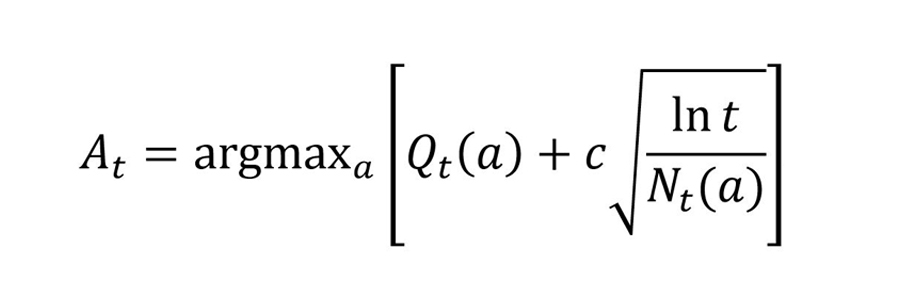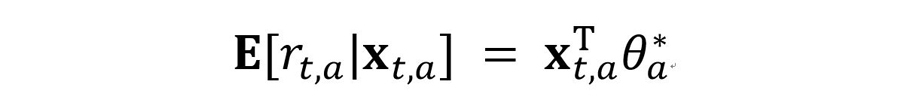AI에 대한 R&D를 선도하고 있는 엔씨소프트.
엔씨소프트의 Knowledge AI Lab에서는 수시로 발생하는 정형/비정형데이터를 수집하고 이를 분석/추론하여 구조화(Structuring)하는 기술을 개발하고 있습니다. 이렇게 수집/생성/추론한 Knowledge를 효과적으로 활용하고 사용자에게 전달하는 기술도 연구하고 있습니다.
이번 글에서는 사용자가 좋아할만한 Knowledge/Content를 효과적으로 제공하기 위한 Curation 기술을 소개하겠습니다.
큐레이션(Curation 또는 Recommendation) 기술은 사용자(User)와 콘텐츠(Content)를 Context를 반영하여 적절하게 연결하는 것입니다.
이를 위해서는 사용자, 콘텐츠, 상황을 잘 파악하고 표현하는 것이 중요합니다. 기본적으로는 성, 연령, 지역과 같은 사용자 정보와 상품 카테고리, 뉴스 분류, 가격 등의 콘텐츠 정보를 확보하여 활용할 수 있습니다.
그러나 현실에서는 이러한 Explicit 정보를 정확하게 확보하기 쉽지 않고, 수시로 변하는 사용자 성향이나 서비스 환경의 변화를 반영하기에는 한계가 있습니다.
그래서 실제 서비스 이용데이터를 기반으로 Implicit 정보를 추론하여 사용자와 콘텐츠 정보로 수치적으로 표현하고, ‘어떠한 사용자가 어떠한 콘텐츠를 선호하는지’를 과거 데이터를 기반으로 학습하여 Curation하고 있습니다. 이러한 방법으로 Collaborative Filtering, Content-Based Filtering은 물론 Networks Analysis, Deep-Learning 등의 다양한 기계학습 기반 Curation 기법들이 시도되고 있습니다.
이러한 Curation 기술을 실제 서비스에 활용하는 경우에 사용자들이 느끼는 성능은, 데이터 기반의 기계학습 성능뿐만 아니라 Cold-start에서의 대응방안, Adaptation 성능, 효율적인 A/B 테스트 방법론에 의해 좌우된다고 할 수 있습니다.
기본적인 Curation 기술들이 서비스 데이터를 기반으로 하기 때문에 관련 데이터가 없거나 부족한 경우인 Cold-Start 상황에서의 효과적인 대처방안이 필요합니다. 수시로 변하는 사용자의 성향을 신속하게 반영할 수 있는 Adaptation 기술 또한 중요합니다. 그리고 과거 데이터가 아닌 실제 사용자의 피드백을 통해 Curation 기술을 평가/개선하기 위한 효율적이고 체계적인 A/B 테스트 방안이 마련되어 있어야 합니다.
Knowledge AI Lab에서는 이러한 이슈에 대한 기술 경쟁력과 서비스 Know-how를 축적하기 위해 관련 업무를 진행하고 있습니다.
위의 기술 요소들 중에서 페이지(PAIGE)에서 진행한 Adaptation과 A/B테스트 관련 내용을 중심으로 소개하겠습니다. 서비스 이용 데이터를 기반으로 한 Curation 기술들은 관련 자료와 논문이 많고, Cold-Start 관련 내용은 지난 연재물 ‘커뮤니케이션과 AI#2 흥미로운 소식을 전해주는 페이지(PAIGE)’에서 이미 소개한 부분이 있어 이번에는 제외하였습니다.
수시로 변화하는 사용자 성향과 신규 콘텐츠를 빠르게 반영하는 Adaptation 방안
페이지는 한국 프로야구 관련 다양하고 재미있는 정보를 인공지능 기술을 더하여 사용자에게 스마트하게 제공하는 서비스로, 야구 경기 정보, 팀과 선수 정보, 야구 관련 뉴스 등의 콘텐츠 카드를 생성한 후 사용자의 선호도에 맞게 Curation하여 보여주고 있습니다.
페이지에서 Curation 대상 콘텐츠는 빈번하게 변화하는 특성을 갖고 있습니다. 각 콘텐츠는 그 날의 경기 결과에 따라 매일 업데이트되고, 관련 뉴스는 하루에 수백 건 이상 생성되어 쏟아지기 때문입니다.
특히, 뉴스는 시간이 지남에 따라 정보로서 가치가 떨어지고 새로운 정보로 끊임없이 대체되는 특성을 가지고 있습니다. 따라서, 수시로 새로운 콘텐츠가 생성되고, 콘텐츠가 유효한 기간이 하루 미만으로 짧은 경우에도 빠르게 학습하여 추천해줄 수 있는 Curation 알고리즘이 필요합니다.
기존 전통적인 추천 시스템으로 협업 필터링(Collaborative Filtering)과 콘텐츠 기반 필터링(Content-based Filtering)이 있습니다.
협업 필터링은 과거 행동 데이터 기반, 유사한 성향의 사용자들이 좋아하는 콘텐츠를 추천해주는 방식으로, 사용자간 행동 또는 소비 패턴이 겹치는 경향이 많거나 또는 콘텐츠 Pool의 변화가 거의 없는, 정적인 환경에서 우수한 성능을 보입니다.
콘텐츠 기반 필터링은 콘텐츠 자체를 분석하여 유사한 콘텐츠를 추천하는 방식이며, 협업 필터링에서 발생하는 Cold Start 문제를 해결할 수 있다는 장점은 있으나, 사용자가 과거에 본 콘텐츠와 항상 유사한 콘텐츠만을 추천하게 됩니다.
따라서, 페이지 서비스같이 다양한 주제의 인기 뉴스가 수시로 생성되고, 경기 정보나 퀴즈 등 성격이 다른 콘텐츠 유형이 혼재된 경우 추천에 적합한 강화학습의 Multi-Armed Bandits 알고리즘을 연구하고 있습니다.
강화학습과 MAB
강화학습(Reinforcement Learning)은 머신러닝의 한 분야로 사람처럼 환경과 상호작용하면서 스스로 학습하는 방식을 의미합니다. 강화학습은 자신의 행동 결과인 보상을 많이 얻기 위해 학습을 진행합니다.
