엔씨 AI CENTER 산하 Speech AI Lab이 음성 분야 Top-tier 국제학술대회, Interspeech에 논문 3편을 게재했습니다. 엔씨는 작년에 이어 또다시 학회에 이름을 올리며 기술력을 입증했습니다. 지난 기사(링크)에서 Speech AI Lab의 연구 문화를 공개한 바 있는데요. 이번 기사에서는 ‘Interspeech 2022’에 채택된 논문을 소개합니다.
이번에 등재된 논문 3편은 가창하는 AI와 TTS 모델의 응용 연구를 다루고 있습니다. 특히 발화를 보다 자연스럽게 만들기 위해 시도한 다양한 학습 방법에 주목해주시기 바랍니다. 또한 연구 내용과 더불어 데모 음성도 함께 공개합니다. 표현력이 한층 깊어진 AI 음성을 느끼고 경험해보시기 바랍니다.
적대적 다중 작업 학습 기반 가창 음성 합성 모델
: 음색 표현과 피치 표현을 효과적으로 분리 모델링하기 위한 연구
“Adversarial Multi-Task Learning for Disentangling Timbre and Pitch in Singing Voice Synthesis” Interspeech 2022
김태우, 강민수, 이경훈
데모: https://nc-ai.github.io/speech/publications/amtl-svs/
작년까지 Singing Voice TF팀에 있다가 올해부터 Music AI팀에서 음악과 관련된 AI를 연구하기 시작했다. 2021 Interspeech에 게재한 N-Singer는 가사 전달력을 개선하는 음성 합성 모델 연구였고, 올해는 가창 음성 합성의 자연스러움을 높이는 방향으로 연구를 진행했다. 기존 가창 음성 합성 모델은 비지도(unsupervised learning) 방식으로 멜-스펙트로그램의 음색과 피치를 분리했다. 하지만 음색과 피치에 대한 명시적인 정보 없이 언어(가사)와 노트(MIDI) 정보를 각각 독립적으로 모델링하기 때문에 음높이에 따라 나타나는 자연스러운 음색을 표현할 수 없었다. 그래서 가사와 노트 정보를 함께 모델링하면서 음색과 피치를 분리하기 위해 적대적 다중 작업 학습 방법을 제안했다.
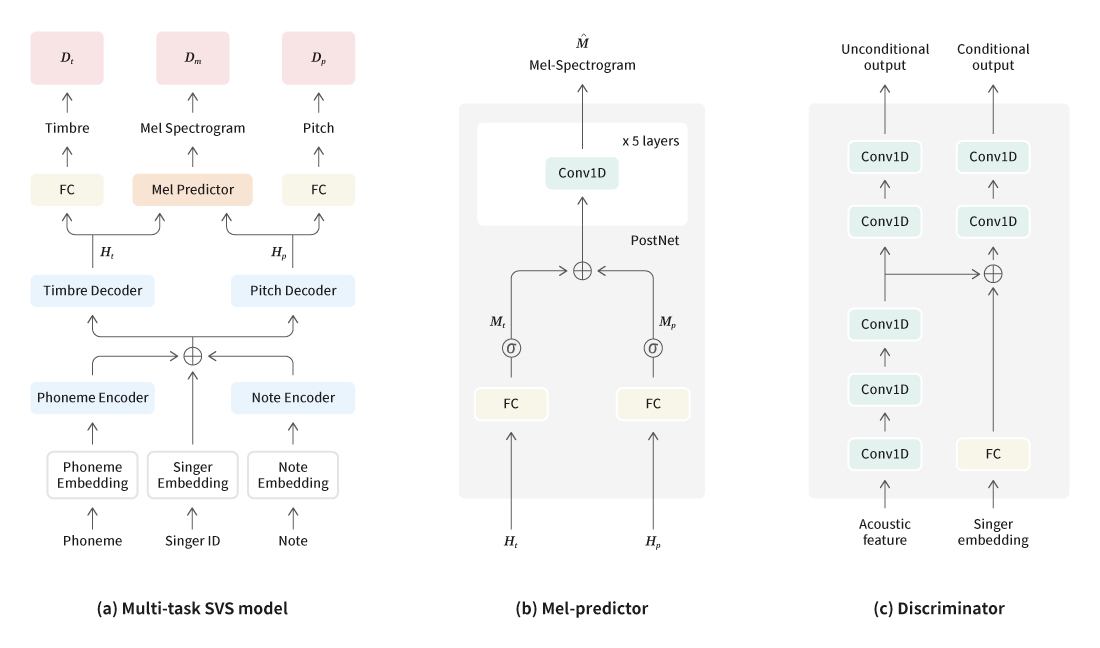
[그림 1] 적대적 다중 작업 학습 기반의 가창 음성 합성 모델 구조
가창 음성 합성 모델은 사용하는 보코더에 따라 음향의 특징이 결정된다. 크게 파라메트릭 보코더와 뉴럴 보코더를 사용하는 모델로 나눌 수 있다. 파라메트릭 보코더는 음성의 특징을 압축할 때 정보가 손실되므로 오디오 재구성상 성능의 한계가 있다. 반면 뉴럴 보코더는 멜-스펙트로그램을 품질 높은 음성으로 복원할 수 있지만 음색과 피치를 분리하기에 적합하지 않다. 그래서 본 연구에서는 파라메트릭 보코더의 음색과 피치를 나타내는 음성 특징과 뉴럴 보코더의 멜-스펙트로그램을 함께 학습하여 음색 표현(timbre representation)과 피치 표현(pitch representation)을 분리 모델링하는 합성 모델을 개발했다.
