엔씨소프트에서 론칭하는 게임이 점점 증가함에 따라 고객에게 다양한 웹 서비스를 제공하기 위해 서버가 많이 필요하게 되었습니다. 하지만 필요한 서버가 많아지면 그만큼 구매해야 하는 서버와 설치해야 하는 소프트웨어가 늘어나는 등 서버 환경을 일일이 설정해야 하는 어려움이 발생합니다. 이는 장비 구매부터 실제 서비스에 적용하기까지 많은 시간이 소요됨을 의미하기도 합니다.
이러한 환경을 개선하고자 플랫폼센터는 I&O 조직*과 협업해 2016년 클라우드 환경인 쿠버네티스(Kubernetes)를 구축하고, 플랫폼센터의 웹 서비스들을 쿠버네티스로 이전하기 시작했습니다. 쿠버네티스의 안정화로 몇 해 전부터는 서버리스(Serverless) 환경에 대한 여러 가지 테스트를 진행하고 있는데요.
본 포스팅에서는 서버리스에 대한 간단한 설명과 더불어 플랫폼센터가 서버리스 도입을 위해 어떤 다양한 기술에 관심을 갖고 살펴보고 있는지 소개하고자 합니다.
*I&O(Infrastructure & Operation) : 게임을 서비스하는 시스템을 운영하는 조직
서버리스란?
서버리스(Serverless)는 단어의 의미만으로는 ‘서버가 없다’는 뜻입니다. 하지만 실제로 서버가 존재하지 않는 것이 아니라, 마치 서버가 없는 것처럼 –서버를 고려하지 않고– 애플리케이션을 실행할 수 있는 환경을 의미합니다. 서버리스를 활용하면 이미 갖춰진 클라우드 기반의 인프라를 이용하기 때문에 서버를 직접 구축하지 않고도 자원을 효율적으로 사용할 수 있을 뿐만 아니라, 비용도 절감할 수 있습니다. 더불어 개발자로서는 서버 운영과 유지 보수 등의 인프라 작업 대신 애플리케이션 개발에 집중할 수 있다는 장점이 있습니다.
여기서 클라우드와 서버리스의 중요한 차이는 ‘on-demand’라는 핵심 개념에 있습니다. 즉, 서버리스 환경은 서비스가 항상 구동되어 있는 상태가 아니라, 요청이 있을 때만 실행되다가 더 필요하지 않은 시점에 종료됩니다.
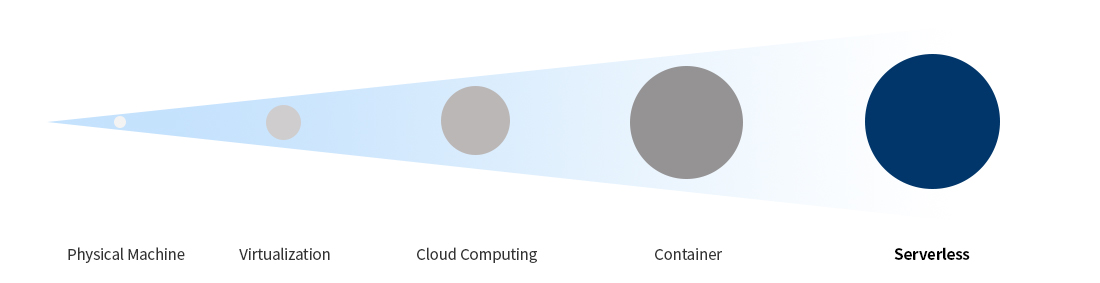
[그림 1] Serverless Evolution
유명한 소프트웨어 개발 전문가인 마틴 파울러(Martin Fowler)는 애플리케이션의 관점에서 서버리스를 ‘FaaS(Function as a Service)와 BaaS(Backend as a Service)를 결합한 콘셉트’라고 설명합니다. FaaS는 서비스를 작은 기능 단위(function)로 나누고 요청이 있을 때만 실행하도록 하는데, FaaS의 대표적인 구현체로는 AWS Lambda, Azure Function, Google Cloud Functions 등이 있습니다. BaaS는 Firebase나 Auth0같이 특정 기능을 하는 서비스를 API 형태로 가져다 사용할 수 있는 것을 말합니다.
