 Facebook
Facebook  KakaoTalk
KakaoTalk  LinkedIn
LinkedIn  Email
Email  Copy URL
Copy URL 대한민국 게임회사 최초로 AI Lab을 구축하고, 게임 AI에 대한 R&D 연구를 선도한 엔씨소프트.
‘게임과 AI’ 2편에서는 엔씨소프트가 지금껏 연구해 온 <블레이드 & 소울> 속 게임 AI의 구조 및 시스템에 대해 소개하겠습니다.
대한민국 게임회사 최초로 AI Lab을 구축하고, 게임 AI에 대한 R&D 연구를 선도한 엔씨소프트.
‘게임과 AI’ 2편에서는 엔씨소프트가 지금껏 연구해 온 <블레이드 & 소울> 속 게임 AI의 구조 및 시스템에 대해 소개하겠습니다.

최근 게임 AI에 대한 새롭고 재미있는 소식들이 들려오고 있습니다. AI를 좋아하는 사람들을 열광시키기에 충분한 뉴스거리죠. ^^
딥러닝을 위한 <스타크래프트 Ⅱ> API
OpenAI의 Bot AI와 인간의 대결 #도타2
딥마인드(DeepMind)와 블리자드가 딥러닝(Deep Learning)을 이용해서 <스타크래프트 Ⅱ> AI를 개발할 수 있는 API를 발표했습니다. 이전에도 <스타크래프트 : Brood War>를 통해 AI를 연구했지만, 이렇게 쉽게 R&D를 시작할 수 있는 환경을 구축한 적은 처음입니다.
또한, 미국의 비영리재단인 OpenAI가 개발한 <도타 2> Bot AI가 최고 레벨 프로게이머와 대결해서 승리를 거두기도 했습니다. 자세한 이야기는 OpenAI 블로그를 통해 확인해보세요. (https://blog.openai.com/more-on-dota-2)
이처럼 심층강화학습에 대한 연구는 점진적으로 아타리(Atari)와 바둑이라는 경계를 벗어나, 좀 더 현실세계에 가까운 게임에 진출하려 하고 있습니다. 과연 정말로 딥러닝(Deep Learning) 기술을 통해 복잡한 게임의 AI를 만들 수 있을까요?
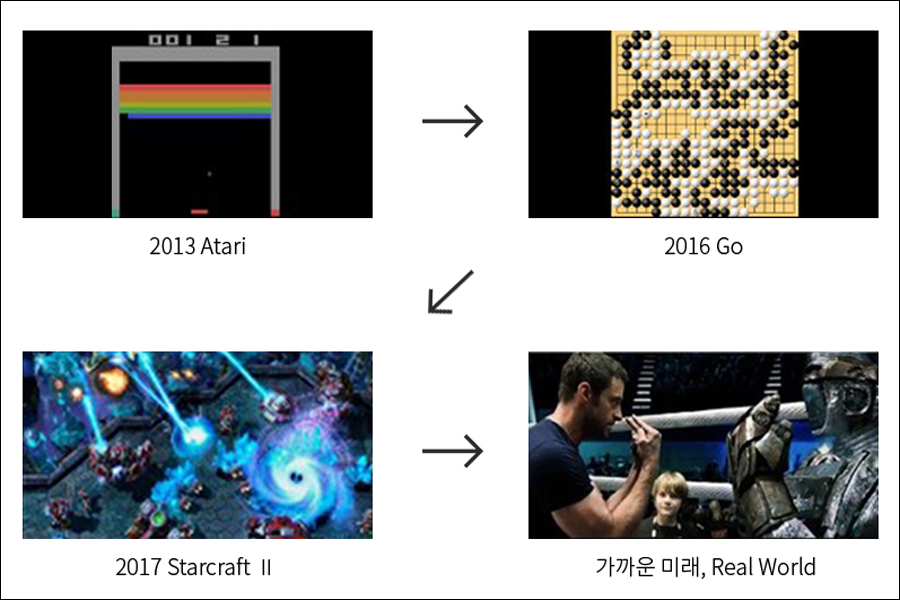
딥러닝(Deep Learning)과 게임 AI의 발전 과정
엔씨소프트도 이러한 궁금증에 답해보려고 합니다. 이에 저희는 엔씨소프트의 대표 IP 중에 하나인 <블레이드 & 소울>을 플레이할 수 있는 AI를 만들고자 합니다.
