엔씨소프트의 AI R&D 전문 조직 NC Research가 신호처리 분야 최고 권위 국제학술대회 'ICASSP 2024'(International Conference on Acoustics, Speech, and Signal Processing)에 논문 4편을 게재하는 성과를 거두었습니다. NC Research는 AI 원천 기술을 응용한 다양한 연구 결과를 산학계에 공개해왔는데요. 이번 ICASSP 2024에서는 ▲ 멀티모달 언어모델의 환각 현상 완화, ▲ 얼굴 인식 정확성 개선에 관한 Vision AI 논문 2편, ▲ 사용자 음성만 깨끗하게 걸러내는 호출어 인식 모델과 ▲ 얼굴 이미지에 맞는 가상 음성 생성 시스템을 제안한 Speech AI 논문 2편을 공개했습니다. 세계적 학술대회에서 인정받은 NC Research의 연구 결과를 만나보시기 바랍니다.
멀티모달 언어모델의 시각적 환각 현상을 완화하다
논문 제목: “Visually Dehallucinative Instruction Generation”
Multimodal AI Lab 차성국, 이주성, 이영현, 양철종
보다 자세한 연구 내용은 링크에서 확인하실 수 있습니다.
최근 텍스트, 이미지, 비디오, 음성 같은 멀티모달 데이터를 이해하고 생성하는 멀티모달 모델이 쏟아져 나오고 있다. 멀티모달 모델은 기존 언어모델보다 복잡하고 다양한 작업을 수행하며 사용자와 보다 깊게 상호작용할 수 있다. 언어모델은 모달리티가 여러 개일수록 여러 데이터를 학습하므로, 멀티모달 모델로 진화할수록 AI의 환각 현상이 심해질 수 있다. 그중 ‘시각적 환각 현상’이란 자동차가 없는 이미지를 AI에 제공하고 “자동차 어디 있어?”라고 질문했을 때 마치 자동차가 있는 것처럼 모델이 대답하는 현상을 말한다.
이 연구는 시각적 환각을 개선하기 위해 이미지 캡션에 기반한 질문-답변 형태의 인스트럭션 텍스트(Instruction Text)를 생성하는 인스트럭션 튜닝(Instruction Tuning) 기법 ‘CAP2QA’를 제시한다. 'CAP2QA'는 검증된 이미지 캡션을 사용하기 때문에 생성된 질의 응답 인스트럭션은 높은 신뢰성과 이미지-텍스트 정렬성을 보장한다. 또한 CAP2QA로 이미지 콘텐츠에만 제한되도록 설계한 시각적 지시 데이터셋 CAP2QA-COCO를 제작하여 배포했다. 대표적인 멀티모달 데이터셋인 COCO 캡션 데이터를 질문과 답변 형태로 변환하여, 질문을 받은 모델이 사진에서 추론할 수 있는 사실만 대답하여 시각적 환각 현상을 줄일 수 있는 인스트럭션 텍스트이다.
CAP2QA를 실험한 결과, 시각적 환각을 줄이는 데 효과적이며, 시각적 인식 능력과 표현력을 향상하는 것으로 나타났다. 나아가 기존의 정렬되지 않은 이미지-텍스트가 포함된 데이터로 학습한 모델과 함께 VQA(Visual Question Answering)를 비교 실시한 결과, 기존 모델 대비 시각적 환각이 현저히 줄고 멀티모달 인지 능력과 표현력이 일관되게 향상하는 것을 확인할 수 있었다.

기존 모델 vs. 제안 모델의 Visual Question Answering 실험 결과
시각적 지시 데이터 생성에 관한 새로운 방법을 제시한 이 연구는 제안 방식이 시각적 환각 현상을 완화하고 멀티모달 언어모델의 표현력을 향상하는 것을 실험적으로 입증하였다. 이러한 방법은 단순히 규모가 큰 데이터보다는 정확한 고품질 멀티모달 데이터가 모델이 더 나은 결과를 도출하는 데 도움이 된다는 것을 시사한다. 이러한 연구 결과는 다양한 서비스에 적용할 수 있는 멀티모달 언어모델의 신뢰성과 유용성을 높이는 데 기여할 것으로 기대된다.
