엔씨의 스피치랩(Speech Lab) 음성합성(Speech Synthesis)팀은 텍스트로부터 사람의 목소리를 만들어내는 음성합성 기술을 연구합니다. 팀의 전문 연구진들은 사람의 목소리처럼 자연스럽게 음성을 생성하는 기술 구현에 매진 중입니다.
2019년 6월, 사내에는 김영하 작가의 음성이 울려 퍼졌습니다. 음성 합성 기술로 김영하 작가의 목소리를 구현해 낸 것입니다. 어떻게 김영하 작가의 목소리를 만들었는지 궁금하다면 주목해 주시길 바랍니다. 음성합성 기술의 기본 원리를 소개합니다.
음성합성 기술의 발전, End-to-End 딥러닝 음성합성
최근 2년 간, Speech Lab의 음성합성팀은 딥러닝(Deep Learning)기반의 음성합성 기술을 연구해 오고 있습니다. 현재까지 알려진 딥러닝 기반의 방식들 중에서도 End-to-End 음성합성 기술 개발에 집중하고 있는데요. 이번 시간에는 김영하 작가의 목소리를 AI로 만들어내는 과정과 현재 연구중인 음성합성 기술에 대하여 소개합니다.
음성합성 기술은 텍스트 문자열을 입력하면, 사람의 목소리로 출력해주는 것을 말합니다. 불과 몇 년 전까지만 해도, 널리 활용되던 음성합성 시스템들은 텍스트 전처리, 발음 기호 변환, 운율 예측, 음향 모델링, 신호 합성 등 여러 단계를 거쳐 합성 음성이 나오는 방식이었습니다. 이런 세부 단계들은 음성학, 언어학, 음성 신호 처리, 전산학 통계학 등 여러 분야에서 수십 년 간의 연구 결과물들이 축적된 것이었고, 오랜 기간의 노하우를 쌓지 않고선 쉽게 개발하기 어려운 기술이었습니다.
그러나 최근 몇 년 사이에 AI 분야는 빠른 속도로 발전해 왔습니다. 특히 딥러닝 알고리즘과 그래픽 카드를 통한 병렬처리 기술이 발전하면서 풍부한 데이터를 효율적으로 활용할 수 있게 되었고, 이로 인해 음성합성 기술의 연구 개발 방법이 완전히 다른 추세로 전환되었습니다.
새로운 음성합성 기술은 입력과 출력에 대한 데이터만 존재하면, 입력과 출력 사이의 함수 관계를 스스로 학습해 알아냅니다. 세부 단계에서 필요한 기존의 지식이나 리소스가 없어도 되는 것이죠. 그림과 같이, 어떤 주어진 문장을 발성 기관을 통해 말할 때, 뇌에서 그 중간 과정이 어떻게 처리되는지 정확히 알지 못해도, 어릴 때부터 학습된 모종의 신경망 모델이 이 역할을 수행하는 것처럼 말입니다.

그림과 같이, 음성을 생성하기 위해 사람의 뇌 속에 어떤 구조의 네트워크가 만들어져 있는지 아직까지 정확히 알려진 바는 없습니다. 그럼, 사람의 뇌 속에서 음성 합성이 어떻게 동작하는지 모르는데, 과연 모델링이 가능할까라는 의문이 들 수 있을 텐데요.
인류가 비행기를 개발할 때 새들이 날아가는 원리를 오랜 시간 관찰하고 기본적인 원리를 적용했지만, 오늘 날의 비행기는 새처럼 날개를 움직이지 않습니다. 이처럼 심층 신경망 모델링도 사람의 뇌 안에 존재하는 모델을 똑같은 형태로 구현하지 않더라도 입력과 출력 사이의 비선형적 매핑(Mapping) 관계만 잘 모델링 할 수 있다면 어느 정도 가능하게 됩니다.
다음 그림은 음성합성팀에서 현재 연구 개발 중인 End-to-End 음성합성기의 내부 구조를 보여주고 있습니다.