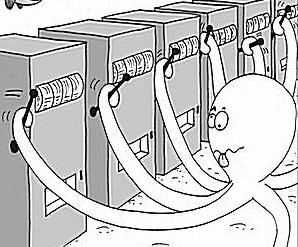
Figure 1. Multi-Armed Bandits (출처: MS Research)
강화학습 알고리즘 중 하나인 MAB(Multi-Armed Bandits)는 Figure 1과 같이, 손잡이가 여러 개인 슬롯머신을 의미하며, 각 손잡이는 서로 다른 확률로 보상을 제공합니다. MAB는 Agent, 즉, 사용자가 어느 손잡이를 당겨야 가장 높은 수익을 올릴 수 있을지 결정하는 알고리즘입니다.
MAB는 추천에서 Exploitation(이용)과 Exploration(탐색)을 균형있게 조절하는 중요한 Framework입니다. Exploitation은 사용자가 많이 소비할 것 같은 콘텐츠를 예측하여 추천하는 반면, Exploration은 더 많은 정보를 수집하기 위해 불확실성이 높은 콘텐츠를 추천합니다. 기존 Exploitation 기반 추천에서는 인기 콘텐츠 위주로 추천되는 한계가 있었는데, Exploration을 통해 신규 아이템도 추천되고 해당 아이템에 대한 사용자 피드백을 확인하여 시스템에 반영할 수 있습니다.
Exploitation과 Exploration 사이에는 Trade-off가 존재합니다. 즉, 현재 가진 정보에서 이익을 극대화는 것과 더 많은 정보를 수집하여 추천에 반영하는 것을 적절히 조절해야 합니다. 예를 들어 온라인 광고의 경우 CPC(Cost-per-Click) 과금을 따르기 때문에, 사용자가 클릭할 것 같은 맞춤 광고만을 노출하는 것이 단기적인 이익 측면에서 바람직합니다.
그러나 기존에 클릭 확률이 높은 광고만을 노출하다 보면, 사용자가 아직 보지 않았지만 관심 있을 수 있는 광고들이 노출될 기회가 없게 됩니다. 따라서 Exploitation과 Exploration을 조절하는 것이 당장의 이익에는 손해일 수 있으나, Exploration을 통해 사용자의 관심 광고 Pool이 늘어나므로 장기적 관점에서는 더 큰 이익을 가져올 것입니다. 이와 같이, 장기적으로 최종 누적 Reward를 최대화하는 것이 MAB의 궁극적인 목표입니다.
MAB에는 다음 세 가지 대표 알고리즘이 있습니다.
1. ε-greedy
Greedy 알고리즘은 Reward가 가장 높은 Arm을 추천해주는 방식으로, Exploration은 고려하지 않는데, ε-greedy 알고리즘은 (1- ε) 확률로 Greedy한 Arm을 추천하고 ε 확률로 Random한 Arm을 추천해주는 방식입니다. 또한, 시간이 지날수록 단계적으로 εt를 줄여 나가는 Decaying ε-greedy 알고리즘 방식도 있습니다.
2. Thompson Sampling
Thompson Sampling은 과거에 관측된 데이터를 이용하여 Reward 분포를 추정한 뒤, 해당 분포를 통해 가장 높은 Reward를 줄 Arm을, 높은 확률로 선택해 주는 알고리즘입니다. 가장 기본적인 Thompson Sampling에서 각 Arm의 Reward는 베르누이 시행에 의해 p의 확률로 0 또는 1의 값을 가지며 p의 prior를 Beta 분포로 가정합니다. Beta 분포는 두 가지 파라미터 (α,β) 에 의해 [0, 1] 구간에서 정의되는 연속확률 분포이며, 일반적으로 α값이 크면 1에 가까울 확률이 높아지고 β값이 크면 0에 가까운 확률이 높은 분포입니다. 여기서, 파라미터 α,β 는 각각의 Arm에서 Reward가 1, 0이 나온 횟수를 사용하여 추정합니다. 즉, 어떤 Arm에서 Reward 1, 0이 각각 3회, 2회 나왔다면 해당 Arm 의 Reward 확률 p는 Beta(3, 2)의 분포를 갖는다고 추정하게 됩니다. 이렇게 추정한 분포에 Probability Matching을 이용하여 Arm을 선택하게 되는데, 이는 각각 Arm의 Reward 확률 p가 최대가 될 확률만큼 부여하여 선택하는 방법입니다.
3. UCB (Upper Confidence Bound)
UCB는 각 Arm을 선택한 횟수 또는 반응률 등을 Reward로 가정했을 때, 해당 Reward의 Upper Confidence Bound를 계산하여 Uncertainty Weight로 활용하는 알고리즘입니다. UCB의 이론적 배경이 되는 호에프딩 부등식(Hoeffding’s Inequality)은 아래와 같이 정의됩니다.
t 시점에서 UCB 기반 Arm을 선택하는 기준은 다음과 같습니다.
단, At: UCB가 최대값인 Arm, Qt (a): t 시점까지 Arm a의 누적 Reward, Nt (a): t시점 전까지 Action a가 선택된 횟수, c>0: Exploration 정도를 조절하는 변수
여기서, Nt (a)가 0인 경우, At는 무한대가 되어 선택 받게 됩니다. 즉, 모든 Arm이 처음 선택되는 초기 단계에서는 무작위로 Arm이 선택됩니다.
앞서 소개한 세 가지 MAB 알고리즘의 성능을 비교하기 위해, 3개의 Arm 분포가 Bernoulli(p)를 따른다고 가정하고, (단, p ~ uniform(0,1)) Arm 별 데이터를 Random Generation하여 1,000번 Simulation한 결과, 각 Step별 평균 Reward를 계산하여 비교하였습니다(단, Reference [1]에서와 동일하게 c=2로 가정).
Figure 2와 같이, 초반에 각 Arm들에 대해 정보가 없을 때 탐색하며 시행착오를 겪는 기간을 제외하면, 시간이 갈수록 세 알고리즘 모두 안정된 성능을 보여주었고, Thompson Sampling이 다른 알고리즘에 비해 Average Reward 면에서 가장 우수한 성능을 보였습니다.
기존 문헌에서도 Thompson Sampling은 Sampling한다는 측면에서 Heuristic하다는 단점은 있으나, 성능 면에서는 가장 우수한 것으로 알려져 있습니다[3]. 따라서, 페이지에 추천 알고리즘으로 Thompson Sampling을 가장 먼저 적용하였고, 추천 성능을 Offline과 Online A/B Test로 평가하였습니다.
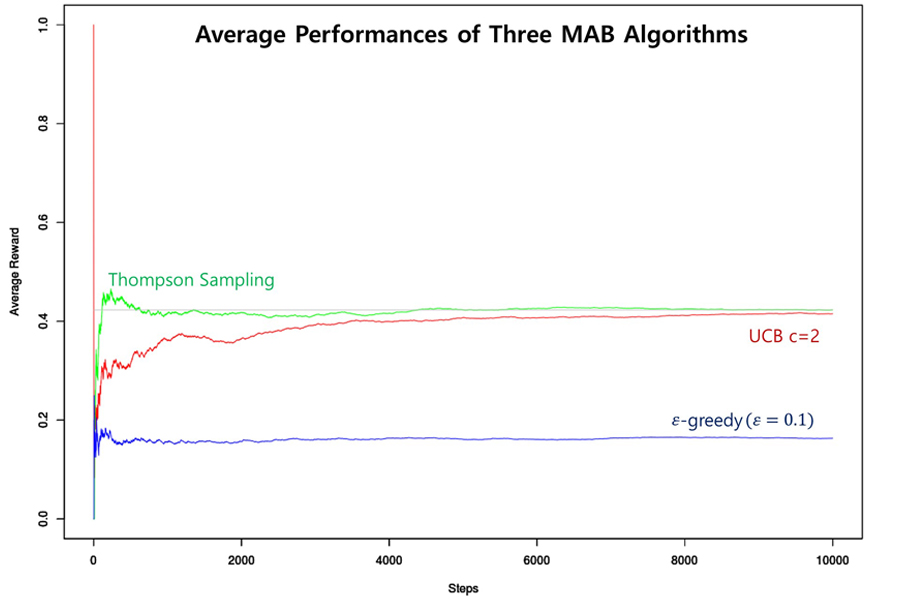
Figure 2. Average Performances of Three MAB Algorithms
Contextual Multi-Armed Bandits: Context (or State) 정보를 함께 고려하는 Bandits
지금까지 설명한 MAB는 각 Arm을 선택하는 환경이 동일한 상황을 가정하였습니다. 그러나, 페이지에서는 Arm을 하나의 카드로 간주할 수 있는데, 시시각각 다양한 카드가 생성되고 사라지며, 관심사가 다른 다양한 사용자들이 존재합니다. 이와 같이, 카드를 추천할 때 달라지는 환경, 즉, 각 카드와 사용자 정보를 Feature로 정의하여 반영하는 것을 Contextual MAB라고 합니다.
