ??를 ??∙(1−?(??))의 확률로 으로 치환하는 것입니다. 예시 문장이 전체 네트워크를 통해 변화되는 모습은 아래 그림과 같은데요.
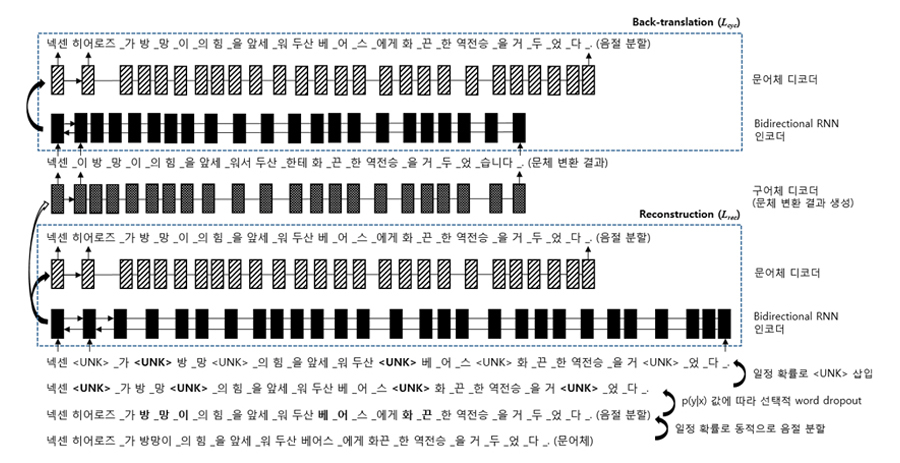
입력 문장에 음절 분할, 확률적 word dropout, UNK 삽입 등의 Noising 과정을 통해 입력 인코딩에서의 과적합을 억제하고, 재구성(Reconstruction)과 재변환(Back-translation) 과정을 통해 문체 변환 능력을 학습하는 것을 볼 수 있습니다.
이러한 방식은 다양한 문체 데이터를 별도로 수집하기만 하면 그 문체에 맞도록 입력문을 바꿀 수 있는 방식으로 현재 Supervised Learning으로 개발된 시스템과 거의 유사한 성능을 보여주고 있습니다.
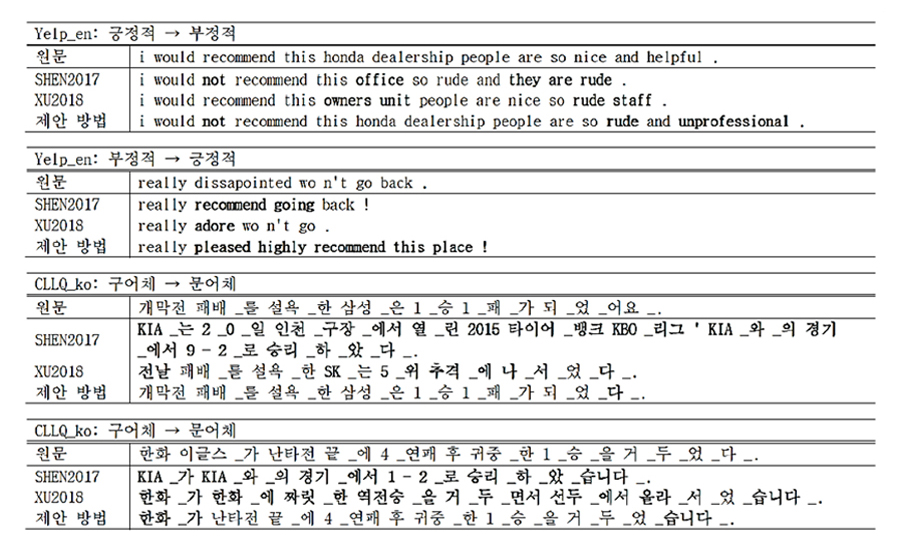
아래 그림은 변환 결과에 대한 예제인데요. 영어에 대해서, 한국어에 대해, 다양한 문체 변환 테스크에 대해 앞에서 설명한 학습 모델이 다른 모델들에 비해 내용 보존과 스타일 변환을 동시에 잘 하고 있음을 보여줍니다. (보다 자세한 실험 결과는 제30회 한글 및 한국어 정보처리 학술대회의 논문집에서 볼 수 있습니다. 관련 링크)
여기서 소개할 연구는 정답이 없는 문제에 대해 AI가 수 많은 현상들을 관찰하면서 “…는 이런 것 같아.”라고 그럴 듯한 의견을 제시하는 것입니다. 이러한 문제를 우리가 어떻게 모델링하고 풀어 가는가를 현재 진행하고 있는 Unsupervised Narrative Learning 연구 사례를 통해 설명하고자 합니다.