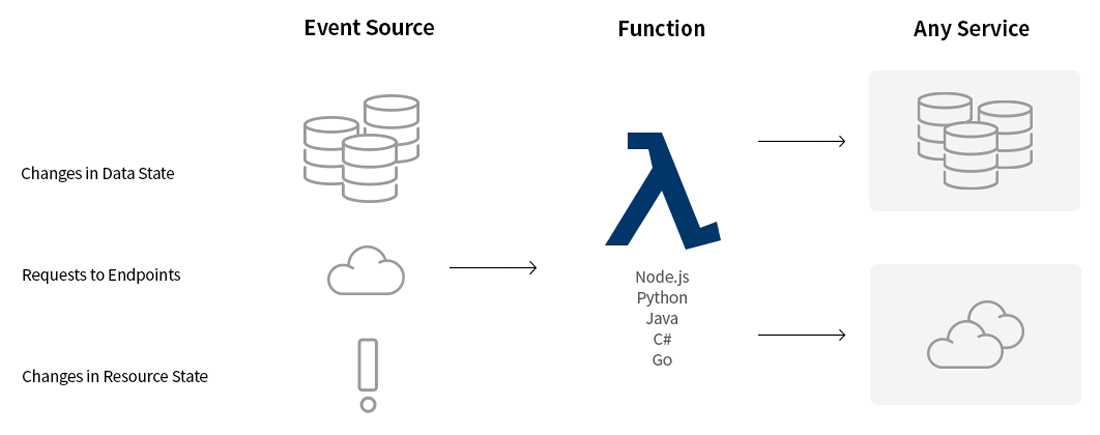
[그림 2] 서버리스 애플리케이션의 일반적인 실행 구조
FaaS는 HTTP 요청이나 cron/batch job 등 이벤트가 트리거되면 실제 동작하는 로직이 구현되는 Function을 호출합니다. Function은 보통 일회성 호출이기 때문에 상태를 저장하지 않으며(stateless), 실행의 결과는 BaaS에서 처리(DB 저장 또는 응답 전달 등)합니다. 그리고 역할을 끝낸 Function은 종료됩니다. 이처럼 요청이 있을 때만 인스턴스가 구동되기 때문에 기존의 ‘always-on’ 서버 구성보다 리소스를 절감할 수 있습니다.
오픈 소스 서버리스 플랫폼(Open-source Serverless Platform)
우리가 잘 알고 있는 AWS Lambda나 Google Cloud Functions 그리고 Azure Functions 등의 상용 서비스를 사용하면 편리하지만 이는 특정 클라우드 플랫폼에 종속되어 있습니다. 따라서 자체 인프라 환경(On-Premise)을 구축하고자 하는 사용자들을 위해 다양한 오픈 소스 서버리스 프레임워크가 등장했습니다.
엔씨는 자체 클라우드 인프라를 구축해 사용하고 있기 때문에 사내 I&O 조직*의 도움을 받아 오픈 소스 클라우드 서버리스의 표준으로 자리 잡고 있는 Knative를 대상으로 간단한 테스트를 진행했습니다.
*엔씨 I&O 조직은 안정적인 인프라 관리와 쿠버네티스 자체 운영을 하고 있습니다. 플랫폼센터의 서비스가 I&O 조직에서 제공하는 인프라에서 동작하기 때문에 다양한 기술 서비스 도입을 함께 검토하고 있습니다.
Knative를 사용하면 어떤 점이 좋을까?
Knative는 Google Cloud Service에서 IBM, Red Hat, Pivotal, SAP과 협력해 개발한 오픈 소스 플랫폼으로 ‘Kubernetes+Istio’를 확장해 더 나은 서버리스 환경을 제공하고자 만든 플랫폼입니다.

[그림 4] Knative 사용으로 기대할 수 있는 다양한 이점
Knative를 사용하면서 얻을 수 있는 이점들을 좀 더 직관적으로 알아보기 위해 쿠버네티스를 활용해 간단한 서비스를 배포한다고 가정해 보겠습니다.
가장 기본적으로 deployment, service 구성에 대한 yaml 파일을 작성하고, 외부에서 접근할 수 있도록 라우팅 설정 그리고 서비스가 잘 동작하고 있는지 확인하기 위한 모니터링과 로깅을 추가해야 합니다. 그 외에 카나리 배포(canary release)를 한다면 추가적인 설정 구성을 해야 합니다.
이처럼 쿠버네티스만을 사용할 때는 고려해야 할 사항이 많아집니다. 하지만 Knative는 auto-scaling, 빌드/배포나 라우팅 등 구성 작업에 대한 부분을 추상화해 제공하기 때문에 기본적으로 작성해야 하는 서비스 설정 파일에 단지 몇 줄 추가하는 것만으로 위에서 언급했던 것들이 가능해집니다.
그럼 지금부터 몇 가지 간단한 설정을 통해 Knative에서 제공하는 편리한 기능들을 어떻게 사용할 수 있는지 알아보겠습니다.
