Facebook
Facebook  KakaoTalk
KakaoTalk  LinkedIn
LinkedIn  Email
Email  Copy URL
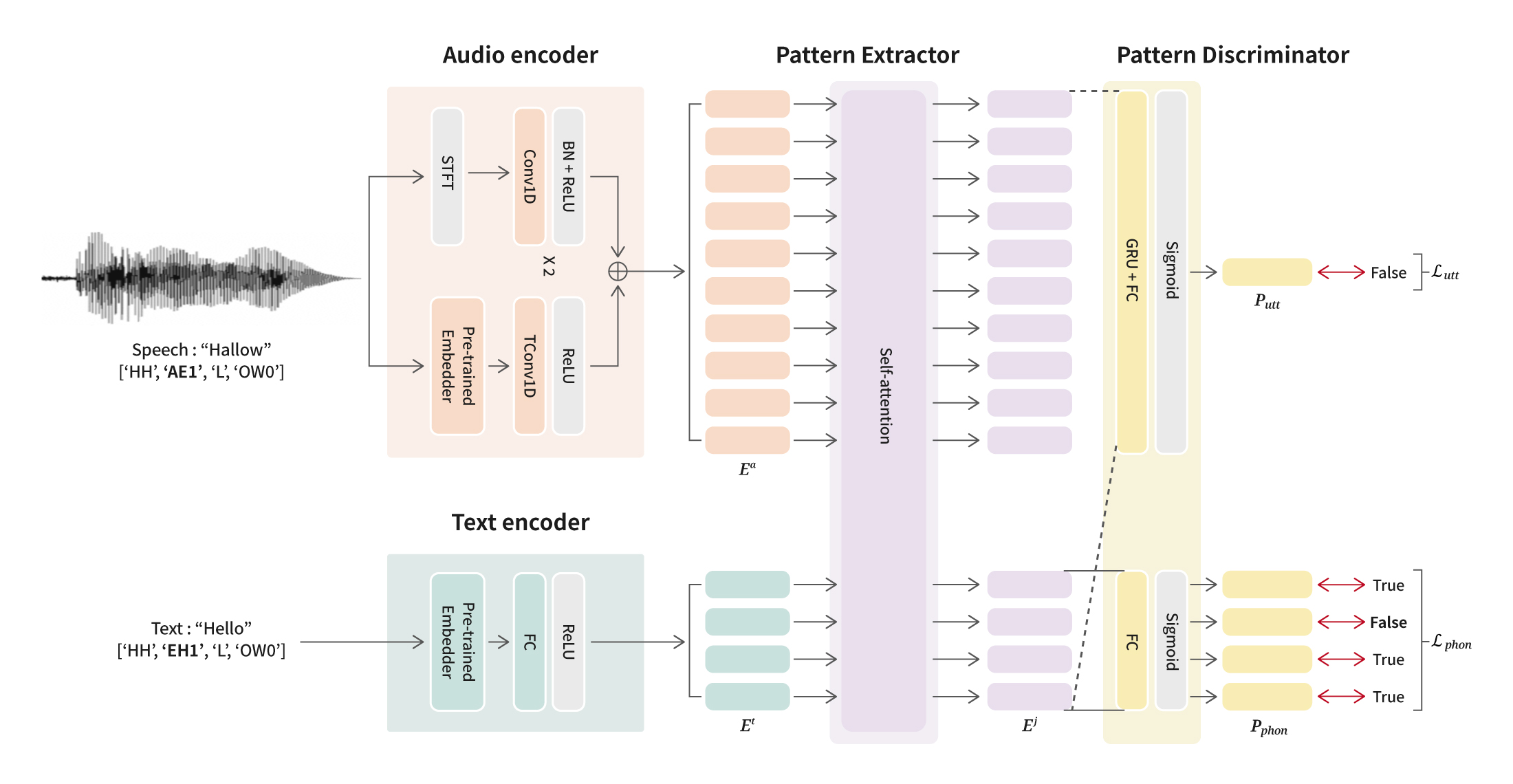
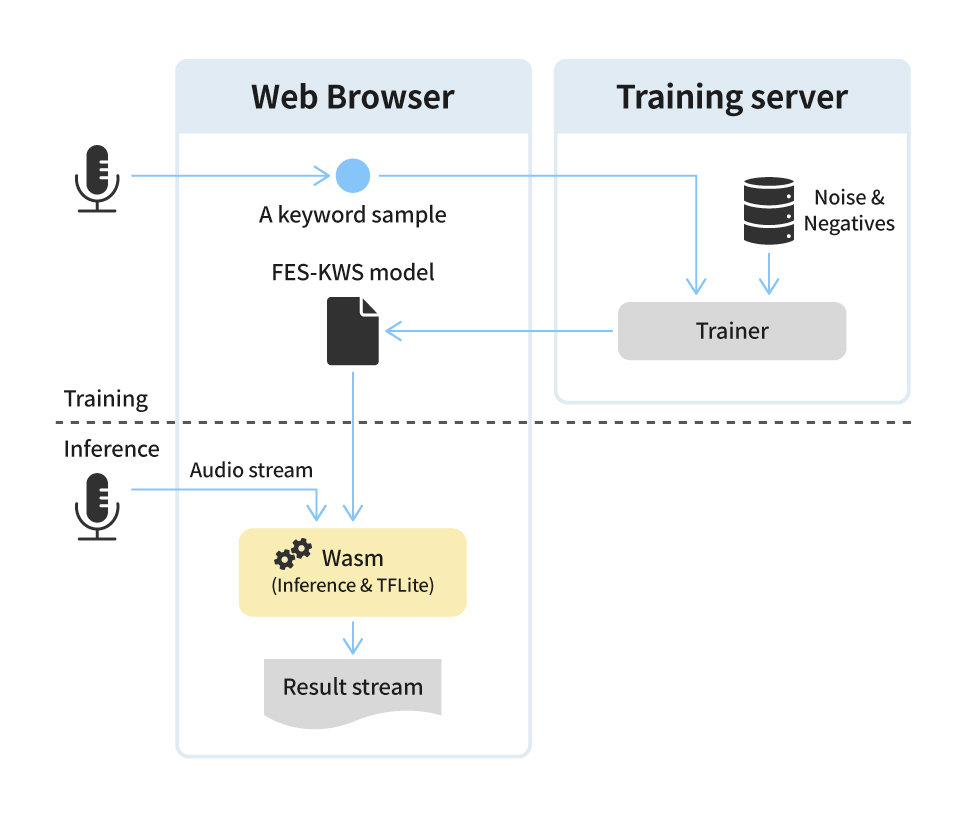
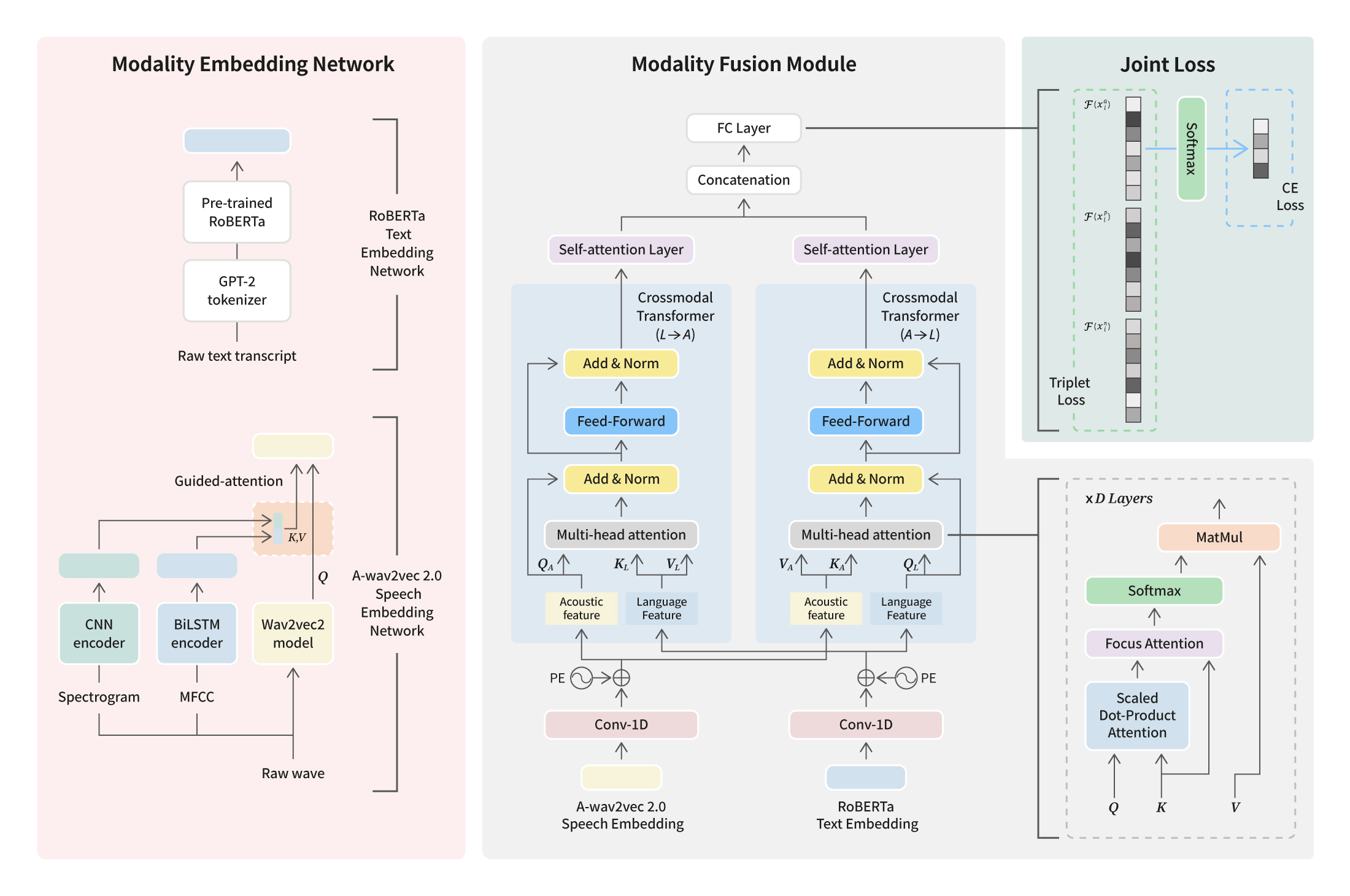
Copy URL 엔씨 AI Center 산하 Speech AI Lab이 음성 분야 Top-tier 국제 학술대회인 