페이지는 현재 야구와 관련된 뉴스를 요약해서 보여줍니다. 동일하거나 유사한 뉴스를 클러스터링하고 이 중에서도 핵심적인 문장만을 선별하여 보여줌으로써, 최소한의 노력으로 한번에 많은 정보를 파악할 수 있도록 하는 것이죠. 그러나 우리는 이러한 방식에서 좀더 나아가 현재 시점의 뉴스 전달뿐 아니라, 이 뉴스의 Narrative(서사)에 대한 전달을 고민하고 있습니다.
왜 이러한 일이 일어났으며, 어떤 사건으로부터 시작 되었는지, 어떤 사건과 유의미하게 연결되어 있는지를 AI가 분석하고 전달할 수 있도록 하는 것이죠. 물론 이러한 것은 정답이 있는 문제도 아니고, 전문가라도 의견이 서로 다를 수 있을 것입니다. 하지만 많은 데이터를 통해 그럴 듯한 흐름이 발견되었을 때 AI는 유의미하게 연관성이 있을 수 있다는 정도의 의견을 제시할 수 있을 것입니다. (우리는 이러한 일련의 연관된 시퀀스를 Narrative라고 합니다.)
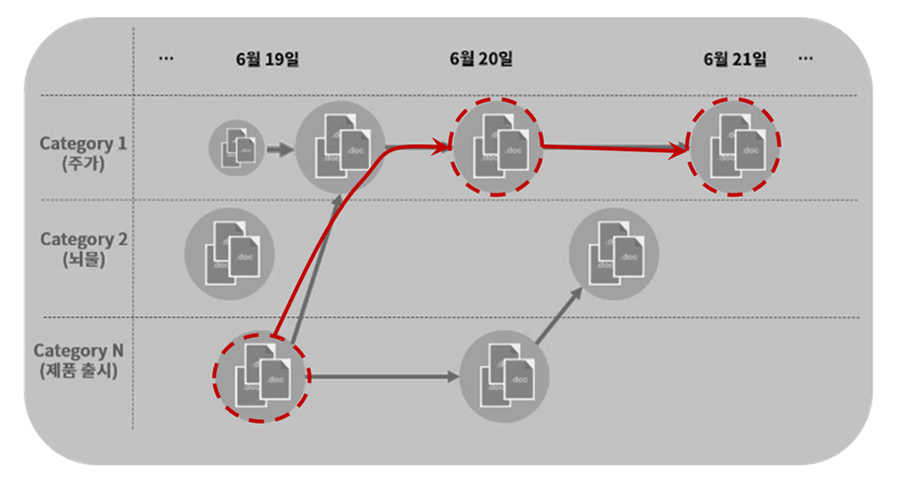
언어(Language)AI랩에서는 이러한 일련의 인과관계를 모델링하기 위한 방법으로 Poisson Point Process의 일종인 Hawkes Process[8, 9]를 확장하여 VHP(Vectorized Hawkes Process)는 것을 개발하고 있는데요.
아래는 하나의 Narrative 하에 있는 사건들의 인과관계를 모델링하기 위한 이 Hawkes Process를 도식화한 것입니다. 임의의 시간에 특정 이벤트가 발생하면, 그 후 짧은 기간 동안 해당 사건에 영향을 받아 추가적인 사건이 발생할 확률이 급격하게 증가했다가 점차적으로 감소하는 현상을 모델링할 수 있는 방법입니다.
