엔씨의 스피치랩(Speech Lab) 음성합성(Speech Synthesis)팀은 텍스트로부터 사람의 목소리를 만들어내는 음성합성 기술을 연구합니다. 팀의 전문 연구진들은 사람의 목소리처럼 자연스럽게 음성을 생성하는 기술 구현에 매진 중입니다.
2019년 6월, 사내에는 김영하 작가의 음성이 울려 퍼졌습니다. 음성 합성 기술로 김영하 작가의 목소리를 구현해 낸 것입니다. 1편에서는 End-to-End 딥러닝 음성합성 기술의 기본 원리를 알아봤습니다. 이번엔 어떻게 실제 목소리와 비슷하게 구현할 수 있었는지, 품질을 높이는 방법을 이야기합니다.
앞서 소개된 구조도를 자세히 보면 Text-to-Mel 네트워크가 음성이 아닌 멜 스펙트럼(Mel-Spectrogram)이라는 출력을 생성하는 것을 확인할 수 있습니다. 멜 스펙트럼은 음성의 주파수 특성을 분석한 데이터입니다. 멜 스펙트럼에는 음성 데이터의 주요한 정보들이 아주 효율적으로 정리되어 담겨 있습니다. 하지만 멜 스펙트럼을 곧바로 음성으로 변환할 수 없기 때문에, 보코더(Vocoder)를 이용하여 멜 스펙트럼을 우리가 익히 아는 음성 데이터로 변환하기 위한 추가적인 작업이 필요합니다. 최근에는 인공신경망을 이용하여 멜 스펙트럼과 같은 음성 특징들로부터 음성을 만들어내는 뉴럴 보코더(Neural Vocoder)에 대한 연구가 활발히 진행되고 있습니다.
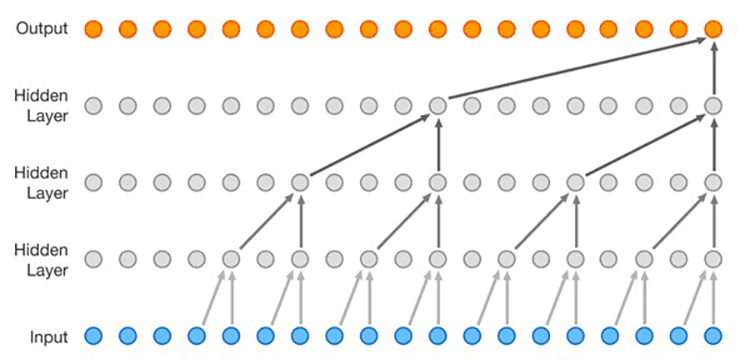
Wavenet은 2016년에 구글에서 발표한 뉴럴 보코더 모델로 음성 샘플들 간의 순차적 특징을 이용하는 자기회귀(Autoregressive) 모델입니다. Wavenet은 이전 샘플들을 이용해 다음 샘플을 예측하는 방법으로 고품질의 음성을 합성하는데 성공했습니다. 하지만, 이전 샘플들로부터 다음 샘플을 하나씩 생성하기 때문에 생성 속도가 매우 느린 단점을 가지고 있습니다.
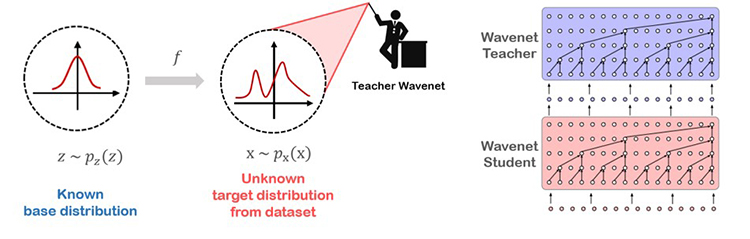
Parallel Wavenet은 2017년 구글에서 개발한 모델로 Wavenet의 느린 샘플 생성 속도를 보완하기 위해 고안되었습니다. Parallel Wavenet은 IAF(Inverse Autoregressive Flow) 모델을 이용해 음성을 합성합니다. IAF 모델은 학습 시 타겟이 되는 음성 데이터 셋의 분포를 알 수 없기 때문에 잘 학습된 Wavenet을 사용하여 타겟 데이터 셋의 분포 정보를 추출하고, 이를 IAF 모델의 결과값과 비교하는 방식으로 학습을 합니다.
Parallel Wavenet에서 사용하는 IAF 모델은 student network, Wavenet 모델은 teacher network라고 합니다. Parallel Wavenet은 Wavenet보다 음성 합성 속도가 빠르다는 장점이 있습니다. 하지만, Wavenet보다는 합성 음성의 품질이 떨어지고 잘 학습된 teacher network를 먼저 학습시켜야 한다는 단점을 가지고 있습니다.