사용자와 페이지 콘텐츠 카드는 다양한 Feature 벡터로 나타낼 수 있습니다. 가장 기본적인 사용자 Feature는 Demographic 정보이나, 페이지는 사용자 Demo 정보를 수집하지 않아 여기서는 고려하지 않습니다. Demo 정보를 제외한 사용자 Feature들은 Table 1과 같습니다. (단, 전체 57개 변수 중 일부만 나타냈습니다.)
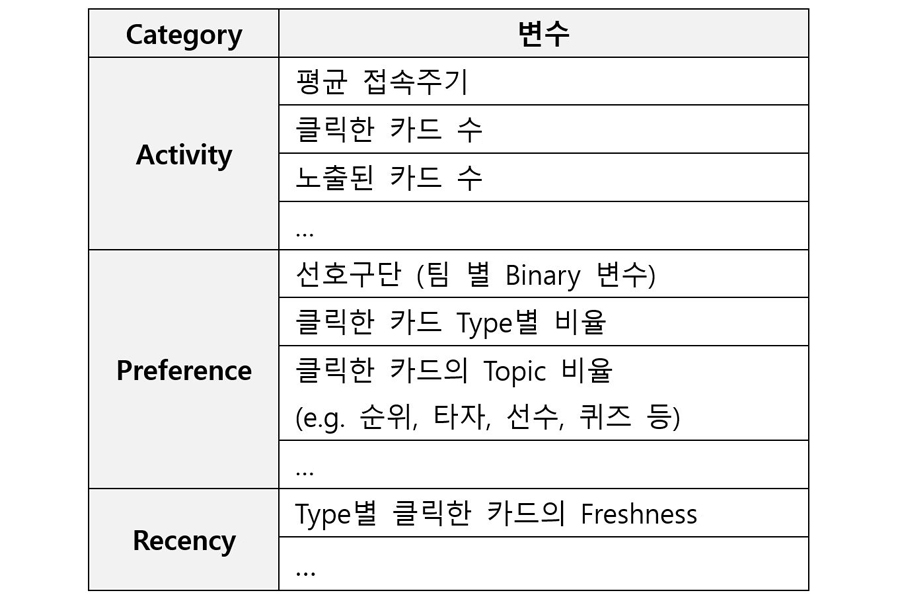
Table 1. 페이지 사용자 Features
페이지 콘텐츠 카드 Feature는 Table 2와 같습니다. (단, 전체 13개 변수 중 일부만 나타냈습니다.)
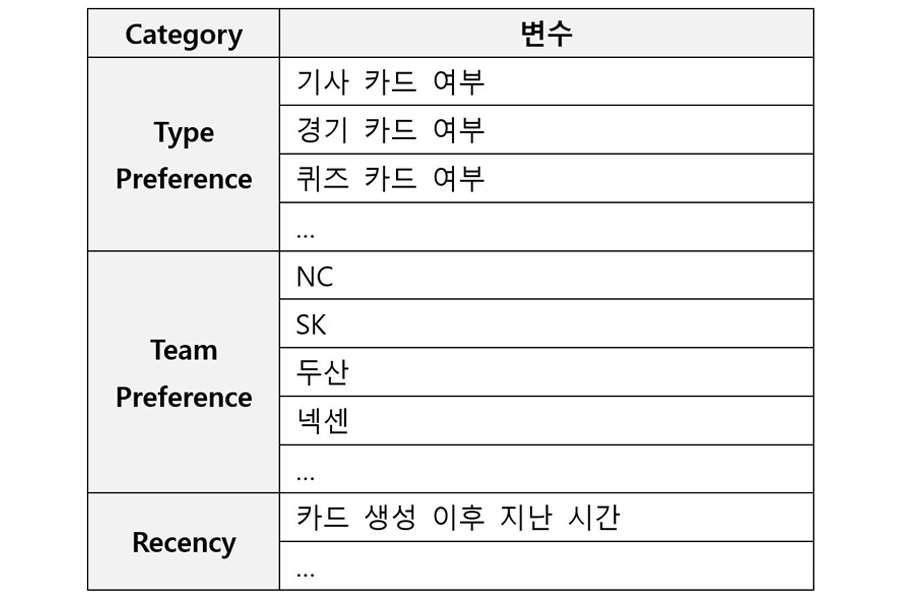
Table 2. 페이지 Card Features
이와 같이 정의한 카드와 사용자 Feature 개수는 총 70개인데, 거의 실시간으로 추출하여 알고리즘에 반영해야 하므로, 주성분 분석 기반 20개 변수로 차원을 축소하여 사용하였습니다.
Linear UCB
앞서 설명한 UCB에 Context Feature를 Linear Model로 고려하여 확장한 알고리즘이 LinUCB (Linear UCB)입니다. Li, L. et al. (2010) [2] 연구에서 해당 알고리즘을 소개하였고 실제 Yahoo 뉴스 추천에 적용하여 우수한 성능을 보였습니다.
LinUCB는 각 Feature별 변수를 카드별로 Disjoint하게 가정했는지, 또는 카드별로 일부 변수를 공유하도록 가정했는지에 따라 Disjoint Linear Model과 Hybrid Linear Model로 분류됩니다. Disjoint Model에서는 카드별로 각각 Model을 가정하고 학습하는 반면, Hybrid Model에서는 카드별로 학습하는 변수와 모든 카드에 대해 학습하는 변수가 각각 존재합니다. 페이지에서는 먼저 Disjoint Linear Model 기반 LinUCB를 적용했습니다.
Disjoint Linear Model 기반 LinUCB는 카드별 기대 Reward값이 d차원의 Feature xt,a와 선형 관계라고 가정합니다. 단, θa*는 Unknown Coefficient Vector입니다.
Disjoint Linear Model을 가정한 LinUCB의 알고리즘 Psuedocode는 다음과 같습니다.
여기서 Exploration 가중치를 나타내는 최적의 α값은 Simulation을 통해 결정하고, Feature 기반 Linear Model의 파라미터를 추정하기 위해 Ridge Regression을 사용합니다.