열악한 환경에서도 정확한 얼굴 인식 방법을 제시하다
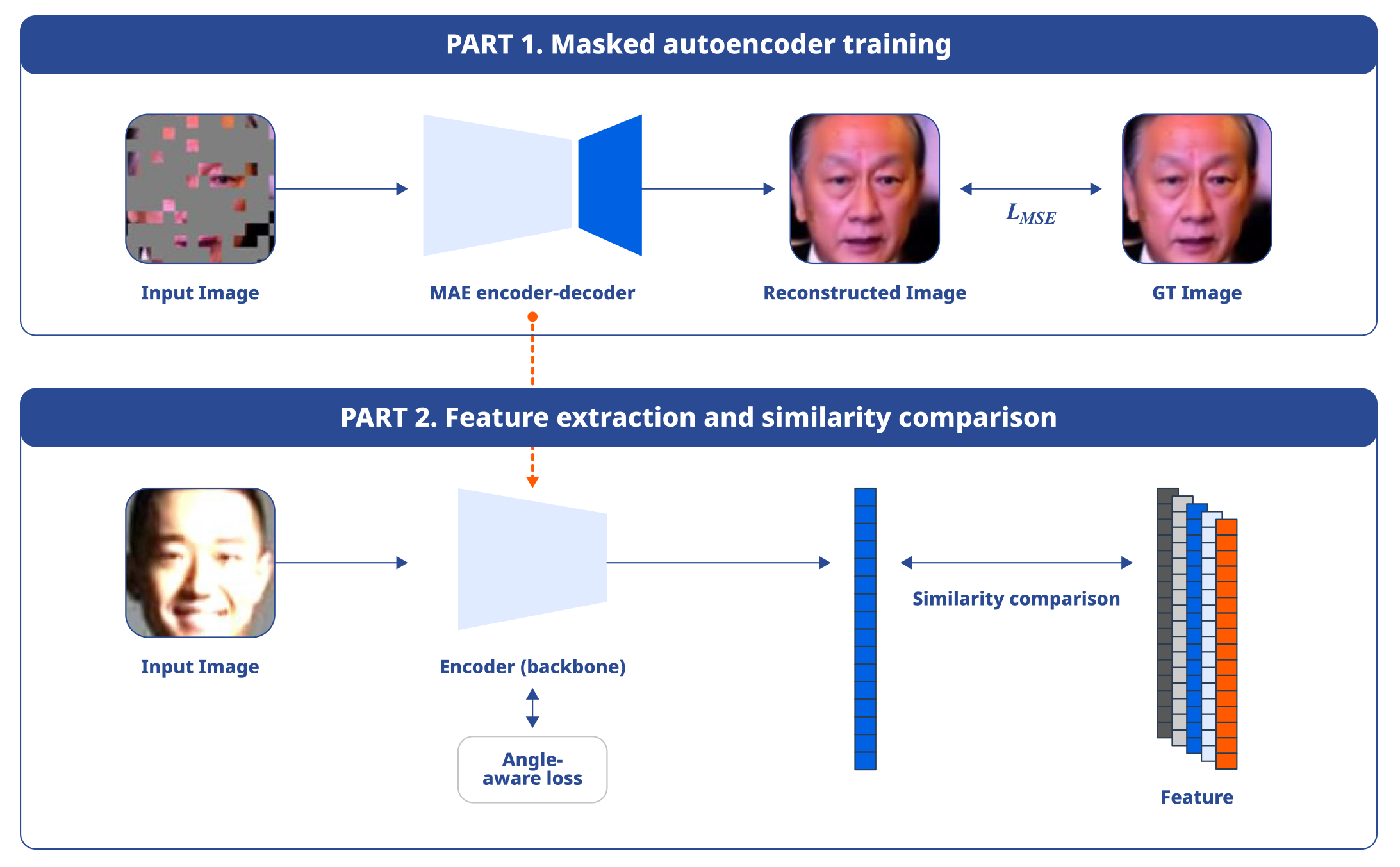
논문 제목: “Robust Face Recognition Based on an Angle-aware Loss and Masked Autoencoder Pre-training”
Multimodal AI Lab 최재협, 김영백, 이영현
보다 자세한 연구 내용은 링크에서 확인하실 수 있습니다.
얼굴 인식 기술이란 사람이 들어섰을 때 그 얼굴만 보고 누구인지 알아볼 수 있게 하는 기술이다. 얼굴 인식은 현대의 다양한 응용 분야에서 중요한 역할을 한다. 딥러닝 기반 얼굴 인식 기술이 나날이 발전하고 있지만 얼굴 각도 변화, 흐릿한 조명, 가림 현상 등의 열악한 환경에서도 인식의 정확성을 높이는 것은 여전히 중요한 기술적 과제다.