1. Auto Scaling을 통한 리소스 절감
매시간 실행되는 게시글 통계 배치가 있다고 가정해 보겠습니다. 이 배치 애플리케이션이 전용 VM 또는 쿠버네티스에 상시 구동되어 있다면, 애플리케이션이 동작하지 않을 때도 리소스를 점유하고 있어 비효율적입니다. 하지만 Knative에 구동된 서비스에서는 일정 시간 호출되지 않은 pod를 종료하고(down to zero), 해당 서비스에 대해 요청이 많아지면 자동으로 pod를 확장합니다. 따라서 앞에서 설명한 게시글 통계 배치 애플리케이션을 동일한 리소스를 활용해 여러 개 구동하는 것도 가능해집니다.
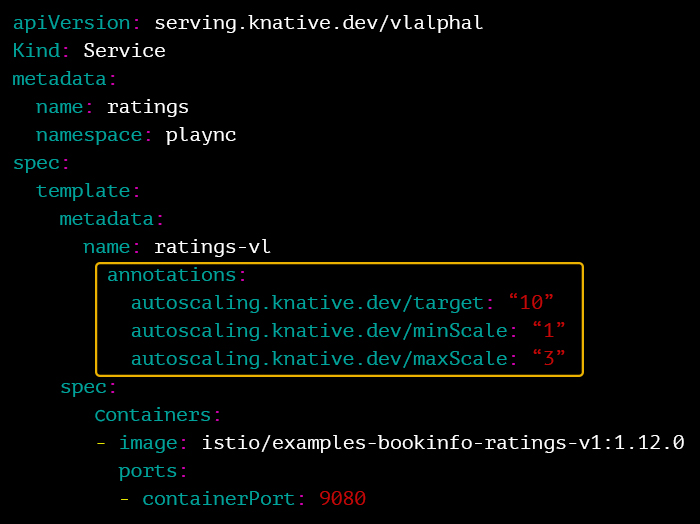
[그림 5] Knative 서비스의 auto-scaling 설정
2. 카나리 배포를 통한 리스크 감소
서비스에 기능이 추가되어 새로운 버전을 배포해야 할 때, 새 버전이 정상적으로 동작하는지 확인하고자 일부 트래픽만 처리하도록 분산해 배포하는 것이 바로 카나리 배포(canary release)입니다. 만약 새로운 버전에 문제가 있다 하더라도 서비스 전체가 아닌 일부에만 영향을 미치기 때문에 안전하게 배포할 수 있으며, 개발한 여러 버전 중 어떤 것을 적용할지 모니터링하는 데도 활용할 수 있습니다.
Knative에서는 간단한 설정으로 트래픽을 버전별로 분산시킬 수 있어 카나리 배포가 가능합니다.
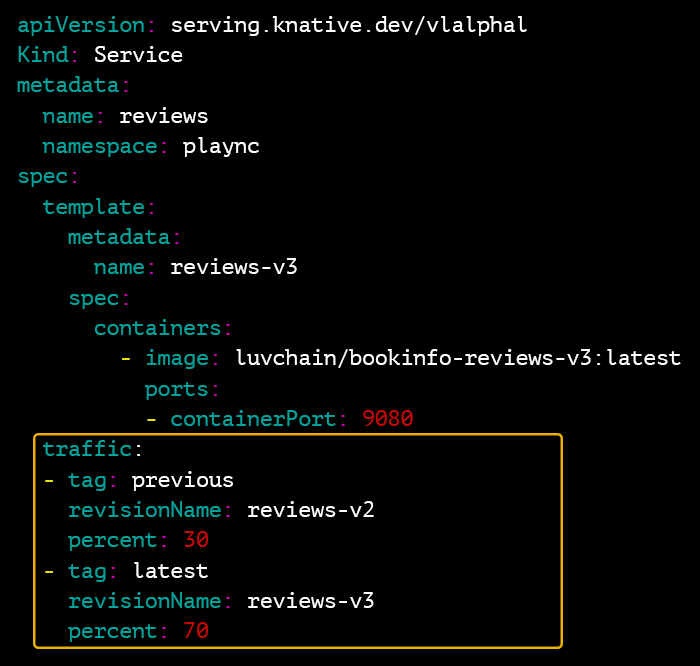
[그림 6] Knative 서비스의 트래픽 라우팅 설정
3. 이벤트 트리거
또한 Knative는 이벤트가 발생하면 이를 받아서 처리하고 전달해 주는 비동기 메커니즘을 제공합니다. 카프카(Kafka) 같은 메시지 큐(queue)나 pub/sub, cron과 같이 이벤트를 발생시키는 자원들을 Knative에 등록하고, 이벤트가 발생하면 지정된 Knative 서비스로 메시지를 전송하도록 구성할 수 있습니다.