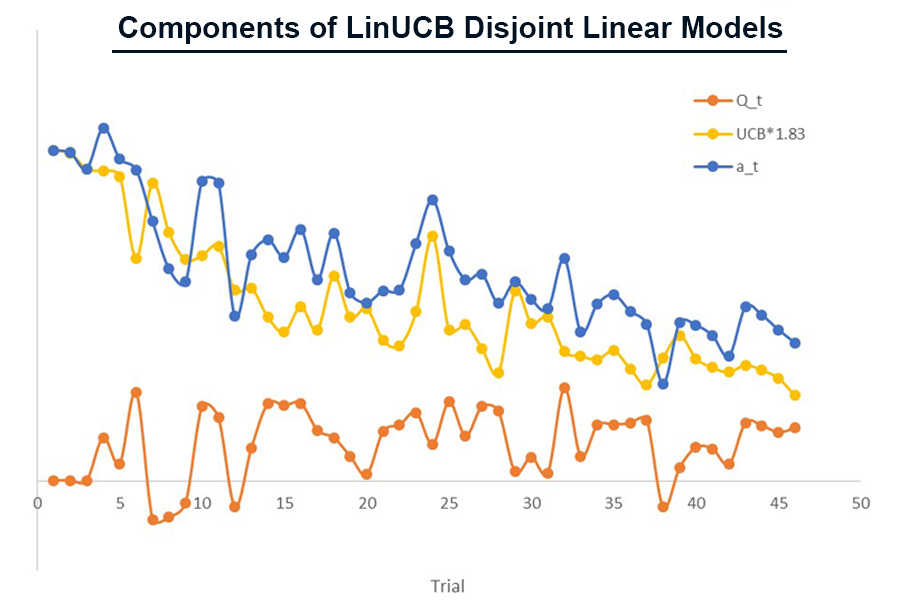
Figure 3의 그래프는 페이지 특정 카드 a에서 Trial에 따라 LinUCB의 구성요소인 Qt, UCB, at 값의 변화를 나타냅니다. Simulation 결과 α는 약 1.83으로 결정되었고, UCB에 곱해서 반영되었습니다. 학습이 진행됨에 따라, Exploration, 즉, Uncertainty Tem인, UCB는 점차 감소하고, 전체 Reward에 미치는 영향도가 Exploitation Term 대비 상대적으로 줄어들게 됩니다.

페이지에서 사용자는 각 카드를 간편하게 Swipe하고, Click하면 내용을 확인할 수 있습니다. LinUCB 알고리즘에서는 각 카드의 Reward가 가장 큰 값을 사용자에게 제공하는데, 페이지에서는 카드를 제공하는 Mechanism상, LinUCB의 Reward값을 Weight로, 내림차순 정렬하여 사용자에게 제공합니다. 즉, 카드별 Reward 값을 Rank로 사용하는 것입니다.
Disjoint Linear Model 기반 LinUCB는 카드별로 학습합니다. 즉, 한 카드의 사용자 로그 데이터는 해당 카드의 모델 학습에만 사용되고, 다른 카드의 LinUCB 모델에는 영향을 주지 않습니다. 실제 서비스에서는 카드별로 정의되는 Feature들도 있지만, 카드 전체가 공유하는 Feature들이 더 많습니다.
페이지 서비스를 예로 들면, 기사 카드와 경기 카드의 경우 콘텐츠 성격은 다르지만 두 카드를 보는 사용자들의 Feature는 공통적으로 정의 가능하고, 모든 카드에 대해 학습시킬 수 있습니다. 따라서, 모든 카드에 공통적으로 적용하는 Feature와 각 카드별로 적용하는 Feature를 각각 고려하여 Linear 모델로 정의한 것이 Hybrid Linear Model 기반 LinUCB로, 다음과 같이 나타낼 수 있습니다. 단, z는 모든 카드에 공통인 Feature 변수이고, β*는 Unknown Coefficient Vector입니다.
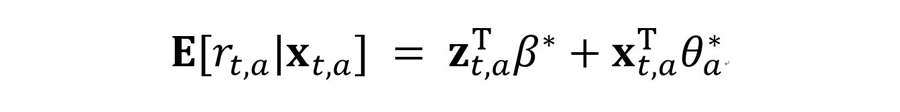
Hybrid Linear Model 기반 LinUCB는 모든 카드에 대해 업데이트 해야 하는 β*와 카드별로 업데이트 하는 θa*가 각각 존재하여, UCB를 계산할 때 Disjoint Linear Model에 비해 계산량이 많고 복잡합니다.
그러나 실제 환경에서 모든 카드에 공통적으로 적용하는 Feature들이 있는 것이 일반적이므로, Hybrid Linear Model 기반 LinUCB가 Disjoint Linear Model보다 현실적인 상황을 좀더 잘 설명한다고 볼 수 있습니다. 현재 페이지에는 Disjoint Linear Model 기반 LinUCB가 적용되어 있지만, 서비스 환경을 보다 현실적으로 반영할 수 있는 Hybrid Linear Model 기반 LinUCB로 향후 변경할 예정입니다. 지면 관계상 Hybrid Linear Model의 Psuedocode는 Reference [2]를 참고하시기 바랍니다.
페이지에 Disjoint Linear Model 기반 LinUCB를 적용하기 전, Thompson Sampling을 적용하면서 Offline과 Online A/B Test를 진행하여 알고리즘 성능을 평가하였습니다. 이후 Section에서는 Thompson Sampling 알고리즘 관련 Offline A/B Test와 Online A/B Test에 대해 설명합니다.
Offline A/B Test
Offline A/B Test는 Off-policy Evaluation의 일종이라고 볼 수 있습니다. 이는 기존에 적용되어 있지 않은 Policy를 적용했을 때 Reward의 기대값이 어떻게 될지를 예측하는 Counterfactual Reasoning 분야의 문제 중 하나인데, 이 Offline A/B Test는 주로 개인화가 적용되어 있는 Curation 서비스를 개선하기 위해서 사용됩니다.
대부분 여러 개의 상품이나 서비스를 노출시키는 온라인 서비스는 추천 알고리즘의 수정이 이루어질 때마다, 실제 라이브 서비스에 적용하기 전에 수정된 알고리즘의 성능 향상을 검증하는 Online A/B Test 또는 추천 실패 비용을 최소화 하면서 보상(ex. CTR, Purchase)을 늘려가는 방식의 MAB(Multi-Armed Bandit) 계열의 알고리즘을 적용하게 됩니다.
이러한 두 가지 기법에는 장점이 많지만 실제 서비스에 적용할 때 다음 두 가지 단점이 있습니다.
- Exploration Cost : 실제 사용자 대상의 실험에 따른 기회비용
- Time Cost : 유의미한 실험 결과를 얻을 때까지 시간이 걸림
따라서, Offline A/B 테스트는 위와 같은 단점을 줄이기 위해서, 기존 On-policy Curation 알고리즘 하에서 쌓인 사용자 반응 데이터를 활용하여 새로운 알고리즘의 Reward 기대값을 History 데이터를 활용해서 추정하는 것입니다. 좀 더 이해하기 쉽게 아래와 같이 표현할 수 있습니다.
“만약 이 알고리즘을 적용시켰더라면 당시 적용시킨 알고리즘보다 CTR, Revenue, Dwell Time 등이 몇 % 증가(감소)했을까?”
현재 MS, Criteo 등 여러 큰 기업에서도 이 방법론을 연구 및 적용하고 있으며, 관련 연구를 살펴보면 검색 엔진[4][5], 광고 배치 최적화[6], 콘텐츠 추천[7] 쪽에 많이 사용되고 있습니다.
Figure 4. 광고 배치의 예시(Vertical, Grid, Horizon)
페이지는 팀, 선수, 뉴스, 퀴즈 카드 등 다양한 콘텐츠를 제공하고 있습니다. 따라서, 사용자 별로 자신의 취향에 맞는 콘텐츠 카드 노출의 개인화가 필요하기 때문에, 앞서 설명한 LinUCB, Thompson Sampling 등과 같은 연구를 통해 페이지 서비스의 콘텐츠를 사용자 맞춤화하기 위해 노력하고 있습니다.
