Vision AI Lab, which operates under the AI Center and competes as Team VARCO, was a finalist in the third round of the AI Grand Challenge hosted by the Ministry of Science and ICT. The goal of this competition, held from 2019 to 2022, was to solve various tasks in complex disaster scenarios using AI and robotics. Over four years, 175 teams and 935 participants tested their problem-solving skills in this multi-staged challenge.
Team VARCO won the first, second, and third stages in 2019, 2020, and 2021, respectively, and also won the fourth and final stage in 2022. Among the teams participating in the final challenge, they were the only team to win the previous three consecutive years and were recognized for their proficiency with AI technology. The challenge in the final competition was to operate a drone in a disaster scenario and complete the mission. This article follows Team VARCO's journey to victory by revealing how they solved the challenge.

Challenging Korea's Most Prestigious AI Challenge Competition
In 2019, Vision AI Lab researched digital image OCR (Optical Character Recognition) technology for game development QA (Quality Assurance). OCR technology recognizes text information appearing on the game screen, so it can also be used for translation and review.
Vision AI Lab has focused its research on technology that detects text in colorful and complex backgrounds, recognizes text in various fonts, and accurately recognizes game terms. They were able to confirm their technological competitiveness in the AI Grand Challenge.
OCR Technology Text Recognition on Game Screens
The third round of the AI Grand Challenge aimed to create an "Edge-Cloud Based Complex Disaster Response System Scenario," where a drone (Edge) is deployed to the disaster site to collect information. The collected information is then sent to the Central Disaster and Safety Management Center (Cloud) for analysis to establish a response plan, which is transmitted back to the rescue team on site.
The first (2019) and second (2020) stages of the third AI Grand Challenge competition, which started in 2019, were divided into four tracks: Situation Recognition, Text Recognition, Auditory Recognition, and Intelligent Control. From the third (2021) stage competition, the competition moved away from track-based differentiation, and participants were tasked with solving complex intelligence problems. The final tasks of the third competition involved gathering information about the situation of the person requesting assistance. These missions included capturing image and voice information inside a building using drones and collecting photos and reports from the person.
Building a Drone-Server Platform that Responds to Complex Disaster Situations in Real Time
The fourth stage of third round competition was different from previous competitions, where the missions were solved by analyzing only the given data. The challenge was to solve three missions that required the participating teams to operate the drone themselves and assess the situation of the requester of assistance within the building. Therefore, in order to participate in the competition, teams had to design and implement both drone and server platform pipelines.
The entire pipeline implemented prior to performing the mission consists of the following. The first step is to define the input and output data for each platform. The drone platform first acquires RGB images, depth images, audio, and drone location coordinates through the drone's sensors. Based on these inputs, the platform extracts several cognitive results and packages all the data to be transmitted to the server. The extracted results are also used to determine where the drone should move. The server delivers the data received from the drone to each mission process, and each mission process creates an answer and submits it to the grading server.