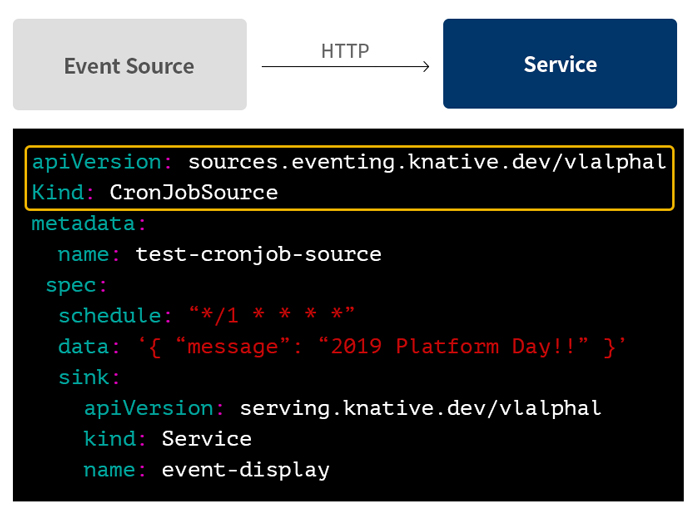
[그림 7] Knative의 이벤트 트리거 설정
4. 편리한 모니터링
이 외에도 다양한 모니터링 툴을 제공함으로써 편리한 서비스 모니터링이 가능하다는 장점이 있습니다. 특히 Kiali에서는 서비스 간 트래픽이 어떻게 라우팅 되는지 직관적으로 제공합니다.
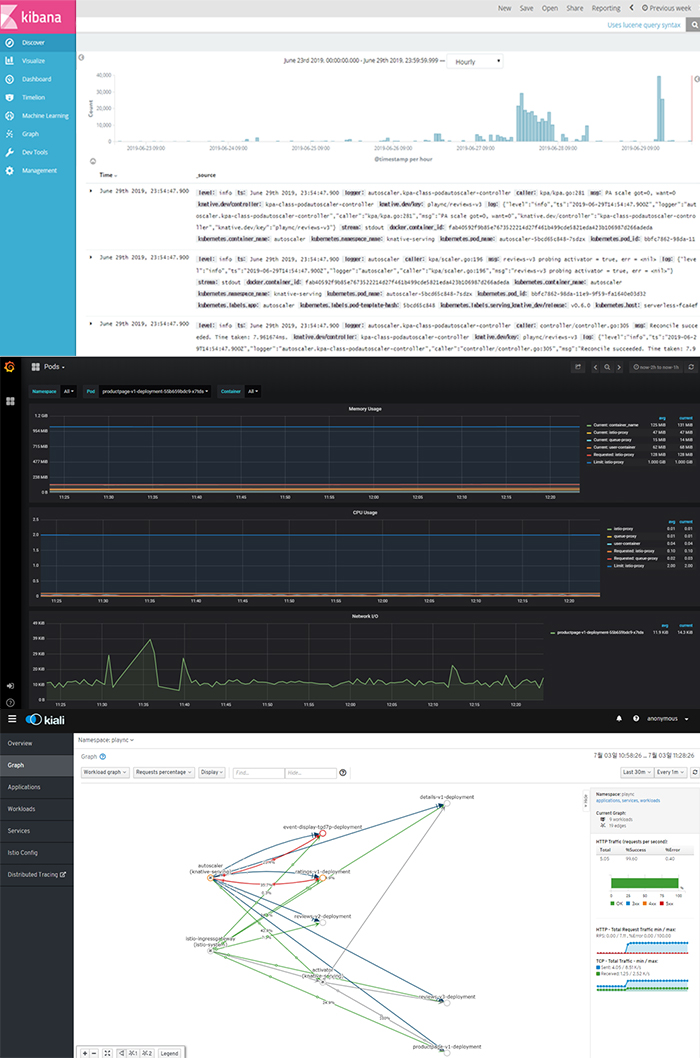
[그림 8] Knative에서 제공하는 다양한 모니터링 툴(차례대로 Kibana, Grafana, Kiali)
서버리스 도입 시 고려할 사항
지금까지의 내용을 바탕으로 서버리스와 Knative를 살펴보면 비용 절감 측면과 편의성에서 긍정적인 결과를 기대할 수 있을 것으로 보입니다. 하지만 서버리스를 우리 플랫폼에 바로 도입할 수 있을까요?