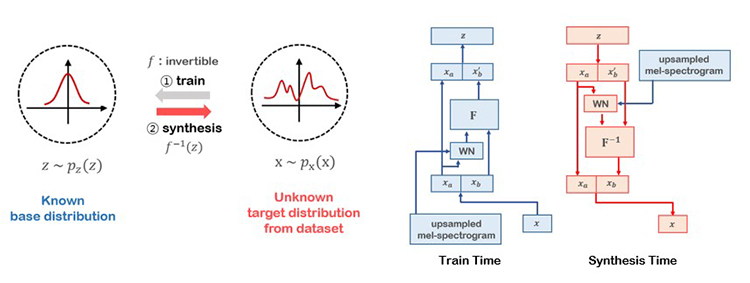
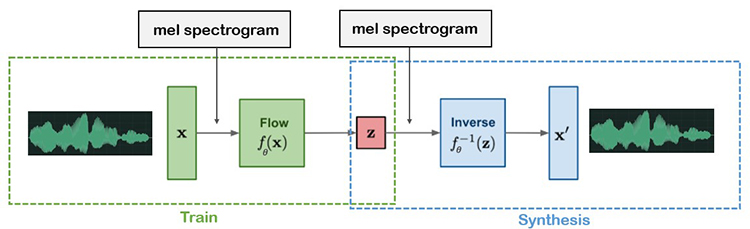
비교적 최근에 발표된 WaveGlow는 Normalizing Flow 기반의 뉴럴 보코더입니다. WaveGlow는 가역성(invertible)을 지닌 변환 함수(f)를 이용하여 음성 데이터셋(x)으로부터 가우시안 분포(z)와 같이 우리가 이미 알고 있는 단순한 분포가 나오도록 학습합니다. 학습이 끝난 후 변환 함수(f)의 역함수를 이용하여 가우시안 분포의 샘플로부터 음성을 합성합니다.
WaveGlow는 Parallel Wavenet과 달리 사전에 학습된 teacher network가 필요가 없으며 빠르게 음성을 합성할 수 있다는 장점이 있습니다. 엔씨에서는 이러한 WaveGlow의 장점 때문에 Flow 기반의 뉴럴 보코더를 사용하고 있습니다. 하지만, Flow 기반의 뉴럴 보코더에도 단점이 있습니다. 분포를 기반으로 하는 손실(Loss) 함수를 이용하기 때문에 합성된 음성의 품질이 다소 떨어지는 단점이 있습니다. 또한 TTS 시스템과 결합될 경우, 텍스트로부터 예측한 멜 스펙트럼의 품질에 따라 합성된 음성의 품질이 좌우되는 문제가 있습니다.
음성합성팀에서는 WaveGlow의 단점을 보완하고 합성음의 품질을 높이기 위한 연구를 진행하고 있습니다. 연구를 통하여 기존의 WaveGlow모델이 사용했던 분포 기반의 손실 함수에 합성된 음성 샘플과 실제 음성 샘플을 이용한 샘플 단위의 손실 함수를 추가함으로써, 보다 향상된 품질의 음성을 생성하였고 초해상화(Super Resolution)를 위한 모듈을 추가하여 예측된 멜 스펙트럼에 대한 보코더의 성능을 높일 수 있었습니다. 현재 음성합성팀은 WaveGlow의 성능을 높이면서 안정적으로 학습을 할 수 있는 방법을 연구 중이며, TTS 시스템으로부터 생성된 멜 스펙트럼에 대해서도 언제나 고품질의 음성을 합성할 수 있는 강인한(Robust) 모델을 연구 중입니다.
음성합성팀은 화자의 감정과 발화 스타일을 딥러닝 기술로 어떻게 효율적으로 표현할 수 있을까 고민합니다. 음성 데이터에 포함된 발화 스타일을 단순히 모방하는 수준을 넘어 새로운 발화 스타일을 만들고 전달하는 방법을 다양하게 시도 중인데요.
한 예로, 지난 4월 NCDP에서 “스타일 전달 기술을 이용한 새로운 화자의 감정 음성 합성(TTS) 시스템 소개”라는 주제의 발표가 있었습니다. 특정 화자의 감정 표현 모델을 새로운 화자에게 이식하는 방법을 소개했는데요. 이런 감정 및 스타일 전달 음성합성 기술은 향후 AI 캐릭터의 목소리에 적용시켜 엔씨만의 새로운 가치를 부여할 것으로 기대합니다.
또한 음성합성팀은 올해 초 “스포츠 중계용 TTS 기술 개발”이라는 목표를 하나 수립했습니다. 단조로운 낭독체 위주의 합성 기술에서 벗어나는 TTS 응용 서비스를 위해 보다 자연스럽고 다양한 스타일의 음성합성 기술과 운율 제어 기술을 연구 중인데요.
스포츠 중계를 시청할 때, 우리는 수많은 데이터와 상황을 전달하는 역동적인 아나운서의 목소리를 들을 수 있습니다. 합성 기술을 연구하는 입장에서 이런 목소리를 만든다는 것은 하나의 종합 예술이고 궁극의 합성 기술이라 생각합니다. 앞으로 이런 스포츠 중계용 합성기술은 엔씨에서 서비스 중인 야구 게임이나 e-스포츠에 적용할 수 있을 것입니다.
 Facebook
Facebook  KakaoTalk
KakaoTalk  LinkedIn
LinkedIn  Email
Email  Copy URL
Copy URL