따라서, 이번 Section에서는 페이지의 개인화/추천을 위해, 기존에 적용된 사용자의 선호 팀이 반영된 Thompson Sampling과 테스트 하고자 하는 사용자 선호도 반영을 없앤 Thompson Sampling과의 성능 비교 목적으로, 페이지에 Offline A/B 테스트를 적용해본 과정과 결과를 설명 드리겠습니다.
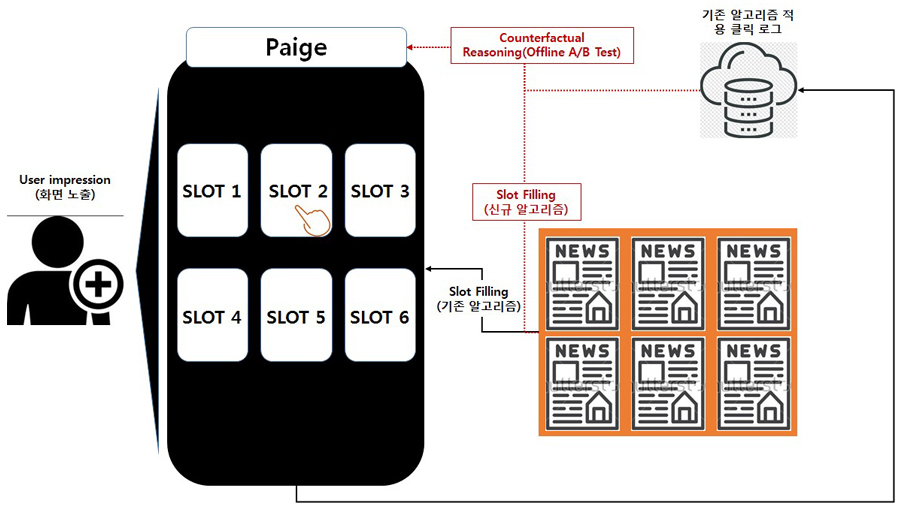
Figure 5. 페이지 서비스 Offline A/B Test 적용 도식
일반적으로 Offline A/B 테스트가 적용되는 상황은 Batch Learning from Bandit Feedback Problem이라고 부르며, 아래의 상황과 같습니다.
1. 사용자에게 추천 알고리즘이 적용된 화면 노출
2. Impression 된 화면에 사용자의 Context에 따라 알고리즘에 따른 Action을 결정해서 화면의 뉴스 Slot에 추천하여 보여줌(기존 알고리즘).
3. 기존 알고리즘 하에서 사용자는 Click(세부적으로는 몇 번 슬롯의 뉴스 기사 클릭)/Non-click의 Label을 남기게 됨.
4. 기존 알고리즘보다 성능이 향상될 것으로 예상되는 신규 알고리즘을 개발 및 적용하여 Online A/B Testing을 진행하기 전에 Offline A/B Testing을 진행하고자 함.
5. 이 신규 알고리즘 Policy와 기존 알고리즘 하 서비스에서 모인 클릭 로그 데이터를 활용하여 Counterfactual Reasoning 수행.
6. 이 알고리즘이 기존 알고리즘보다 얼만큼의 성능 향상을 기대할 수 있을지 Estimation하고 Estimation 결과에 따라 Online A/B 테스트를 수행하여 검증.
위 1 ~ 3 과정은 Figure 6과 같이 우리가 사용할 Feature, Action, Reward, Propensity를 남기게 됩니다.
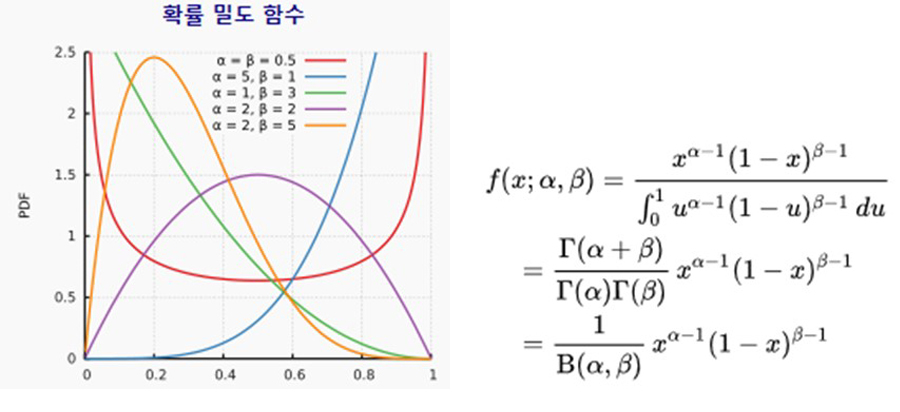
Figure 6. Beta 분포 그래프 예시와 pdf
페이지에서 각 카드는 당시 Click 수와 Non-click 수를 α,β로 가지는 Beta 분포를 가지게 되며 각 카드 별로 생성된, 서로 다른 Beta 분포로부터 뽑힌 값의 순서를 활용하여 사용자에게 노출되는 카드의 순서가 결정이 됩니다. 따라서, 본 Thompson Sampling 기반 추천 알고리즘에서 Feature는 각 카드의 해당 시간대까지의 클릭 수(Click count), 노출 수(Impression count)가 됩니다.
Figure 7에서와 같이, 여러 카드의 Beta 분포로 특정 사용자에게 추천 알고리즘에 따라 임의의 카드를 특정 인덱스 슬롯에 노출시켜주는 것을 Action이라고 정의합니다.
위 과정에서 3의 결과로 Click 여부에 따라서 Reward(0/1)가 기록되게 됩니다. 즉, Reward는 Figure 8과 같이 각 카드가 사용자에게 노출이 되었을 때 해당 카드를 클릭 했는지 여부로 정의됩니다.
마지막으로 Propensity는 P(Action | Feature)의 값으로 정의되는 확률입니다. 페이지 서비스의 예시로 이를 풀어서 해석하면, “현재 우리 추천 알고리즘 하에 사용자 i에게 특정 콘텐츠 카드 j가 k번째에 노출될 확률”을 모든 가능한 i, j, k 쌍에 대해 구하는 과정이라고 보면 됩니다.
Thompson Sampling은 같은 Feature값을 갖더라도 Beta 분포로부터 뽑힌 값이 매번 다르기 때문에 정확하게 이 값을 계산하는 것은 불가능하여, 본 실험에서는 Monte-Carlo Approximation을 활용하여 Propensity의 근사값을 도출하였습니다. 페이지에 적용된 예시를 살펴보면 Table 3과 같습니다. Table 3에서, 각 Cell의 Value는 "Card ID 별 전체 N번 중 해당 Card Order가 된 횟수”, 즉, 첫 Cell이 30인 경우, Card ID 1이 N번 Simulation을 수행했을 때 Card Order가 1이된 횟수가 30회라는 의미입니다.