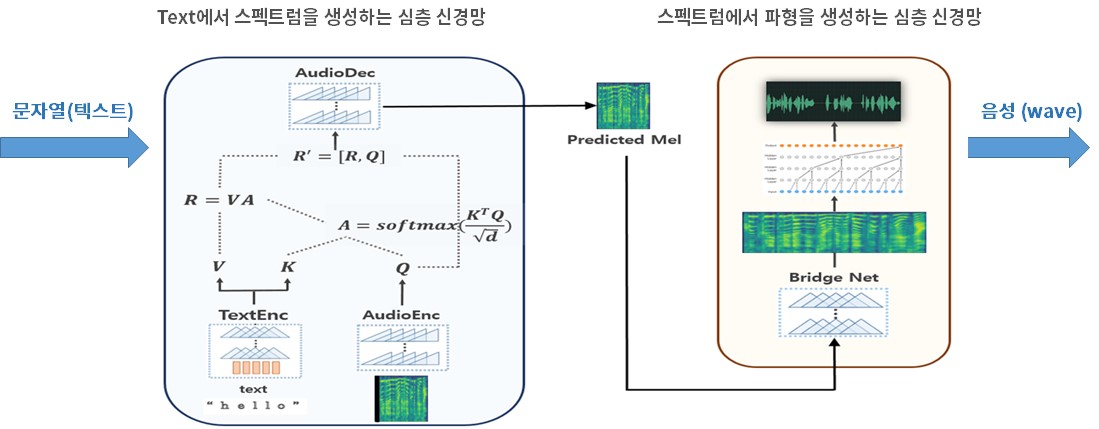
엔씨소프트의 End-to-End 음성합성 방식
이러한 End-to-End 음성합성 기술은 크게 두 단계로 구성되어 있습니다. 텍스트 문자열에서 스펙트럼을 생성하는 부분과 스펙트럼으로부터 음성 파형을 생성해 주는 부분인데요.
이 방식을 이용할 경우, 몇 시간 분량의 (텍스트, 음성) 쌍에 해당하는 데이터만 확보하고 나면 데이터를 활용하여 텍스트 문자열을 입력으로, 음성 신호를 출력으로 하는 심층 신경망 모델에 대한 학습을 자동으로 해내게 됩니다. 학습이 끝나고 나면 새로운 텍스트 문자열 입력에 음성신호를 자동으로 출력해 주는 것이 가능해 지는 것이죠.
실제로 위 모델에는 수 천만 개 이상의 변수 값이 존재합니다. 입출력 데이터들로부터 이렇게 방대한 개수의 변수 값을 찾아내려면 적어도 10시간 분량이 넘는 음성 데이터가 필요한데요. 개개인의 목소리를 표현하기 위해 매번 10시간이 넘는 음성을 녹음하는 건 너무나 큰 비용이 듭니다.
그럼, 어떻게 하면 수십 분 정도의 소규모 음성 데이터만으로 특정 인물의 목소리를 합성해 낼 수 있을까요?
10분 분량만의 김영하 작가 음성 데이터로 어떻게 목소리를 생성해 내나
6월 셋째 주부터 합성된 김영하 작가의 목소리가 사내 곳곳에 송출되고 있습니다. 지금 송출되고 있는 음성은 김영하 작가가 직접 녹음한 10분 분량의 데이터를 이용하여 학습된, End-to-End 딥러닝 음성합성 모델로 제작되었습니다. 10분이라는 데이터의 양은 문장 수로 환산하면 평균 100문장 정도 입니다. 전체 문장을 프린트하면 기껏해야 A4용지 세 네 장 안에 들어갈 정도로 적은 양이죠.
사실 우리 말이 가지고 있는 다양하고 복잡한 발음 법칙을 학습하기에는 턱 없이 부족한 양입니다. 음성합성팀에서는 이처럼 적은 데이터로도 효율적으로 음성을 만들어내기 위해 다양한 기술을 연구하고 있는데요. 이 장에서는 그 기술들의 개요에 대해 알아보겠습니다.