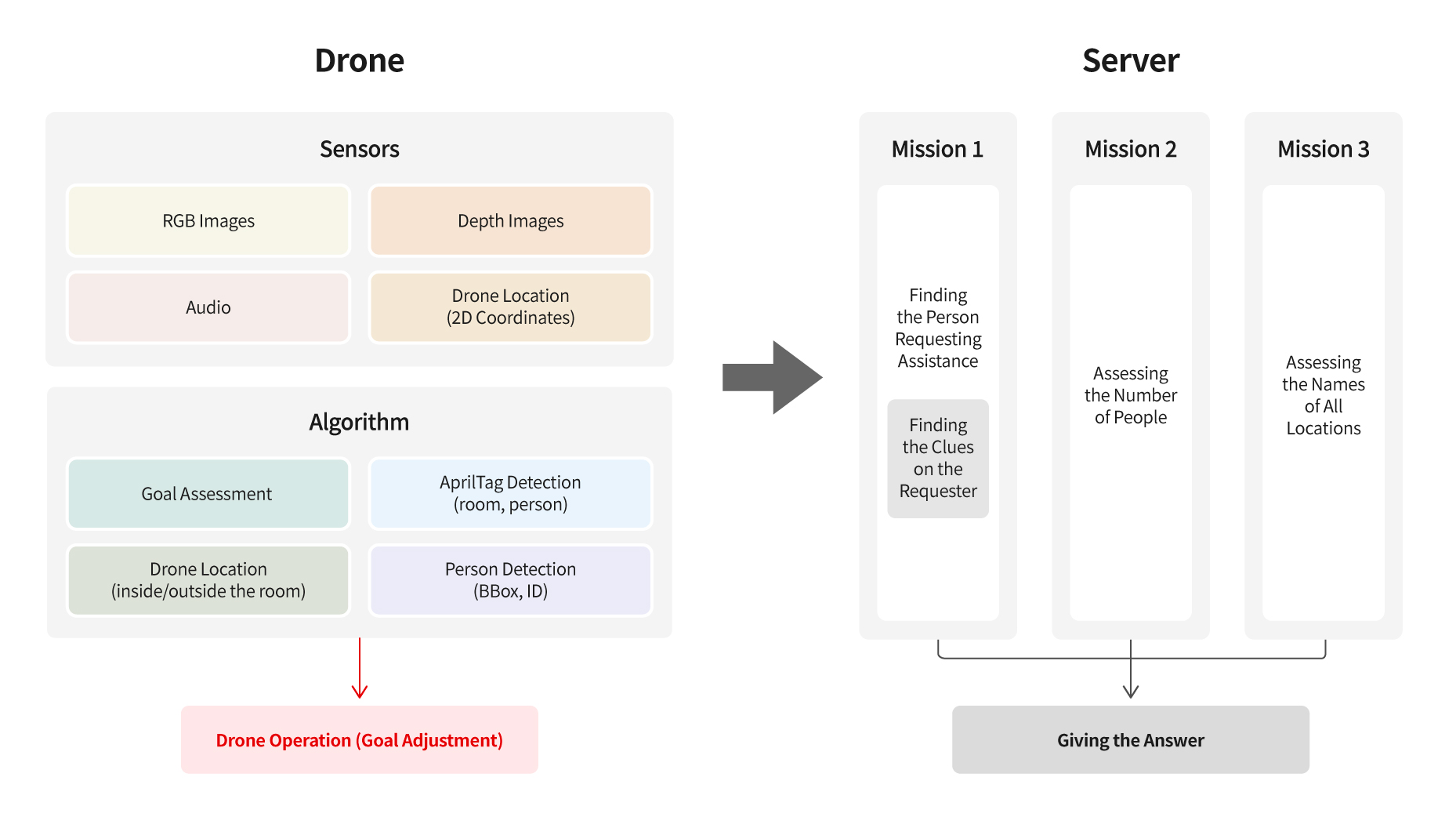
Implementation of Drone Platform Operation Algorithm
Team VARCO implemented person detection and AprilTag detection models on the drone platform to ensure that there was no time delay between the server and the drone platform while controlling the drone in real time. The team also applied technology, such as, Neural Architecture Search for model exploration and optimization/lightweight technology, such as, TensorRT Transformation and Tensor Decomposition to enable real-time extraction of multiple cognitive results during drone operation.
First Mission: Finding the Person Requesting Assistance
The first mission of the three was to find the person requesting assistance. To do so, the drone had to analyze the content of the photos and texts sent by the requester to identify them and where they were located. This could be broken down into three steps: 1) using the photos to determine how similar the space observed by the drone during flight is to the space indicated by the photos, 2) using the texts to determine how much of the content included in the texts can be seen in the space, and 3) determining which of the people in the same space is the person who made the request based on the information available.
Team VARCO applied Image Retrieval technology, commonly used in image search, to determine which scene observed by the drone was the most similar to the photo clues sent by multiple requesters. They also used Image Classification technology to determine what objects were in the scene and Person Detection technology to determine the number of people. By combining this information with information from the previously described photo clues, they were able to pinpoint the location of the requester.

Finally, using Text-based Person Retrieval technology, the team composed the upper and lower garment color information found in the text clues into sentences. (For example, "Upper garment: red, lower garment: black" data"woman with a red upper and black lower garment") Then, they found a person who was most similar to the person described in the sentence to identify the requester.