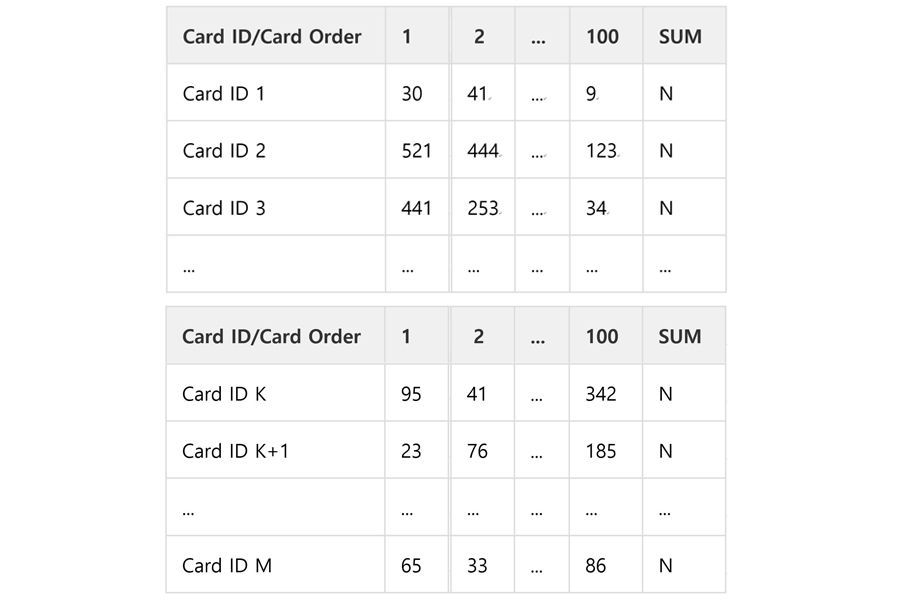
Table 3. Propensity 계산을 위한 MC Approximation 적용 예시: User A의 2018-08-24일 17:40 Entry Session의 노출 후보군과 카드별 Monte Carlo Simulation결과
따라서, 각 Row를 N으로 Normalize해주면, 각 Card ID별로 각 Order Index에 위치할 확률이 계산됩니다. 이는 근사 확률이지만, N값을 충분히 크게 잡는다면 실제 확률에 가까운 값을 구할 수 있습니다.
새로운 알고리즘의 성능을 테스트할 때 기존의 기계학습 알고리즘으로 예측하는 일은 어렵습니다. 기존 알고리즘이 적용된 로그 데이터는 구조적으로 특정 Feature값에 대해서 특정 Action이 많이 발생하도록 되어있는 편향(Biased) 데이터이기 때문입니다.
예를 들면, A라는 Feature에 대해서 B, C, D라는 Action이 존재하는데 로그에는 알고리즘 상 B, C라는 Action만이 존재한다면 A라는 Feature를 가진 사용자가 D라는 Action을 받아들였을 때의 Reward와 같은 정보는 얻을 수 없게 됩니다. 따라서, 이러한 Bandit Data 상황에서 Counterfactual Reasoning 방법론이 기존의 기계학습 방법론에 비해 효과적일 수 있습니다. 본 실험에서는 [7]에서 제안한 NCIS(Normalized Capped Importance Sampling)이라는 방법을 활용하여 기존의 알고리즘(Product Policy)와 신규 알고리즘(New Policy)을 비교하였습니다.
이 NCIS의 방법론에서 Expected Reward를 구하는 식은 아래와 같습니다.

위 Figure 9의 수식에서 πproduct(a|x), πnew(a|x)는 각각 기존 알고리즘과 신규 알고리즘의 Propensity 값을 의미합니다. 수식에 등장하는 c는 두 알고리즘의 Propensity값이 너무 큰 차이가 나서 Ratio가 매우 큰 값을 가짐으로써 추정 시에 발생하는 문제를 제한하기 위한 Cap Value입니다. 즉, 기존 로그의 Impression 데이터의 Reward에 대해 신규 알고리즘과 기존 알고리즘의 Propensity의 Ratio를 Weighted Sum한 값이 신규 알고리즘의 Expected Reward가 됩니다.
이 NCIS를 활용한 실험은 총 2단계로 진행했으며, 기존/신규 알고리즘의 CTR 차이값의 신뢰구간을 구하기 위하여 Bootstrap Sampling을 활용하여 Confidence Interval을 도출하였습니다.
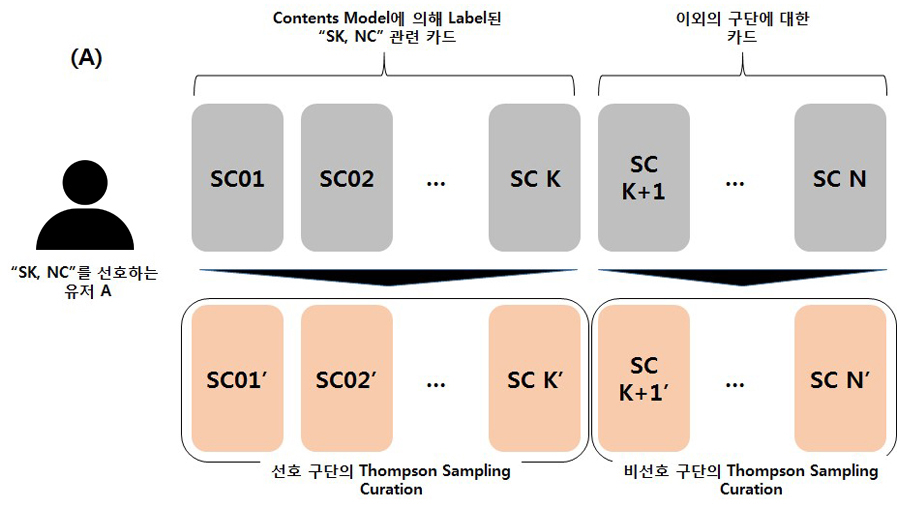
1. Thompson sampling & 선호구단 우선노출 vs. Thompson Sampling (분포 생성 계수 동일)
2. Thompson sampling & 선호구단 우선노출 vs. Thompson Sampling (분포 생성 계수 변경)


Table 5의 2)번 실험 결과에서 95% 신뢰구간이 양의 구간을 가지므로, 신규 알고리즘이 기존 대비 통계적으로 유의미하게 CTR측면에서 더 좋은 성능을 가진다고 결론 내릴 수 있습니다. (이 결과는 다음 Section에서 설명할 Online A/B Test의 결과와도 일치하였습니다.)
Offline A/B 테스트의 결과를 정리하면 다음과 같습니다.
1. Estimator에 따르면 기존의 Thompson Sampling 분포 생성 계수를 바꾸지 않았을 경우에는 유의미한 CTR 증가/감소를 확인하기 어려웠습니다. 그러나, 기존의 Thompson Sampling 분포 생성 계수를 변경한 실험에서는 CTR이 증가하거나 감소하는 경향이 보이며, 이는 Beta 분포의 계수를 바꿔줌으로써
A) 좀 더 Popular한 카드를 강하게 앞에 노출시켜 주는지 또는 인기도와 상관없이 좀 더 Flat하게 노출시켜 주는지 여부
B) 클릭 수에 많은 비중을 두는 분포에서 노출 순서를 결정할 것인지 또는 노출 수를 많이 반영하는 형태의 Beta 분포를 사용할 것인지 여부
등을 조정할 수 있기 때문에 CTR 추정 값에 변화가 발생합니다. 따라서, 파라미터 조정 실험을 더 진행하여, 표로 정리 및 정성적인 해석을 해볼 여지가 있습니다.
2. Beta 분포의 생성 관련 계수를 바꾸지 않았을 경우, 사용자 별 팀 선호도를 반영하지 않고 카드의 전체적인 인기도를 반영하는 전략이 팀의 선호도를 우선시 하는 전략보다 우월한지는 CTR만으로는 알 수 없습니다.
3. 현재까지 실험한 결과에서 Cap Value = 0.8 / AB_Category 기존과 동일 / 계수=7.5 의 조합이 95% 신뢰구간에서 CTR이 유의미하게 기존보다 증가 [0.42%, 1.91%]하는 것을 확인할 수 있습니다. → Thompson Sampling에 사용하는 Beta 분포의 α, β 값 결정에 영향을 미치는 파라미터를 변경하는 것이 좋다는 결론입니다.