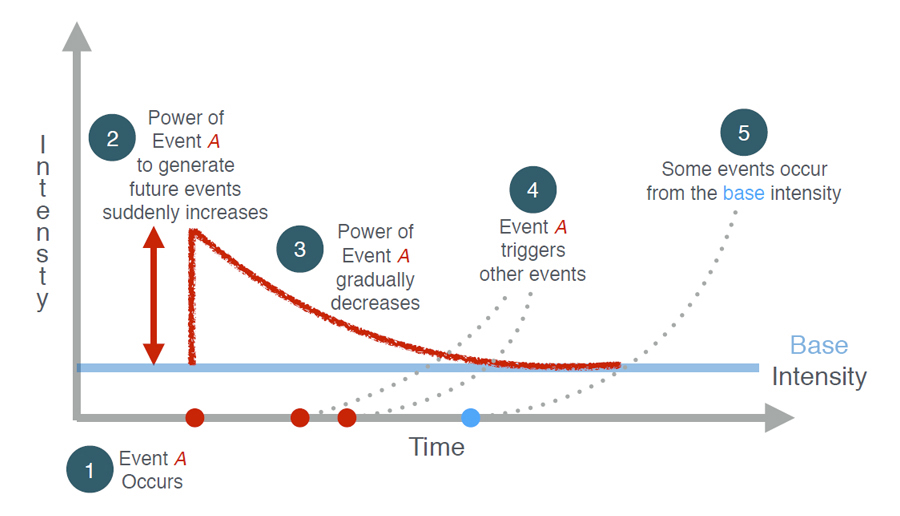
만약 시간에 따른 흐름을 가진 대량의 데이터를 가지고 있고, 각 데이터의 속성을 알 수 있다면 Bayesian Learning을 통해 이 모델의 각 파라미터를 학습할 수 있을 것입니다.
이러한 데이터가 바로 뉴스 기사입니다. Topic modeling을 통하여 데이터 내에서 어떤 사건이 언제, 얼마만큼의 비중으로 존재하는지 파악할 수 있고, 타임라인에 따른 발생 여부를 알고 있기 때문에 HP의 각 파라미터 학습을 통해 사건 간에는 어떤 관계가 있는지를 모델링할 수 있습니다.
문서의 토픽 모델링을 통해 얻은 벡터 표현을 Hawkes process에 적용하기 위해 기존의 Hawkes process를 확장할 필요가 있는데요. 이와 관련된 자세한 수식과 방법은 논문(관련 링크) 내 3~5 섹션을 참고하면 됩니다.
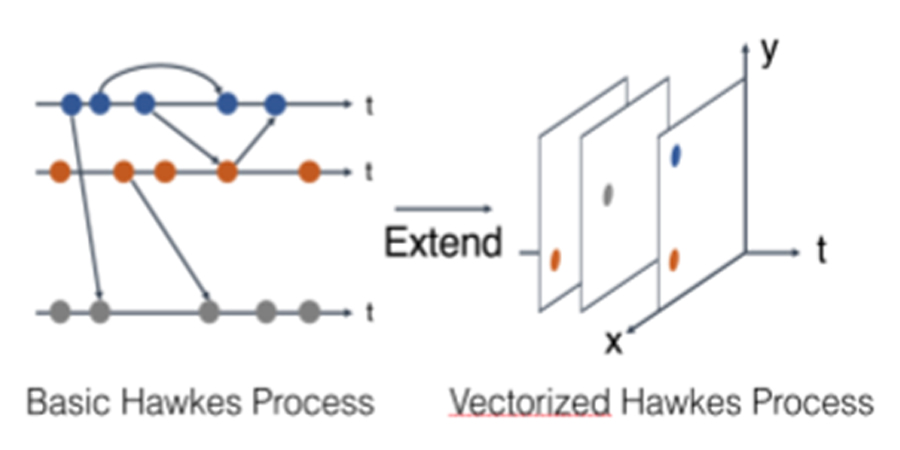
위의 그림과 같이 하나의 점으로 표현되는 사건(문서)이 VHP에서는 임의의 벡터값으로 표현됩니다. 그리고, VHP에서 가장 최근에 발생한 사건은 기존 사건과 상관없이 독립적으로 발생했거나, 혹은 기존에 발생했던 사건에 영향을 받아 발생하는 두 가지 경우를 가정하고 있습니다.