Second Mission: Locating Missing Individuals within Competition Venue
The second mission was to assess the number of people in each room and divide them into three classes: adult males, adult females, and children. Unlike the other two missions, this one required the use of both video and voice recognition. For instance, if the video analysis indicated two adult males in a room, but an adult female's voice was heard in the same room, it had to be assumed that the female was hidden or trapped in an unseen space. Therefore, the correct answer for the number of people in the room was two adult males and one adult female.
To assess the number of people in the mission through video, two difficult points needed to be resolved. First, mannequins needed to be distinguished by size and appearance into adult male, adult female, or child categories. Additionally, only those requiring rescue should be counted, and on-site personnel such as rescue personnel and doctors should not be included. Second, to avoid counting the same person twice, the drone moving around the room should not count someone that has already been counted when they come back into view after briefly being out of sight.

Team VARCO tackled the first problem by utilizing Image Classification technology. They gathered image databases of adult males/females, rescuers, and others, and trained a model to classify the detected person's class. Children were classified separately based on the size information of the mannequin rather than their appearance. For the second problem, the team employed Person Re-Identification technology that can recognize the same person among multiple images. Unlike traditional video-based Re-ID technology that solely relied on RGB information, they incorporated drone sensor data to improve the Re-ID performance by including the mannequin's location information.
Third Mission: Assessing the Names of All Locations
The third mission was to assess the name of the room by recognizing the nameplate attached to the entrance of each room. Team VARCO designed the algorithm as follows. First, they applied a model that could detect the entrance and nameplate in the input image, along with an OCR model to find the location of the entrance, nameplate, and characters. Particularly, they implemented it to recognize the content of characters near the entrance or nameplate. Next, they used the information from the detected entrance and the drone's position to determine the location of the entrance on a 2D map. Also, from the moment the drone entered a room until the moment it passed through an opposite entrance, it could assess the name of the room by accumulating the recognized characters during that time.
The following demo displays the process of assessing a room's name. The drone accumulates all the recognized character content from the moment it enters until it leaves. The integrated result of the name assessment, using the accumulated information, appears in the lower left corner. Upon leaving the room, the drone utilizes the accumulated information to estimate the new room's name.
1st Place in Finals Proves Vision AI Technology
Vision AI Lab entered the text recognition competition, but as they progressed, they realized the necessity for utilizing intricate and collaborative intelligence such as situation recognition, auditory recognition, and drone control. Many challenges surfaced, not only due to the expanded field of research but also because it was crucial to develop cognitive technology for disaster environments. In preparation for the competition, the team encountered two difficulties — the first being the necessity to process all missions in real time, and the second was the requirement to create all the necessary procedures to carry out the mission.
Vision AI Lab addressed the challenges by properly allocating the necessary technological elements to each platform. They overcame difficulties by simulating a disaster environment, identifying and resolving problems through numerous pre-tests, and improving as necessary. Additionally, the team rented extra space for pre-tests, beyond those provided by the competition organizers.
After earning second place in the first three stages, Team VARCO achieved first place in the final competition by leveraging years of accumulated expertise. The most significant accomplishment was the acquisition of Vision AI technology, which performs exceptionally well in disaster situations, and improving their comprehension of the platform by directly handling drones and server devices.
Heading Toward Digital Human Interaction in Real Time
NCSOFT plans to use the human-object-text recognition technology obtained from the competition for future development of natural conversational digital human technology. The detection model researched for finding the position of text can be used to detect human faces or surrounding objects, while the time series model researched for recognizing text content can be used for gesture recognition.
In addition, based on the experience of developing multimodal cognitive technology that combines video, voice, and natural language, and the know-how in lightening/optimizing deep learning models, the company plans to use AI technology to improve the efficiency of its game services and content production. Vision AI Lab's cognitive technology accumulated throughout this competition will continue to be used as a spark in NCSOFT's goal of developing digital humans that can interact in real time.
 Facebook
Facebook  Twitter
Twitter  Reddit
Reddit  LinkedIn
LinkedIn  Email
Email  Copy URL
Copy URL 