이와 같이 Offline A/B 테스트는 Online A/B 테스트를 수행해 볼만한 실험과 아닌 것을 필터링할 수 있으며, 기존의 Offline Batch Log로 모델링을 하기 때문에 서비스에 미치는 비용이 없습니다. 따라서, 실제 서비스에서 인적, 시간적, 서비스적 제약 사항으로 어려웠던 다양한 실험이 가능하며, 이에 대한 근사적 해를 구할 수 있다는 점에서 기존의 테스트와 Curation 알고리즘을 보완할 수 있습니다.
Online A/B Test를 통한 Offline A/B Test 추론 결과의 검증
실제 페이지에 사용된 알고리즘의 유효성을 검증하기 위해 일주일씩 Online A/B Test를 시행하였습니다. 페이지에서 제공하는 카드에는 여러 가지 타입이 있어 각 타입 별로 분석하였고, 카드 타입은 다음과 같습니다.
SC01: 야구기사, SC02: 경기정보, SC07: 팀 랭킹, SC08: 선수 랭킹
페이지에서 스트리밍 카드를 제공할 때 사용자가 선택한 선호 구단 관련 카드를 먼저 제공하는 Logic이 있습니다. 이 Logic에 대한 유효성을 검증하기 위해, Thompson Sampling 알고리즘에서 해당 Logic을 적용한 Thompson Sampling (A) 과 적용하지 않은 Thompson_only (B), 두 가지를 테스트하였습니다.
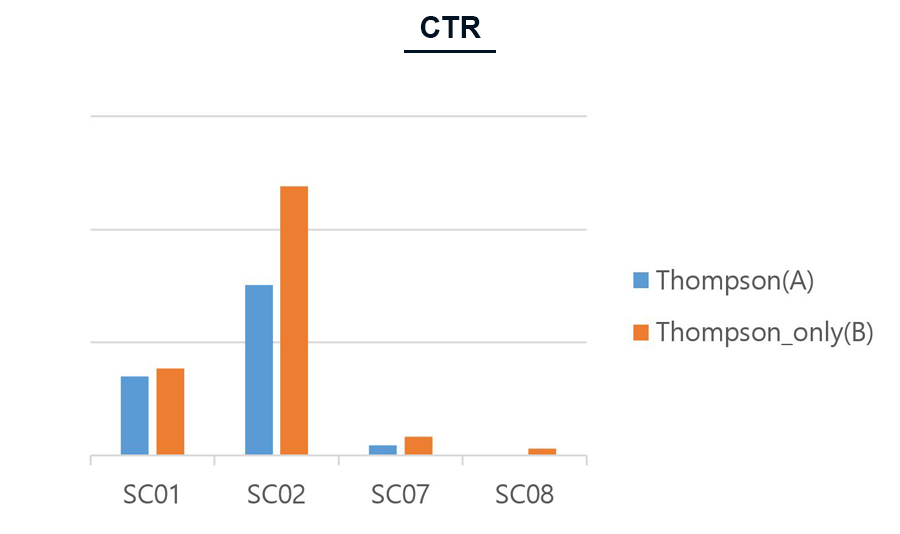
Figure 10. 선호구단 Logic 유무 별 Thompson Sampling 알고리즘의 CTR 비교
카드 타입 별 클릭률 (CTR, Click Through Ratio)을 비교했을 때, 퀴즈를 제외한 다른 카드 타입에서는 오히려 선호구단의 카드를 먼저 제공하는 Logic이 없을 때 클릭률이 좀 더 높은 것을 확인할 수 있습니다.
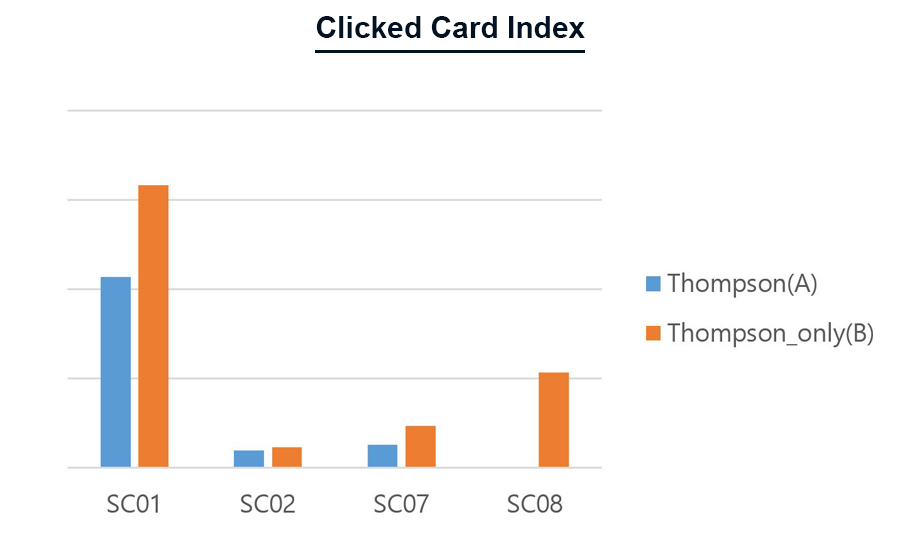
Figure 11. 선호구단 Logic 유무 별 Thompson Sampling 알고리즘의 클릭된 카드 순위 비교
사용자들이 평균적으로 몇 번째 카드를 클릭 했는지 비교하였습니다. 이는 사용자들이 클릭할 카드를 해당 알고리즘이 잘 예측하여 우선순위로 노출시켜 주었는지 판단하려는 목적입니다. 결과적으로 선호구단 관련 카드를 먼저 제공하였을 때(A), 사용자들이 클릭한 카드들이 좀 더 앞에 위치하였습니다. 즉, 선호구단 카드를 먼저 제공해주면 사용자들이 원하는 카드를 좀 더 빠르게 볼 수 있지만, 선호구단 카드의 우선순위를 주지 않으면 더 다양한 카드들을 보는 경향이 있었습니다.
두 번째 실험은 Thompson Sampling 에 적용된 분포의 파라미터를 변경하여 진행했습니다. 즉, Thompson_sc75(B)에서 클릭의 비중이 높도록 파라미터를 설정하여, 클릭률이 높은 카드가 먼저 노출되도록 하였습니다.