또한 적대적 생성 신경망(GAN) 각각의 음색과 피치의 표현을 더 정교하게 예측하여 합성음의 품질을 높였다. 결과적으로 멜-스펙트로그램의 음색과 피치를 분리하여 모델링할 수 있었을 뿐만 아니라 WORLD 보코더와 뉴럴 보코더를 모두 사용하여 기존 SVS 모델들보다 좋은 성능을 이끌어냈다.
Audio Sample 1
Sentence: 사라져가는 저 별빛 사이로 감출 순 없나요 커져버린 마음
(Pronunciation): salajyeoganeun jeo byeolbich sailo gamchul sun eobsnayo keojyeobeolin ma-eum
N-Singer + Parallel WaveGAN
AMTL-SVS + Parallel WaveGAN
Audio Sample 2
Sentence: 이제 다른 생각은 마요 깊이 숨을 쉬어봐요 그대로 내뱉어요
(Pronunciation): ije daleun saeng-gag-eun mayo gip-i sum-eul swieobwayo geudaelo naebaet-eoyo
N-Singer + Parallel WaveGAN
AMTL-SVS + Parallel WaveGAN
연구 과정에서 음색과 피치 특징의 예측 성능에 따라 멜-스펙트로그램의 예측 성능이 영향을 받는 것을 발견했다. 이를 해결하기 위해 멜-스펙트로그램뿐 아니라 보조적 특징인 음색과 피치 특징도 GAN 학습을 통해 예측도를 높여 멜-스펙트로그램의 예측 성능도 함께 향상했다. 그 결과 더욱 자연스러운 가창 음성을 합성할 수 있었고, 여러 가수의 가창 음성을 하나의 모델로 생성할 수도 있게 되었다.
사전 학습된 뉴럴 보코더를 이용한 새로운 음색 보존 피치 조절 방식
: 추가적인 녹음 없이 FastPitch TTS 모델의 피치 조절력 및 발화 품질을 향상하기 위한 연구
“Enhancement of Pitch Controllability using Timbre-Preserving Pitch Augmentation in FastPitch”, Interspeech 2022
배한빈, 주영선