1. Startup Latency
요청이 있을 때마다 인스턴스를 새로 구동해야 한다는 것은 매번 애플리케이션 실행에 시간이 소요된다는 의미입니다. 서버리스에서는 다음과 같이 인스턴스의 초기화 단계를 크게 두 가지로 구분합니다.
Warm Start: 이전 이벤트의 Function과 인스턴스를 재사용
Cold Start: 새로운 인스턴스를 생성하고 Function을 시작
요청이 있을 때마다 인스턴스를 새로 생성하는 Cold Start가 발생한다면 어떨까요? 배치와 같이 실시간성을 요구하지 않는 애플리케이션이라면 큰 문제가 없겠지만, 바로 응답을 주어야 하는 경우에는 인스턴스가 구동되어 Function을 실행하기까지 대기 시간(delay)이 발생하게 됩니다. 요청이 빈번하지 않은 애플리케이션에서 Cold Start는 피할 수 없는 이슈이기에 인스턴스를 빠르게 구동할 방법에 대한 연구가 필요합니다.
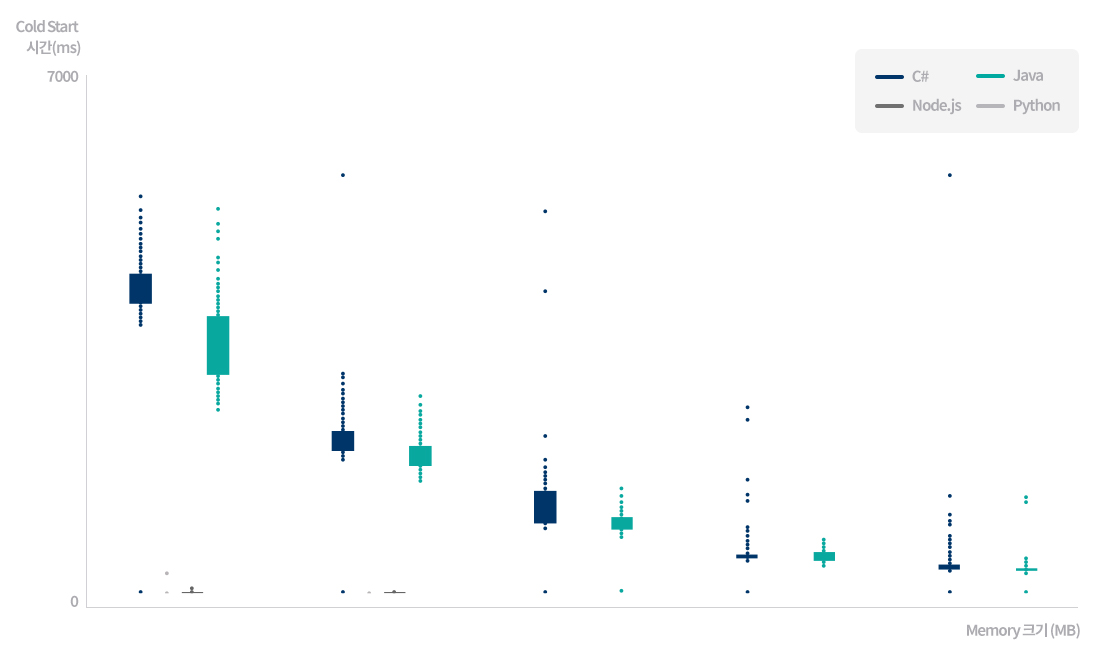
[그림 9] AWS Lambda의 언어/메모리에 따른 Cold Start 시간
서버리스 플랫폼이 인스턴스를 초기화하는 데 소요되는 시간은 사용하는 언어, 라이브러리 수, 코드의 볼륨, 환경 설정 등 여러 요인에 따라서 몇 밀리초(ms)에서 최대 몇 초(s)에 이르기까지 다를 수 있습니다. [그림 9]는 AWS Lambda에서 언어와 메모리 크기에 따른 Cold Start 시간의 차이를 테스트한 그래프입니다. 결과에 따르면 Python이나 Node.js보다 Java와 C#의 Cold Start 시간이 100배 이상 길며, 메모리가 클수록 언어 간 격차가 줄어드는 것으로 나타났습니다. 그런데 플랫폼센터에서 서비스하고 있는 대부분의 웹 서비스는 Java 기반의 스프링 프레임워크(Spring Framework)를 사용합니다. 따라서 Cold Start 지연과 메모리 사용을 줄이는 것은 반드시 해결해야 할 아주 중요한 문제입니다.