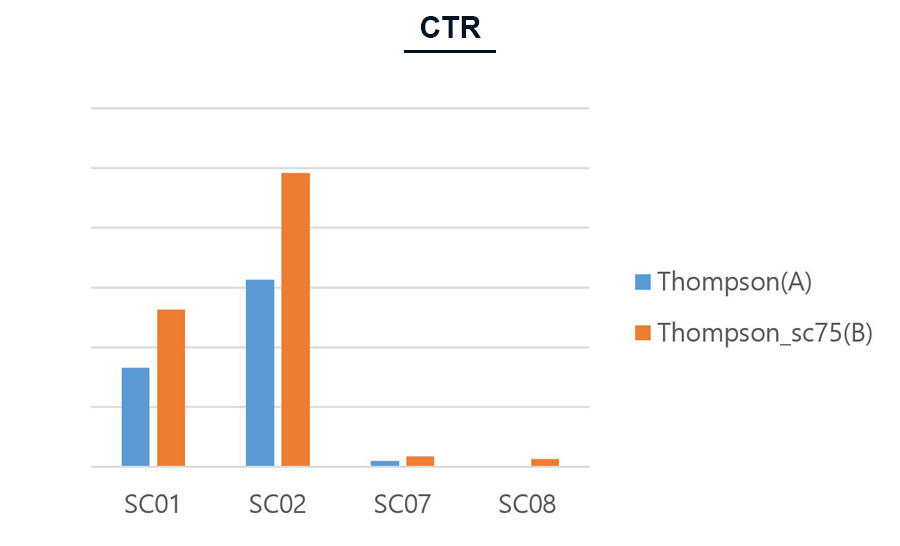
Figure 12. 파라미터에 따른 Thompson Sampling 알고리즘의 CTR 비교
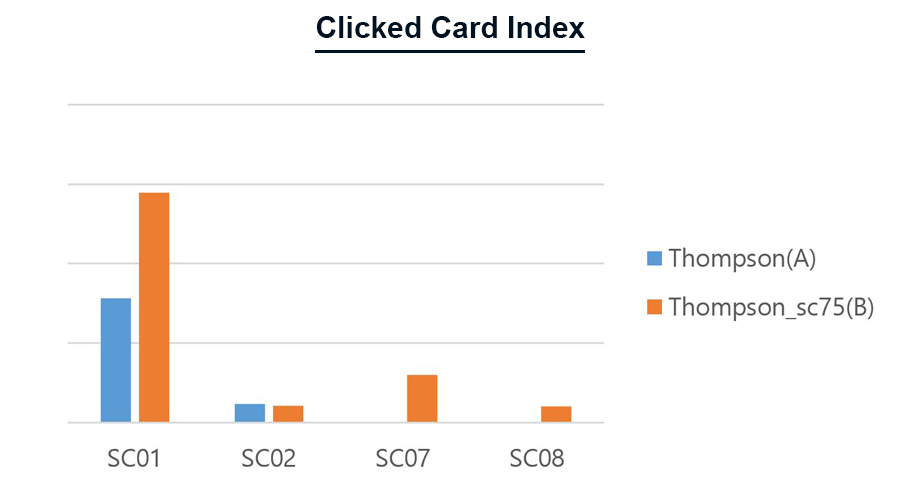
Figure 13. 파라미터에 따른 Thompson Sampling 알고리즘의 클릭된 카드 순위 비교
Figure 12에서와 같이, 파라미터를 변경하였을 때 사용자들의 클릭률이 상승하는 것을 볼 수 있었습니다. 그러나, Figure 13의 알고리즘 별 클릭된 카드 순위에서는, 기본 Thompson Sampling으로 카드를 제공했을 때 사용자들이 클릭한 카드들이 상대적으로 앞에 위치하였습니다. 첫 번째 실험과 마찬가지로, 선호구단을 고려한 Thompson Sampling 알고리즘이 클릭할 카드들을 좀더 앞쪽에 배치시켜 주지만, 알고리즘을 변경하였을 때 좀 더 다양한 카드의 클릭을 유도하는 경향이 있습니다.
지금까지 페이지에 적용된 Multi-Armed Bandits 추천 알고리즘을 소개하고, 각각의 성능을 평가하는 Offline과 Online A/B Test에 대해 설명하였습니다.
그 동안 ‘커뮤니케이션과 AI’를 주제로 페이지에 적용한 Language AI Lab과 Knowledge AI Lab에서 개발하고 있는 기술들을 소개하였습니다. 저희는 앞으로도 Communication AI 기술을 연구하고, 페이지와 같은 기술 기반의 서비스를 지속적으로 시도할 예정입니다.
AI 기술과 서비스는 사용자들의 활발한 이용과 피드백을 통해 발전할 수 있습니다. 많은 관심과 활발한 이용 부탁 드립니다. 마지막으로 저희와 함께 대담한 R&D 목표를 향해 도전할 열정적인 전문가를 항상 기다리고 있습니다. 엔씨소프트 AI R&D에 탑승하세요.
참고 문헌
[1] Sutton, R. S. and Barto, A. G., Reinforcement Learning: An Introduction, Second Edition, in progress. MIT Press, Cambridge, MA, 2017.
[2] Li, et. al (2010), "A Contextual-Bandit Approach to Personalized News Article Recommendation", In Proceedings of the 19th International Conference on World Wide Web, 661-670.
[3] Chapelle, O. and Li, L. (2011), “An Empirical Evaluation of Thompson Sampling”, In NIPS, 2249-2257.
[4] Li, Lihong, Chen, Shunbao, Kleban, Jim, and Gupta, Ankur. (2014), “Counterfactual Estimation and Optimization of Click Metrics for Search Engines”, CoRR, abs/1403.1891.
[5] Bottou, L., Peters, J., Quinonero-Candela, J., Charles, D. X., Chickering, D. M., Portugaly, E., Ray, D., Simard, P. and Snelson, E. (2013), “Counterfactual Reasoning and Learning Systems: The Example of Computational Advertising”, Journal of Machine Learning Research, 14, 3207-3260.
[6] Lefortier, D., Swaminathan, A., Gu, X., Joachims, T. and Rijke, M. (2017), “A Large-scale Validation of Counterfactual Learning Methods: A Test-Bed”, In NIPS Workshop on “Inference and Learning of Hypothetical and Counterfactual Interventions in Complex Systems”.
[7] Gilotte, A., Calauzenes, C., Nedelec, T., Abrahan, A. and Dolle, S. (2018), “Offline A/B testing for Recommender Systems”, In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, 198–206.
김진선
NLP Center Knowledge AI Lab Curation팀.
산업공학과에서 제품 신뢰성을 연구했지만
졸업 후엔 IT 회사들에서 다양한 서비스 데이터를 분석하며
의미 있는 인사이트를 찾는 일을 해왔습니다.
현재는 범용적이면서도 우수한 추천 기술을 연구 중입니다.
NLP Center Knowledge AI Lab Curation팀.
산업공학과에서 제품 신뢰성을 연구했지만
졸업 후엔 IT 회사들에서 다양한 서비스 데이터를 분석하며
의미 있는 인사이트를 찾는 일을 해왔습니다.
현재는 범용적이면서도 우수한 추천 기술을 연구 중입니다.
김홍태
NLP Center Knowledge AI Lab Application팀.
Knowledge Reasoning, Causal Inference 등
지식 데이터를 추론, 요약, 전달하는 기술 개발했습니다.
사람과 사람이 지식과 정보를 교류하듯
AI가 사람과 그런 소통이 가능할 수 있도록 고민 중입니다.
NLP Center Knowledge AI Lab Application팀.
Knowledge Reasoning, Causal Inference 등
지식 데이터를 추론, 요약, 전달하는 기술 개발했습니다.
사람과 사람이 지식과 정보를 교류하듯
AI가 사람과 그런 소통이 가능할 수 있도록 고민 중입니다.
구윤성
NLP Center Knowledge AI Lab Curation팀.
수학을 공부하다 실생활에 적용된 수학을 찾아
데이터 과학을 공부하게 된 연구자입니다.
지금은 더 흥미롭고 똑똑한 큐레이션 방법을 연구 중입니다.
NLP Center Knowledge AI Lab Curation팀.
수학을 공부하다 실생활에 적용된 수학을 찾아
데이터 과학을 공부하게 된 연구자입니다.
지금은 더 흥미롭고 똑똑한 큐레이션 방법을 연구 중입니다.
정세희
NLP Center Knowledge AI Lab 실장.
이동통신, 커머스, 제조, 음악, 금융, 게임 등
다양한 비즈니스의 데이터를 분석하고 모델링하여
더욱 인텔리전트한 서비스를 만들어 왔습니다.
지금은 훌륭한 동료들과 즐겁게 연구하며
재미있는 AI를 만들어가고 있습니다.
NLP Center Knowledge AI Lab 실장.
이동통신, 커머스, 제조, 음악, 금융, 게임 등
다양한 비즈니스의 데이터를 분석하고 모델링하여
더욱 인텔리전트한 서비스를 만들어 왔습니다.
지금은 훌륭한 동료들과 즐겁게 연구하며
재미있는 AI를 만들어가고 있습니다.
 Facebook
Facebook  KakaoTalk
KakaoTalk  LinkedIn
LinkedIn  Email
Email  Copy URL
Copy URL