INTERSPEECH에 4년 연속으로 논문을 게재하는 성과를 거뒀습니다. Speech AI Lab은 발화와 음성의 퀄리티를 높이는 연구에 관한 논문들을 INTERSPEECH를 통해 선보여왔는데요. 이전에는 자연스러운 발화와 AI 가창 등에 초점을 맞추었다면, 이번에는 ‘사람과 상호작용할 수 있는 디지털 휴먼’을 위해 실제 사람과 소통하는 것에 가까운 경험을 제공하는 다양한 인공지능 모델과 시스템을 연구한 결과를 선보였습니다.
엔씨는 사용자와 소통할 수 있는 디지털 휴먼을 구현하기 위해 노력하고 있습니다. 사용자에게 최적화된 디지털 휴먼을 만들기 위해, 자연스러운 언어를 구사할 뿐만 아니라 사용자의 음성 및 동작을 인식하는 기술을 개발하는 데 주력하고 있습니다. 이번 INTERSPEECH에서 발표한 흥미로운 연구 성과들은 ‘내가 직접 별명을 붙여줄 수 있고’, ‘언제 어디서나 빠르게 대답하며’, ‘나의 마음을 읽고 공감해주는’ 나만의 디지털 휴먼의 등장을 앞당기는 데 도움이 될 것입니다. 음성 기술의 미래를 엿볼 수 있는 세 편의 연구 내용을 소개합니다.