데모: https://nc-ai.github.io/speech/publications/vocgan-ps-fastpitch/
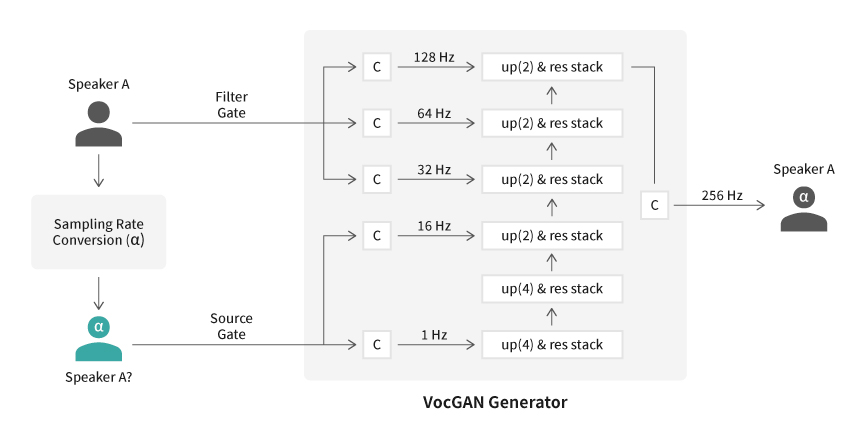
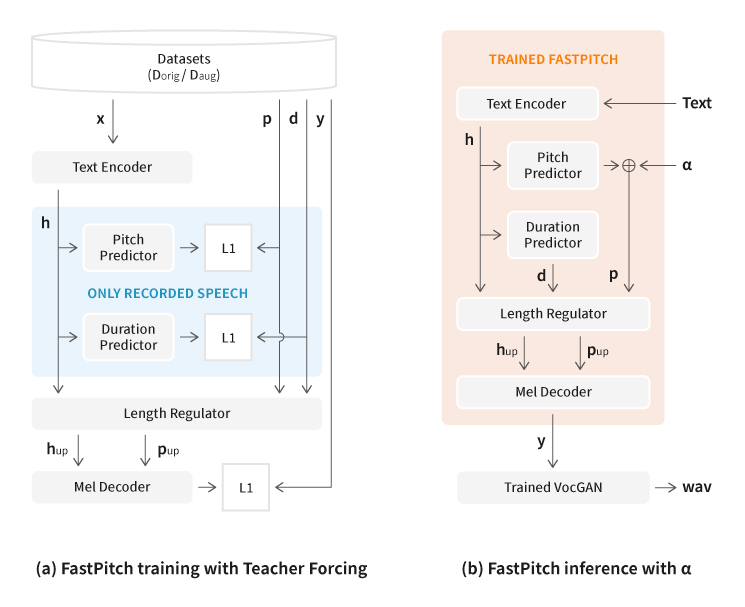
Text-to-Speech (TTS) 모델은 주어진 텍스트로부터 타깃 화자의 음성을 생성하는 음성 합성 모델이다. TTS 모델 연구에서 End-to-End 학습 기법이 발전하면서 실제 사람과 구분하기 힘들 정도로 자연스러운 음성을 생성할 수 있게 되었다. 본 연구에 사용한 FastPitch 모델은 음소 단위 스타일을 조절하는 데 특화되어 있다. TTS 모델의 학습을 위해 녹음한 데이터는 스타일이 다양하지 않은 낭독체 위주의 음성들로 이루어지기 때문에, FastPitch 모델을 학습하는 경우 피치를 조절하여 생성한 합성음에서 오발화 같은 음질 저하 현상이 나타난다.
이러한 문제를 해결하는 가장 기본적인 방식은 기존 TTS 데이터보다 훨씬 다양한 피치 정보를 가지고 있는 음성을 추가로 녹음하는 것이다. 그러므로 많은 추가 비용과 노력이 필요하다. 따라서 음성합성팀은 추가로 녹음하지 않고 기존 TTS 학습용 데이터로 피치 정보가 다양한 데이터를 얻어야 한다는 결론에 도달했다. 이를 위해 기존 음성의 음색을 보존하면서 피치를 시프팅할 수 있는 방식인 VocGAN-PS를 제안했다.
이 방식은 피치 및 추가적인 음성 정보를 위한 예측 알고리즘이 필요 없다. 또한 원본 음성의 화자 음색을 보존한 품질 높은 피치 증강 데이터를 얻을 수 있다. 즉, 동일한 화자의 다양하고 품질 높은 피치 데이터를 확보할 수 있는 것이다. 그 결과 확보한 데이터를 활용하여 FastPitch TTS 모델의 피치 조절력 및 발화 품질을 크게 높였다.
아래는 TD-PSOLA, WORLD 보코더, 그리고 제안한 VocGAN-PS를 사용하여 원본 음성을 +3 semitone만큼 시프팅한 음성이다. 정량적 평가 및 청취 평가에서 VocGAN-PS의 성능이 다른 알고리즘들을 상회했으며, 특히 음질 청취 평가에서 보다 높은 점수를 기록했다.