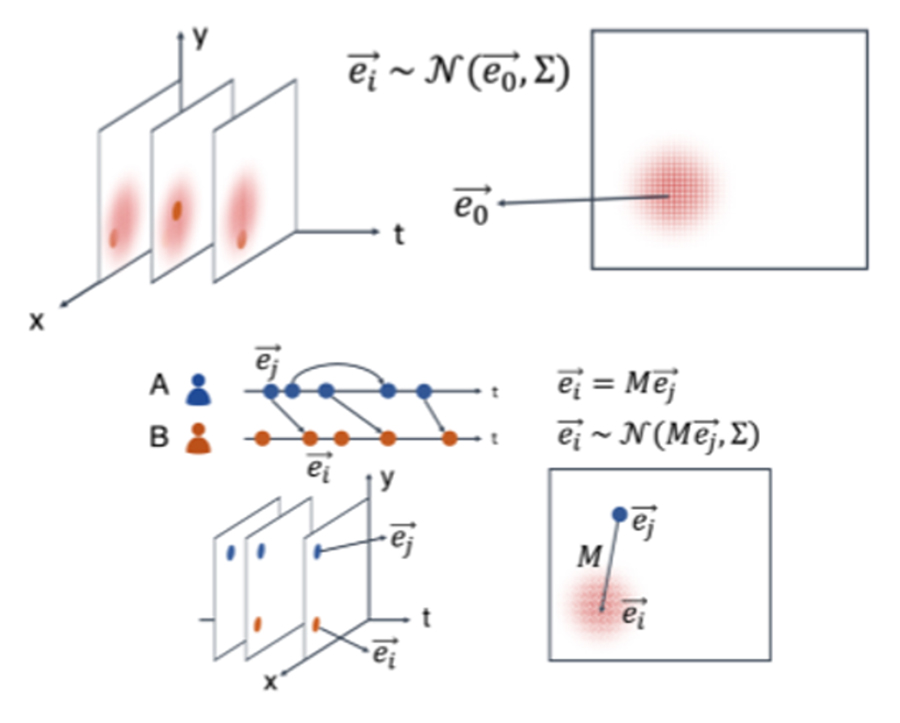
언어(Language)AI랩과 함께 산학 연구를 수행하여 이번 EMNLP에서 발표하게 된 논문(관련 링크)에서는 이러한 이벤트 발생 모델을 GMHP(Gaussian Marked Hawkes Processes)라고도 하였는데요. 이 연구를 보면 영어 뉴스 데이터에 대해 실험 결과를 볼 수 있습니다. 보다 자세한 수식과 학습 방법은 이 논문을 참고하면 될 것 같습니다.
이번 글에서 소개한 연구들은 엔씨소프트의 언어(Language)AI랩에서 실험실적인 환경이 아닌, 실제 노이즈한 환경, 데이터 구축이 어려운 상황, 경험을 통해서만 유추할 수 있는 불확실성이 많은 문제 등을 위해 어떤 연구들을 수행하고 있는지 설명하였습니다. 그 외에도 질의 응답이 아닌 오픈 도메인 채팅 모델, 대화 문맥에 대한 이해, 도메인 트랜스퍼, 강화학습에 기반한 연구 등 다양한 연구들이 현재 진행 중입니다.
아직 소개되지 않은 이러한 연구들이 페이지가 진화하면서 혹은 엔씨소프트의 다른 AI Product를 통해 계속 보여지기를 기대하고 있고, 다음에는 그에 관한 이야기도 할 수 있는 기회가 있으면 좋겠습니다.
[1] D. Bahdanau, K. Cho and Y. Bengio, “Neural machine translation by jointly learning to align and translate”, ICLR, 2015.
[2] A. Vaswani, N. Shazeer, N.Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser and I. Polosukhin, “Attention Is All You Need”, NIPS, 2017.
[3] J. Zhu, T. Park, P. Isola and A. A. Efros, “Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks”, ICCV, 2017.
[4] T. Shen, T. Lei, R. Barzilay and T. Jaakkola, “Style Transfer from Non-Parallel Text by Cross-Alignment”, NIPS, 2017.
[5] Z. Hu, Z. Yang, X. Liang, R. Salakhutdinov and E. P. Xing, “Toward Controlled Generation of Text”, ICML, 2017.
[6] Z. Xie, S. I. Wang, J. Li, D. Lévy, A. Nie, D. Jurafsky and A. Y. Ng, “Data Noising as Smoothing in Neural Network Language Models”, ICLR, 2017.
[7] T. Kudo, “Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates”, ACL, 2018.
[8] Charalampos Mavroforakis, Isabel Valera, and Manuel Gomez-Rodriguez. 2017. Modeling the dynamics of learning activity on the web. In WWW.
[9] Martin Jankowiak and Manuel Gomez-Rodriguez. 2017. Uncovering the spatiotemporal patterns of collective social activity. In SIAM International Conference on Data Mining.

변증현

노형종

이연수
RELATED