2. 최적화 이미지 필요
쿠버네티스 도입 초기, 도커(docker) 레이어에 대한 이해도가 부족했을 때에는 빌드하여 생성된 jar 파일을 단순히 도커 이미지에 복사해 사용했습니다. [그림 10]

[그림 10] 스프링 부트(Spring Boot) 애플리케이션의 docker file
하지만 아래 [그림 11]에서도 보듯이 이 방식은 빌드할 때마다 jar 파일 크기만큼의 도커 레이어가 생성된다는 단점이 있습니다.
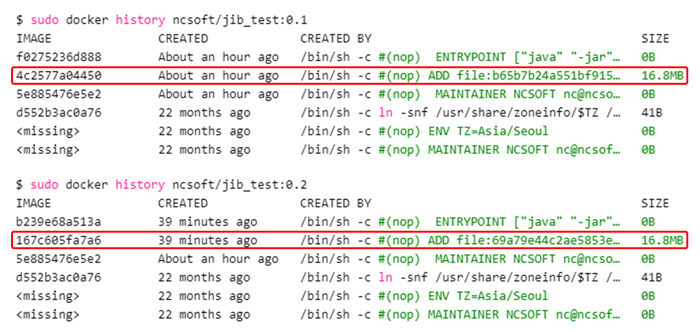
[그림 11] 최적화되지 않은 도커 이미지 히스토리
애플리케이션에서 수정되는 부분은 일부분이기 때문에 매번 jar 파일 크기만큼 도커 레이어가 생기는 것은 매우 비효율적입니다. 이러한 단점을 해결하기 위해 최적화된 이미지를 만들기 시작했습니다.
스프링 부트로 개발된 애플리케이션의 경우 일반적으로 [그림 12]와 같이 fat jar라고 하는 실행 가능한 형태로 되어 있는데, 이 jar 파일의 압축을 풀어 의존성(dependency) 라이브러리와 애플리케이션 코드 부분의 레이어를 분리해 구성하는 것입니다.
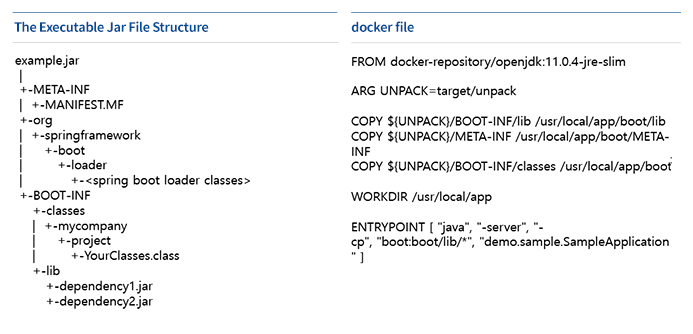
[그림 12] 실행 가능한 jar 파일 구조와 개선된 docker file
이렇게 하면 거의 변경되지 않는 의존성 라이브러리에 대한 도커 레이어를 재활용할 수 있어 빌드 시간과 배포 시 다운로드 시간을 줄일 수 있습니다. 추가로 Google에서 제공하는 Jib을 이용하면 위에서 설명한 최적화 방식으로 도커 이미지를 손쉽게 생성할 수 있습니다. 물론, 이미지를 최적화하는 것도 중요하지만 우선 프레임워크나 라이브러리는 꼭 필요한 것만 경량화 버전으로 사용하고 코드의 중복을 제거하는 작업이 선행되어야 합니다. 로직을 여러 작은 함수로 세분화하고 재귀 함수 호출은 사용하지 않는 것을 권장합니다.
3. HotSpotVM 대신 GraalVM
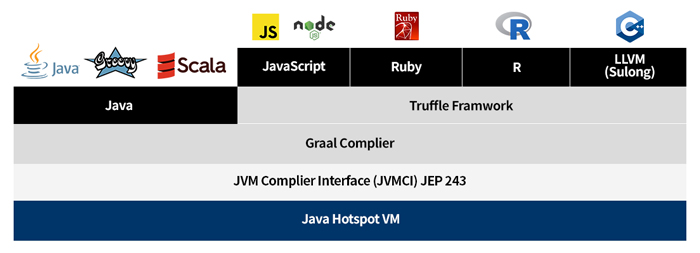
OpenJDK에서 사용하는 HotSpotVM은 최적화되어 머신 코드의 품질이 좋다는 장점이 있는 반면, 준비(warm up) 시간이 필요하기 때문에 시작이 느립니다. 그 대안으로 나온 것이 GraalVM이며, GraalVM은 Oracle Labs와 여러 대학 연구실에서 함께 진행하고 있는 프로젝트로 마이크로서비스에 이상적인 고성능 런타임 JVM입니다.