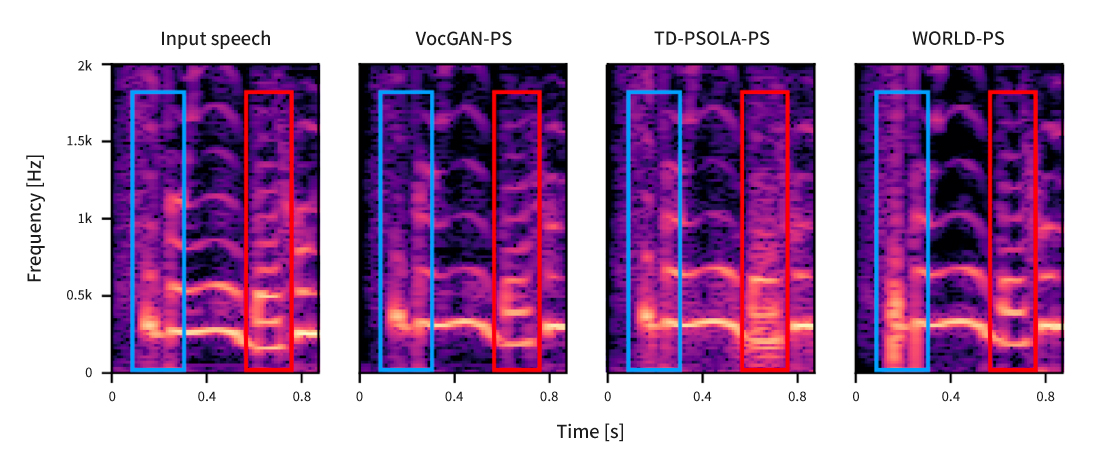
[그림 4] TD-PSOLA, WORLD 보코더, 그리고 제안한 VocGAN-PS로 원본 음성을 +3 semitone만큼 시프팅한 음성의 스펙트로그램
이 연구는 기존 TTS 학습용 데이터를 사용하여 피치 정보가 다양한 데이터를 얻기 위한 노력에서 시작되었다. 그 과정에서 뉴럴 보코더가 어떠한 방식으로 음성을 만드는지 연구하고 분석할 필요가 있다고 직감했다. 이후 원리를 파악하기 위해 시작한 연구에서 VocGAN의 음성 생성 원리에 대한 단서를 찾을 수 있었다. 그 결과 VocGAN-PS 알고리즘을 발명했고, 이 알고리즘을 TTS 및 Voice Conversion 모델을 개선하기 위한 데이터로도 사용했다.
계층적 다중 스케일 구조의 Variational Autoencoder 기반 TTS
: 합성음의 표현력을 다양화하여 자연스러움을 향상시키기 위한 연구
“Hierarchical and Multi-scale Variational Autoencoder for Diverse and Natural Speech Synthesis” Interspeech 2022
배재성, 양진혁, 박태준, 주영선
데모: https://nc-ai.github.io/speech/publications/himuv-tts/
사람은 같은 문장을 읽더라도 조금씩 다르게 표현할 수 있는 반면, TTS (Text-to-Speech)는 일반적으로 입력 문장을 평균 발화 스타일로만 생성한다. 이러한 아쉬움을 극복하기 위해 합성음의 표현력을 향상하는 기법을 계속 연구하고 있다. 자연스러움이나 운율의 다양성 측면에서 품질을 크게 높일 필요가 있었다. 그래서 이번 연구에서는 합성음의 자연스러움을 향상하는 것뿐 아니라 운율 모델링에도 초점을 맞췄다. 동일한 문장(텍스트)도 다양한 운율로 합성음을 생성할 수 있도록 계층적(hierarchical)이며 다중 스케일(multi-scale) 구조를 갖는 variational autoencoder 기반의 음성 합성(Text-to-Speech; TTS) 모델 HiMuV-TTS를 제안했다.