실시간으로 3차원 상에서 끝없이 움직이고, 수십 개의 스킬을 시기 적절하게 사용할 수 있는 AI를 만들 수 있는 기술이라면 어떤 문제가 주어져도 해결할 수 있게 될 것 같거든요.
이번 연재에서는 저희가 연구하고 있는 <블레이드 & 소울> AI(이하 B&S AI)의 구조와 학습 절차 등을 소개하겠습니다. 또 강화학습으로 AI를 만드는 데 있어서의 현실적인 어려운 점과 고민들에 대한 이야기도 들려드리겠습니다.
<블레이드 & 소울> 내 무한의 탑이라는 AI 기반 콘텐츠를 위해, 2016년에 B&S AI 1.0 버전을 만들어 현재까지 서비스하고 있습니다.
무한의 탑은 사람 대신 AI를 상대로 하여 대결을 펼치는 콘텐츠입니다. 이를 위해 사람과 똑같은 스킬셋을 사용해 전투를 할 수 있는 PvP AI를 만들었습니다.
즉, B&S AI는 사람과 1:1 PvP를 할 수 있는 AI입니다. 현재 상황에서 직업별로 사용 가능한 스킬 중, 가장 적절한 스킬을 상황에 맞게 선택하여 사용할 수 있습니다.
B&S AI 1.0에 대한 자료에 대한 자세한 내용은 다음 글을 참고해 주세요. (http://igc.inven.co.kr/detail.php?code=Y29kZTI5, https://about.ncsoft.com/?p=13249)
무한의 탑 플레이 소개 동영상
현재도 이 서비스를 하고 있지만, 알파고가 사람을 이기는 것을 보며 저희에게도 근사한 꿈이 생겼습니다. 1:1 PvP 콘텐츠인 비무장에서 사람을 완벽하게 이겨보고 싶은 꿈입니다. ^^
B&S AI 1.0은 딥러닝(Deep Learning)이 적용되지 않은 버전입니다. 1.0 버전에 적용된 신경망(Neural Network)은 은닉층(hidden layer)이 1개이며, 네트워크의 크기도 요즘 기준으로는 꽤 작은 편입니다.
이 버전으로도 보통 실력의 사람을 이기는 수준까지는 만들 수 있었으나, 내부 테스트 결과 최고수들을 상대할 수 있는 AI를 만들기에는 분명한 한계가 존재한다고 판단했습니다.
또한, 던전 형태인 무한의 탑 콘텐츠를 위해 만들어진 AI이다보니, 탑 안에서 높은 층에 도달할수록 AI의 스탯이 증가하도록 되어있습니다.
이는 비무장(사람 간의 1:1 격투 콘텐츠로, 진입 후 장비와 스탯, 레벨은 무시되고 동등한 조건에서 격투를 벌임)과 같이 공평한 환경에서 벌어지는 전투와는 여러모로 차이를 보였습니다. 저희가 만든 AI의 성능을 철저하고 객관적으로 검증해보려면 비무장 환경에서 테스트가 이루어져야 한다고 생각했습니다.
이에 딥러닝(Deep Learning) 기술을 활용해 무한의 탑에서 벗어나, 비무장 환경에서 최강의 사람들과 잘 싸울 수 있는 B&S AI 2.0을 만들고자 합니다.
B&S AI 1.0와는 다르게 무한의 탑에서 플레이한 사람들의 로그도 사용할 수 있는 환경이 됐고, 앞에서 살펴본 것과 같이 아타리(Atari) 게임 등에서도 유의미한 결과들이 나와서 참고할만한 자료가 풍부해졌기 때문입니다.
강화학습 기반의 AI를 개발하는 과정은 매우 복잡하고 많은 일을 필요로 하지만, 크게 다음의 과정으로 요약할 수 있을 것 같습니다. 사실 저희가 일하는 순서를 나열한 것입니다. ^^
세부 과정은 개발하는 알고리즘과 AI의 종류에 따라 천차만별이겠지만 전체적으로 아래 순서를 크게 벗어나지는 않을 것 같습니다.

강화학습 AI 개발 과정
B&S AI에 대한 개발 과정도 위 순서도에 따라 AI 구조 설계부터 설명하겠습니다.