GraalVM은 성능 최적화를 위한 C2 컴파일러 대신 Java로 만든 새로운 JIT(Just In Time) 컴파일러인 Graal을 사용해 기존 방식보다 더 뛰어난 최적화를 목표로 하고 있습니다. 뿐만 아니라 Truffle이라는 프레임워크를 통해 Java 코드 내에서 다른 언어를 사용할 수 있도록 지원합니다.
GraalVM은 Native Image라는 툴을 제공합니다. 이 툴을 이용하면 AOT(Ahead-Of-Time) 컴파일을 통해 Java 코드를 바이너리(binary) 파일로 만들 수 있습니다. 여러 연구 결과에 따르면 Native Image를 사용하는 경우 사전에 바이너리 파일이 만들어지기 때문에 startup 시간이 최대 100배 빠르며 런타임에 코드를 로드하고 최적화하기 위한 인프라가 불필요하여 메모리 사용량을 최대 5배까지 줄일 수 있다고 합니다.
아래 [그림 14]의 그래프는 플랫폼 센터 내부적으로 GraalVM과 Native Image에 대해 몇 가지 테스트를 진행했던 결과입니다.
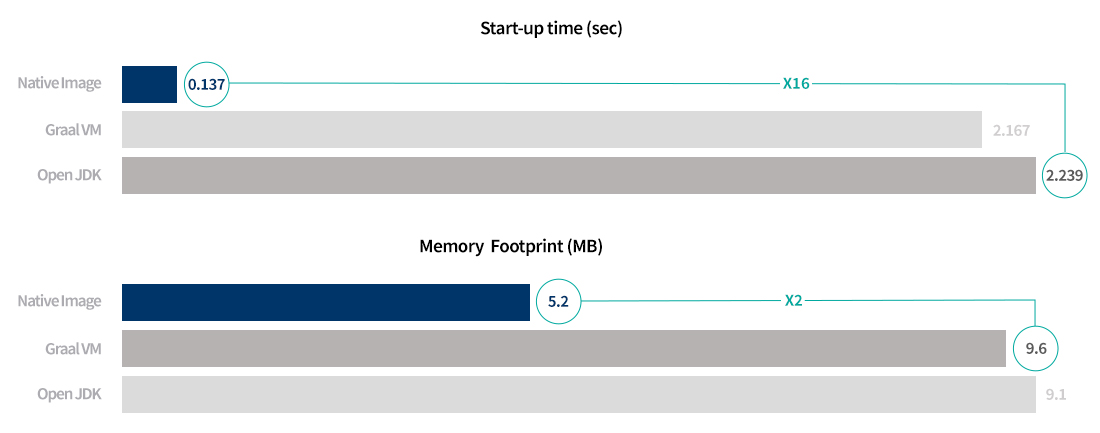
[그림 14] OpenJDK, GraalVM, Native Image 실행 환경에서의 startup 시간/메모리 사용량 비교
동일한 애플리케이션을 OpenJDK(HotSpotVM), GraalVM 그리고 Native Image로 각각 실행했을 때의 startup 시간과 메모리 사용량을 비교한 것입니다. OpenJDK(HotSpotVM)로 실행했을 때보다 Native Image로 실행한 경우의 startup 시간이 16배 정도 빨랐으며, GraalVM보다 메모리를 2배 정도 적게 사용하는 것으로 나타났습니다.
하지만 Native Image는 아직 성숙하지 않은 기술이기 때문에 미흡한 부분이 있습니다. 특히 AOT 컴파일을 하게 되면 런타임에서 동적 클래스 로딩이 불가능하다는 점이 가장 큰 제약입니다. GraalVM에서 JNI(Java Native Interface), Java Reflection(런타임 시 클래스, 메소드, 필드 및 프로퍼티를 검사하고 수정하게 해 주는 기능) 등 동적 기능을 사용하려면 해당 요소에 대한 구성을 애플리케이션 실행 시 직접 설정해야 합니다. 그리고 Native Image로 빌드 시 많은 리소스가 요구됩니다. 간단한 스프링 부트 애플리케이션을 빌드하는 데 최소 3분 이상 소요되었고, 16GB 메모리가 필요했습니다.
4. 스프링 부트의 대안은 없을까?