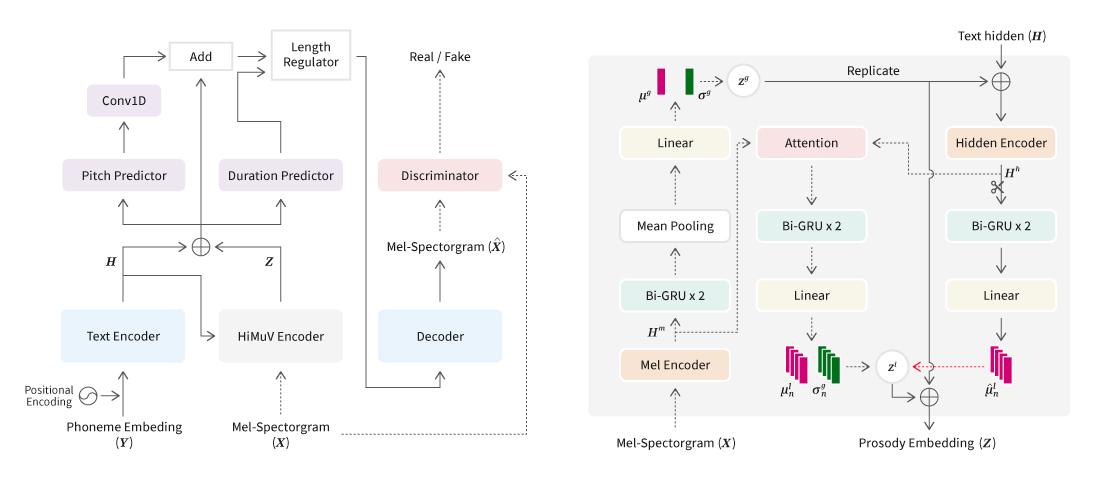
[그림 5] HiMuV-TTS 모델과 HiMuV-Encoder
한 문장의 전체적 운율(global-scale prosody)과 지역적 운율(local-scale prosody)을 모두 고려하기 위해 먼저 입력 문장(합성할 문장)에 대한 전반적인 운율 임베딩 백터(z_theta)를 생성했다. 그다음 전반적인 운율 임베딩 백터(z_theta)와 텍스트를 표현하는 임베딩 벡터(H)를 조건으로 입력하여 문장 내 지역적 운율 임베딩 벡터(Z_l)를 생성했다. 또한 합성음의 음질을 높이기 위해 음성 합성 모델 훈련 과정에 2021 Interspeech에 게재된 논문(J. Yang, J.-S. Bae, T. Bak, Y.-I. Kim, and H.-Y. Cho, “GANSpeech: Adversarial training for high-fidelity multi-speaker speech synthesis,” in Proc. Interspeech 2021. 바로가기)의 adversarial training 기법도 사용했다.
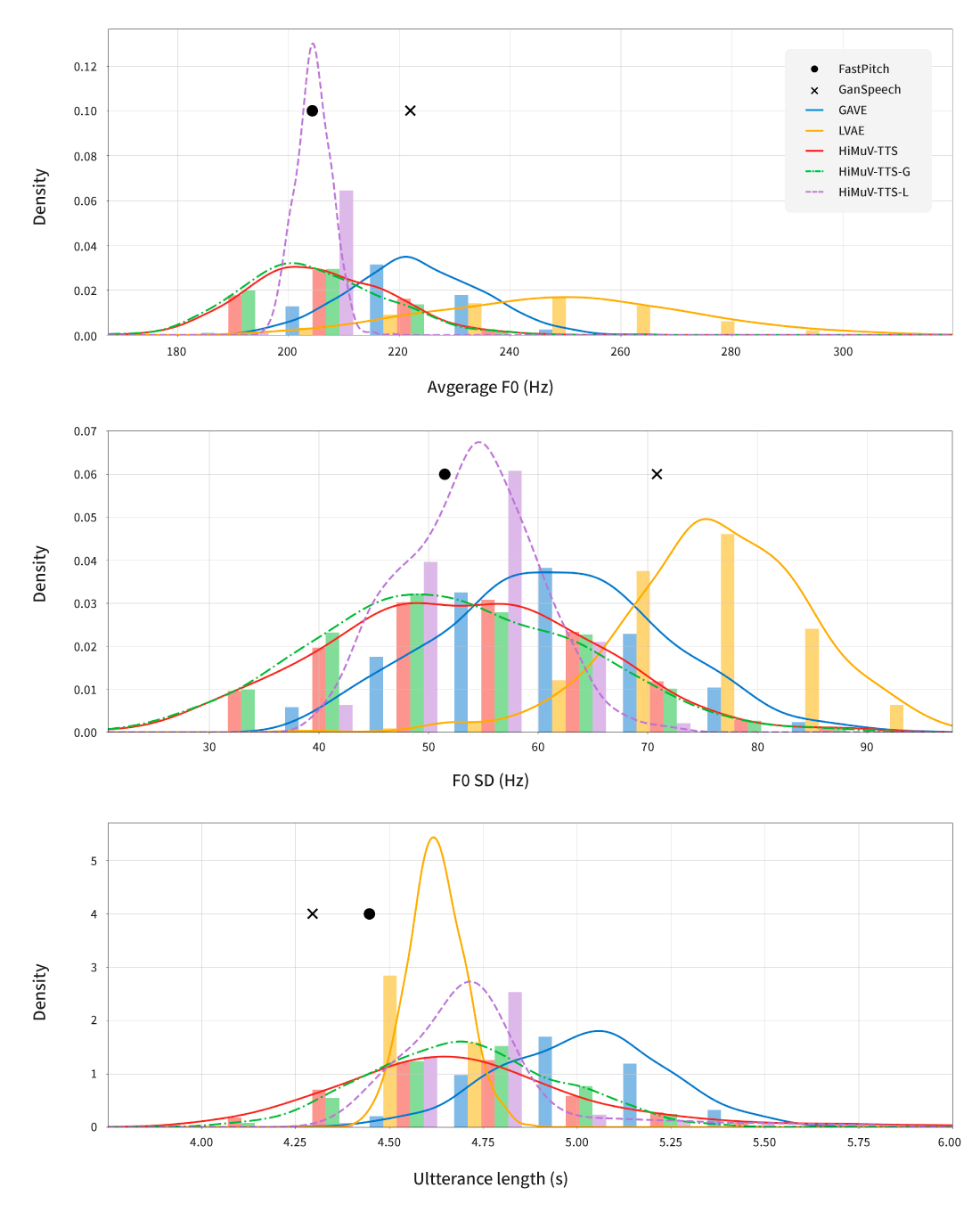
[그림 6] HiMuV-TTS와 다양한 합성 모델의 합성음 피치(1, 2번)와 문장 길이(3번) 분포 그래프.
이 그래프를 통해 HiMuV-TTS가 실제 사람의 다양한 표현력을 반영하여 합성음을 생성할 수 있음을 확인할 수 있다.
Audio Sample 4: FastPitch, GVAE, LVAE와 HiMuV-TTS의 음성 샘플 비교
Text: In another portion of the garden more clothing partly male and partly female was discovered.