2017년 초에 발표된 End-to-End 음성합성 모델은 기존 상용 음성합성기가 수행하던 텍스트 전처리, 발음 기호 변환, 운율 예측, 신호 합성 등의 여러 세부 단계를, Sequence to Sequence network (Seq2seq), attention mechanism이라는 두가지 기술로 구성된 하나의 커다란 딥러닝 네트워크를 통해 수행합니다.
기존 음성합성기가 이렇게 여러 단계로 복잡하게 구성되었던 이유는 텍스트 데이터가 음성을 효율적으로 나타내는 심볼로, 매우 압축되어 있는 데이터이기 때문입니다. 따라서 음성합성기의 각 단계는 압축을 하나하나 풀어나가며 손실되었던 정보를 채워나가는 과정이라고 생각할 수 있습니다.
음성합성의 각 단계 중에서도 음성의 자연스러움에 가장 큰 영향을 미치는 부분은 운율 예측 단계입니다. 이 단계에서는, 음성의 강세, 텍스트의 각 부분에 맞는 음성의 길이 등의 정보를 예측합니다. 이 과정에서 예측된 데이터와 실제 데이터 사이의 차이로 인해 합성음이 로봇 또는 외국인이 말하는 것처럼 들리게 되는데요. End-to-End 음성 합성 모델에서는 attention mechanism이 운율을 예측하는 역할을 수행합니다.
Attention mechanism은 수많은 <텍스트, 음성> 쌍으로부터 두 데이터 간의 시간적 정렬(Alignment)을 추정하는 방법을 학습합니다. 아래 그림은 잘 합성된 음성합성기의 attention mechanism이 각각의 텍스트 심볼에 대해 음성 구간을 어떻게 짝지어 주었는지를 나타내고 있습니다.
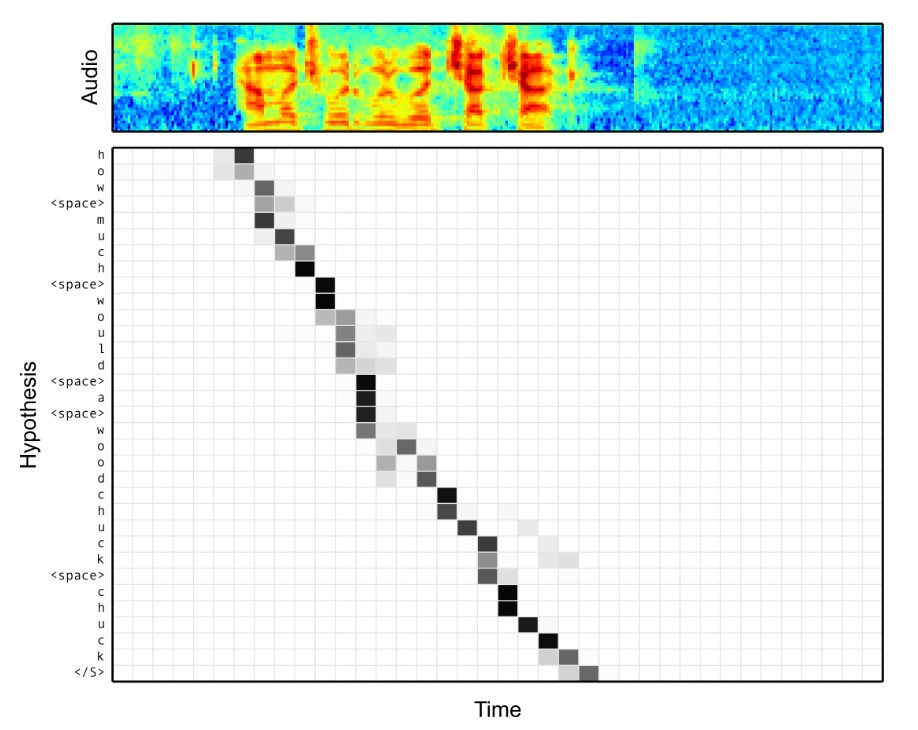
<텍스트, 음성> 데이터가 많을수록 모델이 다양한 케이스를 학습할 수 있고, 당연히 더욱 자연스러운 음성을 합성할 수 있습니다. 제대로 된 정렬을 형성하기 위해서는 앞에서 설명했듯이 기본적으로 10시간이 넘는 음성 데이터가 필요합니다.