이 같은 한계에도 불구하고 GraalVM은 서버리스 환경에서 유용한 기술이며, Spring 팀에서도 GraalVM을 적극적으로 지원하기 시작했습니다. 하지만 최적화되지 않은 스프링 부트 애플리케이션은 매우 무겁고 startup 시간이 깁니다. 이러한 점을 보완하기 위해 Quarkus, Micronaut 그리고 Helidon 같은 Java Microservice 프레임워크의 사용을 고려해 볼 수 있습니다.
이들 프레임워크는 빠른 startup 시간과 메모리 사용량을 줄이도록 설계되었으며, 모두 Reactive 기반으로 GraalVM 및 Native Image를 지원합니다. 특히 Quarkus는 Kubernetes-native java 프레임워크로 스프링 기술에 대한 호환성을 제공하기 때문에 상대적으로 접근성이 용이합니다.
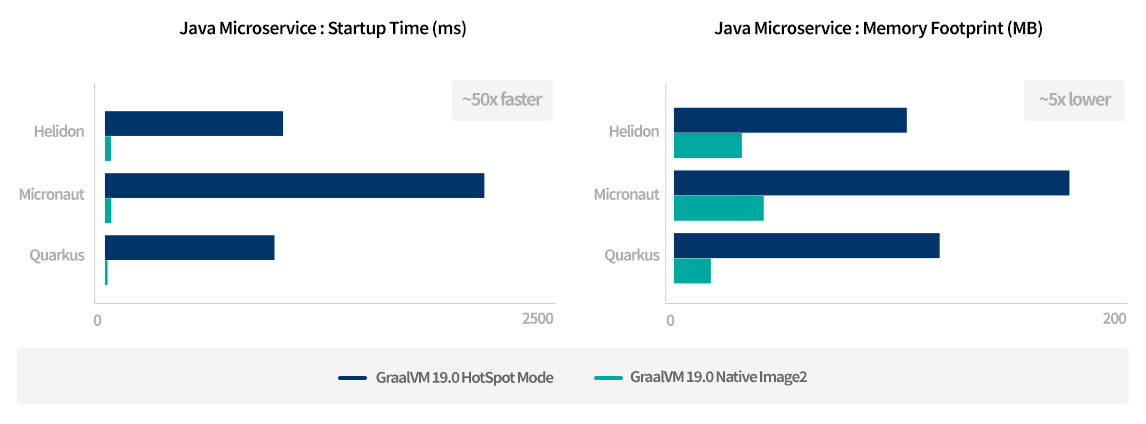
[그림 15] 마이크로서비스 아키텍처의 startup 시간 및 메모리 사용 비교
5. 그 외
위에서 설명한 startup 이슈 외에도 서버리스 애플리케이션에는 상태(state) 제약 때문에 설계 시 주의가 필요합니다. 애플리케이션 메모리의 변수나 로컬 디스크를 사용할 수는 있지만 여러 호출에 걸쳐 상태가 유지된다는 보장이 없기 때문입니다. 만약 상태를 저장해야 하는 경우라면 DB, Cache 시스템 또는 네트워크 파일 저장소를 사용해야 합니다.
마치며
서버리스가 기존의 모든 아키텍처를 대체하거나 모든 애플리케이션에 적용되기는 쉽지 않을 것입니다. 마틴 파울러의 말처럼 서버리스가 ‘No Ops’를 의미하지는 않지만 ‘No sysadmin’을 의미할 수는 있습니다. 서버리스는 분명 매력적인 기술입니다. 기술에 대한 충분한 이해와 서버리스 환경을 어떻게 구축해 어떤 애플리케이션에 적용하면 좋을지 충분히 검토가 이루어진다면 운영 및 비용 절감과 관리의 편의성 측면에서 긍정적인 결과를 기대할 수 있을 것입니다.
박윤영
Platform Center, Connective Platform 개발실
서비스를 모니터링할 수 있는 기반 솔루션을 개발하고 개발자들에게 제공함으로써
안정적인 플랫폼 운영에 기여하려는 노력을 하고 있습니다.
최근에는 서버리스 및 Service Mesh 등의 기술을 도입하기 위한 리서치를 진행하고 있습니다.
Platform Center, Connective Platform 개발실
서비스를 모니터링할 수 있는 기반 솔루션을 개발하고 개발자들에게 제공함으로써
안정적인 플랫폼 운영에 기여하려는 노력을 하고 있습니다.
최근에는 서버리스 및 Service Mesh 등의 기술을 도입하기 위한 리서치를 진행하고 있습니다.
 Facebook
Facebook  KakaoTalk
KakaoTalk  LinkedIn
LinkedIn  Email
Email  Copy URL
Copy URL