AI를 설계한다는 것은, AI들이 어떤 입력을 받아서 특정 판단을 내리고 어떤 방식으로 그것을 이루게 할지를 결정하는 일입니다. 아래 표 안의 내용을 구체적으로 결정하는 일이라 할 수 있죠.
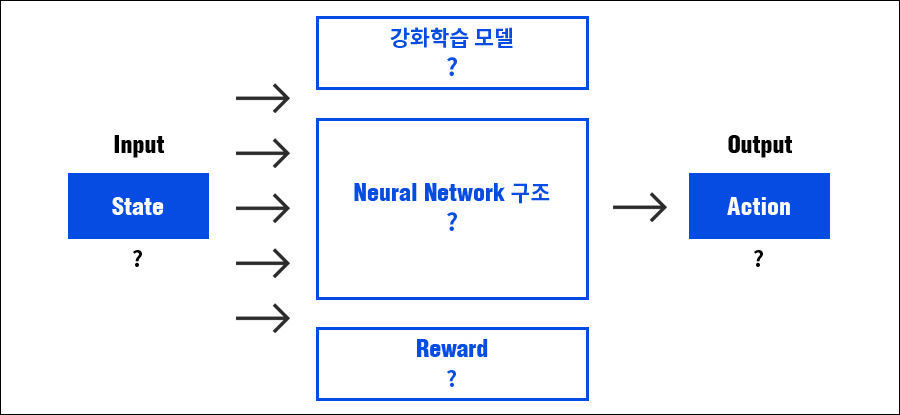
AI 구조 설계 요소
AI가 하는 일은 현재 상황(State)에서 최적의 행동(Action)을 선택하는 일입니다. 그러므로, 가장 먼저 AI가 관측할 상태(State)에는 어떤한 정보가 포함될지 정해야 하고 그 정보를 바탕으로 AI는 어떤 행동을 선택할지 결정합니다.
<블레이드 & 소울>의 경우, 내부 상황(State)을 모두 알 수 있으므로 아타리(Atari)와 같이 Raw Visual Input을 사용할 필요가 없습니다. 이런 상황 정보에는 AI의 정확한 위치와 여러 상태 및 효과들(기절, 다운, 버프, 디버프 등)과 AI가 사용할 수 있는 스킬 정보(쿨타임, 내력 등)가 포함됩니다. 또한 이렇게 상황 정보가 Input으로 들어오면 B&S AI는 대략 50개 정도의 스킬셋 안에서 최적의 선택지를 고릅니다.
다음으로 보상(Reward)을 설계해야 하는데, AI 설계에 있어서 중요한 일 중 하나입니다. 물론 역강화학습(Inverse Reinforcement Learning)과 같이 보상(Reward)를 추정하는 방법도 있지만 기본적으로 사람의 지식(Domain Knowledge)을 많이 적용하여 설계하게 됩니다. B&S AI는 게임의 승패와 함께, 나와 상대방의 체력 상태를 보상(Reward)으로 같이 사용합니다.

복잡한 과정을 거쳐 만들어지는 무한의 탑 속 AI
이제 가장 복잡한 일이 남게 되는데, 학습 모델로 쓰일 신경망(Neural Network)의 구조를 결정해야 합니다.
<블레이드 & 소울>의 전투는 1초 내에 2~3개의 스킬을 사용하는 실시간 전투이기 때문에, 몬테카를로 탐색기법(Monte Carlo Tree Search, MCTS)과 같은 탐색 기반 알고리즘을 사용할 수 없습니다.
알파고의 눈부신 성과 중에 많은 부분을 저희도 참고하고 있지만, 근본적으로 실시간 서비스되어야 한다는 부분에서 큰 차이가 있습니다. 최신 게임들은 정말 무거운 소프트웨어이고 AI에게 할당되는 시간은 극히 적습니다. 수많은 사람들이 동시에 플레이하는 MMORPG에서 동작하는 AI를 실제 서비스로 구현하려면 10msec(0.01초) 안에 행동이 결정되어야 합니다.
그래서 알파고가 사용했었던 MCTS와 같은 강력한 탐색 기반 기술들은 사용할 수 없고, 기본적으로 End-to-End 신경망 구조로 되어 있습니다. 또한 강화학습 모델은 Policy Gradient 모델을 기반으로 하였습니다.