Audio Sample 5: HiMuV-TTS 모델로 샘플링하여 생성된 다양한 화법의 음성 샘플들
Text: They entered a stone cold room and were presently joined by the prisoner.
이 연구를 통해 동일한 문장에 대한 음성 운율이나 빠르기, 끊어 읽기 등을 기존에 제안된 모델보다 자연스럽고 효과적이며 다양하게 생성할 수 있음을 확인했다. 하지만 실사용자가 운율의 여러 요소를 조절하며 본인이 원하는 음성을 쉽게 생성하려면 제안한 모델을 깊이 분석하고 추가로 연구할 필요가 있다. 이번 연구는 앞으로 실사용자가 원하는 음성을 다양하게 생성할 수 있도록 해줄 가능성을 열었다.
사람보다 사람 같은 음성 합성을 제공하기 위한 도전
지금 이 순간에도 Speech AI Lab은 새로운 시도를 계속하고 있다. 기존 AI 기술에 안주하지 않고 끊임없이 의심하고 부족한 점을 보완하여 AI 음성 합성 기술 개발을 넘어 음악 같은 다양한 분야와 융합하며 경쟁력 높은 NC만의 음성 AI 기술을 만들어갈 것이다. 또한 AI 음성 합성이 NC AI의 차세대 목표인 디지털 휴먼을 위한 핵심 기술인만큼 다양하고 차별화된 기술을 개발하고 있다. 현재의 목표는 다양한 언어를 구사할 뿐만 아니라 목소리와 어투만으로도 상황을 파악할 수 있을 만큼 풍부한 감정 표현, 다양하고 특색 있는 목소리, 이 음성 요소들을 자유롭게 컨트롤할 수 있는 수준 높은 음성 AI 기술을 구현하는 것이다. 궁극적으로 사람과 감정적으로 교감하고 소통할 수 있는 디지털 휴먼을 선보이기 위해 계속해서 도전할 예정이다.
 Facebook
Facebook  KakaoTalk
KakaoTalk  LinkedIn
LinkedIn  Email
Email  Copy URL
Copy URL