음성합성팀에서는 이 데이터를 줄이기 위한 여러 가지 연구를 수행하고 있는데요, 여러가지 연구 중 하나는 적응 훈련(Adaptation Training)입니다. 적응 훈련이란, 적은 양의 데이터만을 가지는 태스크를 효과적으로 학습하기 위해 많은 양의 데이터로 학습된 기존 모델을 활용하는 방법입니다. 이를 음성합성에 적용하면 먼저 많은 양의 데이터를 가지고 있는 임의의 화자에 대해 기반이 되는 모델을 먼저 학습한 후에 (Pre-training 단계), 10분 분량만을 가지고 있는 김영하 작가의 음성을 이용해 새로운 학습을 추가로 진행하게 됩니다 (Adaptation Training 단계).
적응 훈련 방식을 이용하지 않고 적은 데이터로 음성합성을 시도하면 딥러닝 모델은 <텍스트, 음성> 쌍이 가지는 복잡한 규칙을 제대로 학습하지 못합니다. 단지 특정 텍스트가 들어왔을 때 특정 음성이 나오면 된다는 사실만을 학습하기 때문에 attention 정렬은 제대로 형성되지 않고 음성도 제대로 합성해내지 못하게 됩니다. 이처럼 적은 데이터에 과하게 의존적으로 학습하게 되는 현상을 오버피팅(Overfitting)이라고 합니다.
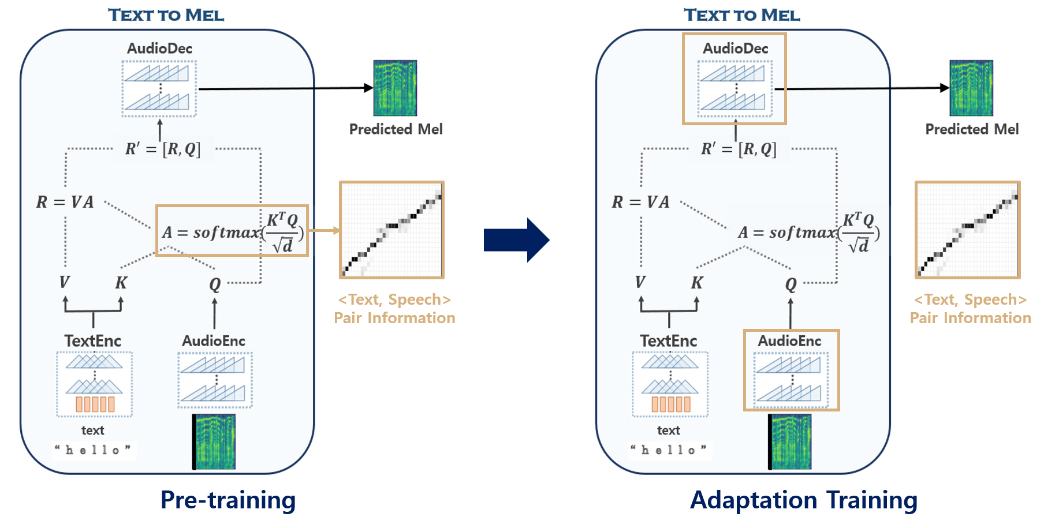
적응 훈련 방식은 학습 단계를 그림과 같이 두 단계로 나누어 오버피팅 현상을 줄여줍니다. 모델은 pre-training 단계에서 A matrix로 표현된 <텍스트, 음성> 쌍 사이의 정렬 규칙을 먼저 학습합니다. 그 다음 미리 학습한 정렬 규칙을 활용하여 Audio Encoder와 Audio Decoder를 김영하 작가의 음성에 맞게 새로 조정하게 됩니다. 이렇게 두 단계로 나누어 학습을 진행하면 적은 양의 데이터를 더욱 효율적으로 사용할 수 있습니다.