여기서 저희를 더욱 어렵게 만드는 점은 <블레이드 & 소울> 내 캐릭터 종류가 10개(검사, 역사, 권사, 기공사 등)나 된다는 점입니다. 정확히 말하면 10개 직업을 상대할 수 있는 10개의 직업 AI가 필요한 셈입니다.
가장 손쉬운 방법은100가지 경우에 대해서 각각 신경망(Neural Network)을 만들고 학습하는 것이지만, 유지보수 비용을 생각한다면 바람직한 방법이 아닙니다. 그래서 저희는 캐릭터별로 신경망(Neural Network)을 따로 만들지 않고 하나의 신경망(Neural Network)을 여러 캐릭터가 공유하도록 해서 재활용성을 높이는 방향으로 설계하였습니다.
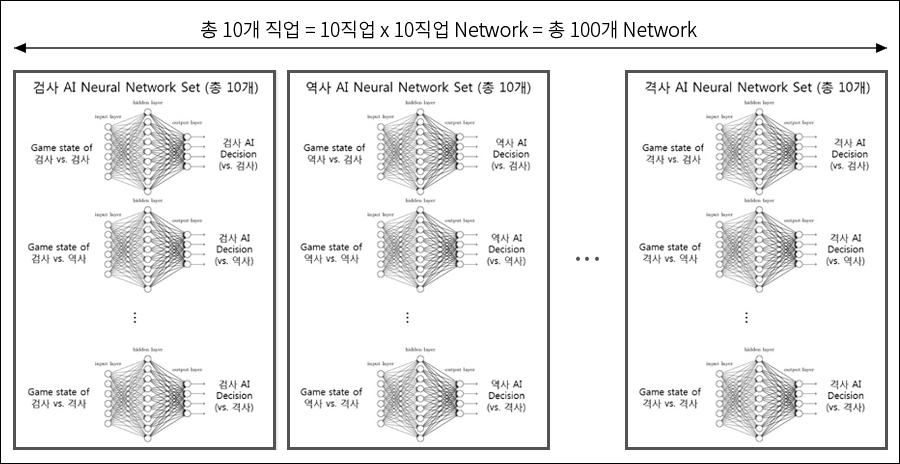
B&S AI 1.0 신경망(Neural Network)
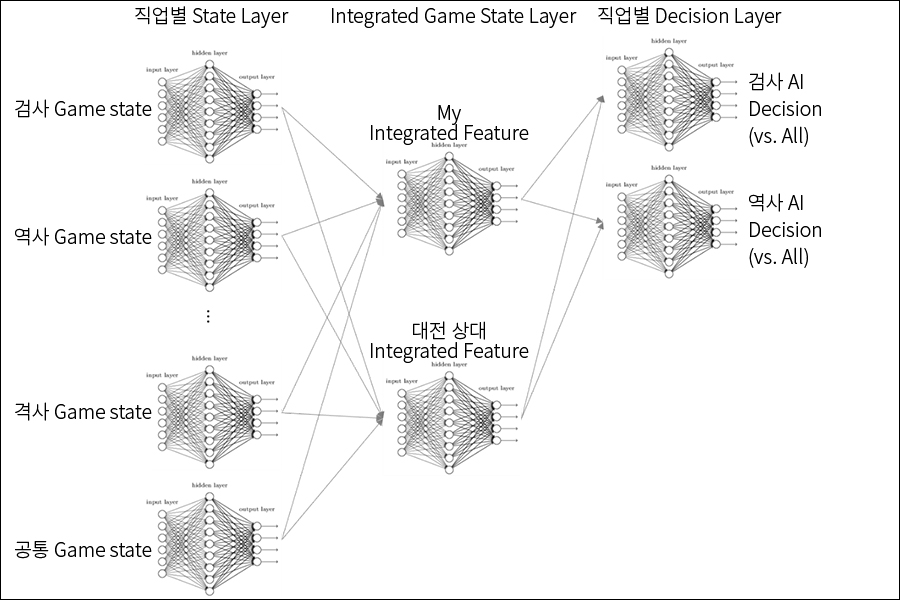
B&S AI 2.0 신경망(Neural Network)
B&S 2.0 AI 구조는 기본적으로 Fully Connected 레이어로 구성되며, 캐릭터 상태를 일반화하여 표현할 수 있는 직업별 State 레이어와 Integrated Game State 레이어, 직업별 Decision 레이어로 구성됩니다.
설계된 AI 구조를 다시 요약하면 아래와 같습니다.
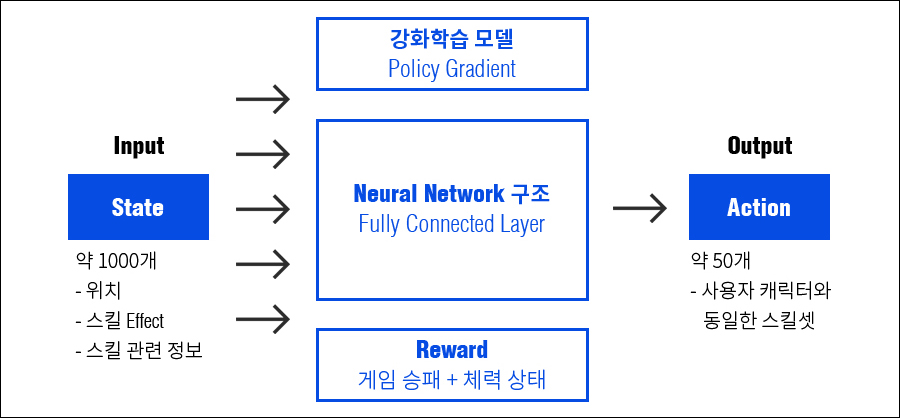
B&S AI 2.0 구조

AI 구조에 대한 설계가 끝났다면 실제로 AI들의 대전 시뮬레이션이 이루어지고, 그 결과들이 저장되어서 저장된 결과를 바탕으로 신경망을 학습시키고 학습된 결과가 자동으로 배포되는 꽤 복잡한 학습 시스템 프레임워크(Framework) 개발이 필요합니다.
그 첫 과정은 시뮬레이터(Simulator)를 만드는 일입니다. 여기서 시뮬레이터(Simulator)라는 함은 AI가 어떤 행동을 하기로 결정하면 그 행동에 의해서 세계(World)의 상황(State)이 어떻게 변하는지를 계산해주는 모듈을 의미합니다.
보통 현실 세계(Real World)의 문제를 푸는 경우에는, 직접 해볼 수가 없으니 시뮬레이터(Simulator)를 만들어야 합니다. 물론 게임 AI는 게임 자체가 곧 시뮬레이터(Simulator)이기 때문에 이 과정이 좀 더 쉽지요.
B&S AI의 경우도 실제 게임 서버를 가져다 시뮬레이션을 수행하고, 별도의 AI 서버 그룹을 구성하여 실시간 판단(Decision) 및 학습을 수행했습니다. 사실, 처음부터 실제 서비스를 가정하고 시작되었던 프로젝트여서, 별도 시뮬레이터(Simulator)를 제작하지 않고 실제 게임 서버에 붙일 수 밖에 없었습니다.
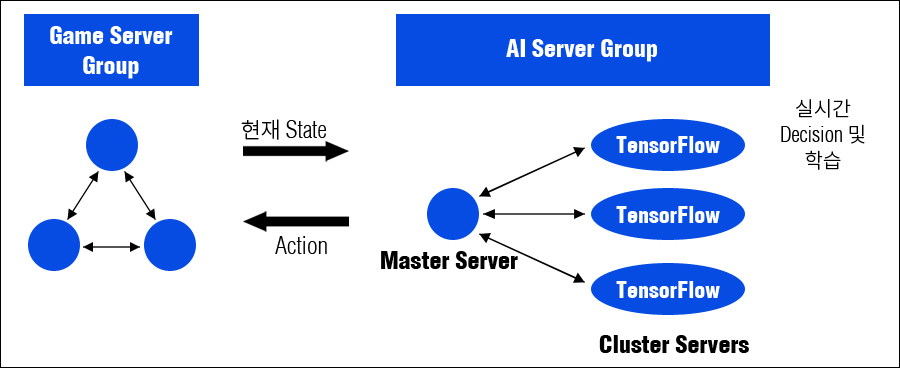
B&S AI 2.0 학습 시스템
강화학습 과정은 본질적으로 무수히 많은 시행착오(Trial and Error)를 거쳐야 하기 때문에 시뮬레이션 속도가 매우 중요합니다. 그러나 실제 서버에 붙여야 했기 때문에 서버를 빨리 돌려 속도를 빠르게 할 수가 없었습니다. 그렇다면 이를 해결하기 위해서는, 동시에 많이 실행하는 방법 밖에는 없습니다.