다만 이렇게 pre-training을 충분히 진행하고 새로운 데이터를 적용해도 적응 훈련 과정에서 오버 피팅을 완벽하게 방지할 수는 없습니다. 모델이 새로운 음성을 합성해내는 방법을 완벽하게 학습하기 전에 <텍스트, 음성> 쌍 사이의 규칙을 잊어버리고 오버피팅 현상에 빠져버리는 일이 허다합니다. 음성합성팀에서는 오버피팅을 최대한 방지하면서 효율적으로 적은 데이터를 활용하기 위한 기술들을 개발하고 있습니다.
이준모
AI Center Speech Lab 음성합성팀 팀원. 전자 공학을 공부하며 신호 처리에 흥미를 느껴 음성 합성에 대한 연구를 해왔습니다. NCSOFT에서도 더 다양하고 자연스러운 음성을 합성하기 위해 노력하고 있습니다.
AI Center Speech Lab 음성합성팀 팀원. 전자 공학을 공부하며 신호 처리에 흥미를 느껴 음성 합성에 대한 연구를 해왔습니다. NCSOFT에서도 더 다양하고 자연스러운 음성을 합성하기 위해 노력하고 있습니다.
이경훈
AI Center Speech Lab 음성합성팀 팀원. 학교에서 PDE(Partial Differential Equation)와 데이터 마이닝, 인공 지능을 공부하고 NCSOFT에서 TTS와 뉴럴 보코더를 연구하고 있습니다. 음성 합성 연구를 통하여 사람들에게 새로운 경험과 즐거움을 주기 위하여 밤낮없이 연구에 매진하고 있습니다.
AI Center Speech Lab 음성합성팀 팀원. 학교에서 PDE(Partial Differential Equation)와 데이터 마이닝, 인공 지능을 공부하고 NCSOFT에서 TTS와 뉴럴 보코더를 연구하고 있습니다. 음성 합성 연구를 통하여 사람들에게 새로운 경험과 즐거움을 주기 위하여 밤낮없이 연구에 매진하고 있습니다.
김영익
AI Center Speech Lab 음성합성팀 팀장. 화자의 감정과 발화 스타일을 자연스럽게 표현하는 고품질 음성합성 기술을 만들고, NCSOFT가 만드는 다양한 서비스에 적용해 보고 싶은 꿈을 가지고 있답니다.
AI Center Speech Lab 음성합성팀 팀장. 화자의 감정과 발화 스타일을 자연스럽게 표현하는 고품질 음성합성 기술을 만들고, NCSOFT가 만드는 다양한 서비스에 적용해 보고 싶은 꿈을 가지고 있답니다.
조훈영
최근의 AI 기술은 매우 흥미롭고 근본적인 변화를 예고하고 있는 것 같습니다.
음성이라는 매력적이고도 편리한 수단을 통해 사람과 사물이 다양한 형태로 교감하는 미래를 만들어 나가고자 합니다.
최근의 AI 기술은 매우 흥미롭고 근본적인 변화를 예고하고 있는 것 같습니다.
음성이라는 매력적이고도 편리한 수단을 통해 사람과 사물이 다양한 형태로 교감하는 미래를 만들어 나가고자 합니다.
 Facebook
Facebook  KakaoTalk
KakaoTalk  LinkedIn
LinkedIn  Email
Email  Copy URL
Copy URL 