그래서 게임 서버 내에 아주 많은 수의 인스턴스 존(Instance Zone)을 생성하고, 그 존(Zone)마다 AI들을 별도로 생성해서 동시에 학습할 수 있도록 만들었습니다.
또한 많은 수의 AI들의 판단(Decision)을 위해서는 그만큼 많은 수의 AI 서버가 필요합니다. 이에 텐서플로(TensorFlow)가 탑재된 다수의 AI Decision 클러스터 서버(Cluster Server)와 이들을 관리하는 마스터 서버(Master Server)로 구성된 서버 그룹을 개발했습니다.
사실 위 그림은 정말 간단하지만 이런 시스템을 만드는 일은 매우 고통스러운 일입니다. <블레이드 & 소울>과 같은 규모의 게임은 하나의 서버에서 시뮬레이션과 학습 등을 동시에 할 수 없으며 대규모 분산 환경이 필수적입니다.
분산 환경에서 시스템을 개발해보신 분들은 아시겠지만, 구현 기간도 매우 길고 복잡한 환경 때문에 발생하는 수많은 예외 케이스와 디버깅(Debugging)의 어려움 때문에 많은 좌절을 겪게 될 것입니다.
이에 앞에서 소개했던 <스타크래프트 Ⅱ>의 강화학습 환경이나, 최근 OpenAI에서 진행하고 있는 OpenAI Gym, OpenAI Baseline과 같이 강화학습을 쉽게 시작할 수 있는 시스템을 배포해주는 일은 정말 고마운 일입니다.
강화학습을 시작하면서 제대로 동작하는 시스템을 만드는 데만 몇 달을 소비하게 될 텐데, 그 과정을 생략할 수 있으니까요. (참고 자료: https://gym.openai.com, https://blog.openai.com/baselines-acktr-a2c)
OpenAI Gym
저희도 B&S AI뿐 아니라 여러 종류의 AI들을 만들고 있는데요. 그 과정에서 AI 서버 그룹을 재활용할 수 있는 저희만의 보편적인 프레임워크(Framework)를 만드는 과정을 병행하고 있습니다. 또한 머신러닝(Machine Learning) 전공자뿐만 아니라 AI에 관심이 많은 숙련된 프로그래머들도 매우 높은 비중으로 채용하고자 노력하고 있습니다.
이제 마지막 검증 단계입니다. 기본적인 프레임워크(Framework)가 갖춰졌다면 AI들을 검증할 수 있는 시스템을 만들어야 합니다. 또한, PvP 게임이므로 사람들과 싸울 수 있는 환경도 구축해야 합니다.
여기서 반드시 고려해야 하는 문제는 반응 속도입니다. B&S AI는 게임 클라이언트 없이 기본적으로 서버 상에서만 동작하도록 만들어졌기 때문에 반응 속도를 제한해줘야 했습니다. 물론 단순히 최소값만 정해주는 형태는 학습 환경을 다양하게 해주지 못하므로, 사람의 인지 모델에 기반하여 확률 모델에 의해 작동하도록 설계했습니다.
또한 공격, 방어, 움직임 등 AI 동작 종류에 따라 세부적으로 나누고, 각각 다른 확률이 적용될 수 있도록 했습니다. 그런데 이 모델링이 상당히 어려울뿐더러 사람마다 체감이 다르고 불규칙한 네트워크 지연(Network Delay)에서 오는 변동 등으로 인해, 아무리 튜닝(Tuning)해도 체감상 사람과 완전히 같게 만들기가 어려웠습니다. 최근에는 이런 문제를 없애기 위해, 서버 간 통신이 아니라 클라이언트를 경유해서 AI가 동작할 수 있는 R&D 전용 시스템을 구현하고 있습니다.
다음 시간에는 강화학습 단계의 알고리즘을 주제로 다룰 예정으로, 강화학습을 시행하면서 겪었던 어려움과 현재 실험 결과 등에 대해 소개하겠습니다.

이경종
RELATED