이번 논문에서는 열악한 환경에서도 우수한 얼굴 인식 성능을 발휘할 수 있는 얼굴 특징 추출기의 학습 방법을 제시하였다. 먼저 학습 이미지의 얼굴 회전 각도를 고려하여 마진을 동적으로 조절하는 '각도 인식 손실 함수(Angle-aware loss function)'를 도입하여 다양한 각도에서의 얼굴 인식 성능을 개선하고자 하였다. 또한 조명 변화나 얼굴 가림 같은 까다로운 상황에서의 인식 성능을 끌어올리기 위하여 '마스크된 오토인코더(Masked Autoencoder, MAE)'의 사전 학습을 통해 모델의 초기 가중치를 설정하는 방법을 제안하였다.
실험 결과 제안한 방법이 일반적 환경뿐만 아니라 조건이 열악한 환경에서도 기존 방법들에 비해 우수한 얼굴 인식 성능을 나타내는 것을 확인했다.
이 연구는 어려운 조건에서도 얼굴 인식 시스템이 안정적인 기능을 제공할 수 있는 최적의 접근 방식을 제안한다는 점에서 의미가 있다. 게이머의 얼굴이 카메라에 노출되어야 하는 게임 등 게이머의 얼굴 인식이 필요한 다양한 서비스에 활용할 가능성이 있다. 앞으로도 NC Research는 얼굴 인식 기술의 발전에 기여하며 다양한 응용 분야에 활용할 수 있는 가능성을 제시할 계획이다.
사용자 음성만 깨끗하게 걸러내는 호출어 인식 기술, iPhonMatchNet
논문 제목: “iPhonMatchNet: Zero-shot User-Defined Keyword Spotting Using Implicit Acoustic Echo Cancellation”
Audio AI Lab 이용혁, 조남현
보다 자세한 연구 내용은 링크에서 확인하실 수 있습니다.
음성 인식 기술에서 중요한 기능 중 하나는 사용자의 음성만을 잘 가려내는 것이다. 특히 헤드셋이 아니라 스피커를 사용하는 환경이나 TV 화면으로 플레이하는 콘솔 게임 등 여러 소리가 마이크에 들어가는 환경일수록 사용자의 음성만 정확히 인식할 필요가 있다. iPhonMatchNet은 스피커를 통해 다양한 소리가 발생하는 환경에서도 사용자가 설정한 키워드만 인식할 수 있는 호출어 인식 모델이다.
INTERSPEECH 2023에서 발표한 기반 연구 PhonMatchNet는 사용자가 원하는 키워드를 입력하면 즉시 해당 키워드만 인식하는 제로샷 호출어 인식 모델이다. 따라서 기존의 호출어 인식 시스템에서 사용자 경험을 저해하는 요소로 작용한 ‘샘플 목소리 녹음’과 ‘추가 학습’ 단계 없이 사용자가 원하는 호출어를 즉시 설정하고 인식할 수 있다.
iPhonMatchNet은 기존 PhonMatchNet 모델에 암시적 음향 에코 캔슬레이션(iAEC, Implicit Acoustic Echo Cancellation) 모듈을 적용하여, 기기가 출력하고 있는 스피커의 소리에 영향을 받지 않고 사용자가 정의한 키워드를 높은 성능으로 인식할 수 있다. 이번 논문을 통해 음악, 음성 같은 오디오 신호가 스피커에서 출력되는 상황에서 iPhonMatchNet의 인식 성능이 기존 PhonMatchNet보다 극적으로 향상됨을 입증하였다. 실험 결과에 따르면 기존 655K의 모델 대비 단 1K 개의 iAEC 관련 모델 파라미터만 추가하였는데도 자기 호출로 인한 호출어 오인식 케이스를 99% 이상 감소시킴을 보였다. 현재의 구조는 하나의 모델이 하나의 언어만 지원하지만 향후 이 모델에 IPA(International Phonetic Alphabet)를 적용하여 언어에 관계없는 통합 제로샷 호출어 인식 모델을 만들어가고자 한다.
얼굴과 잘 어울리는 가상 음성을 출력하는 음성 학습 기술, Synthe-Sees
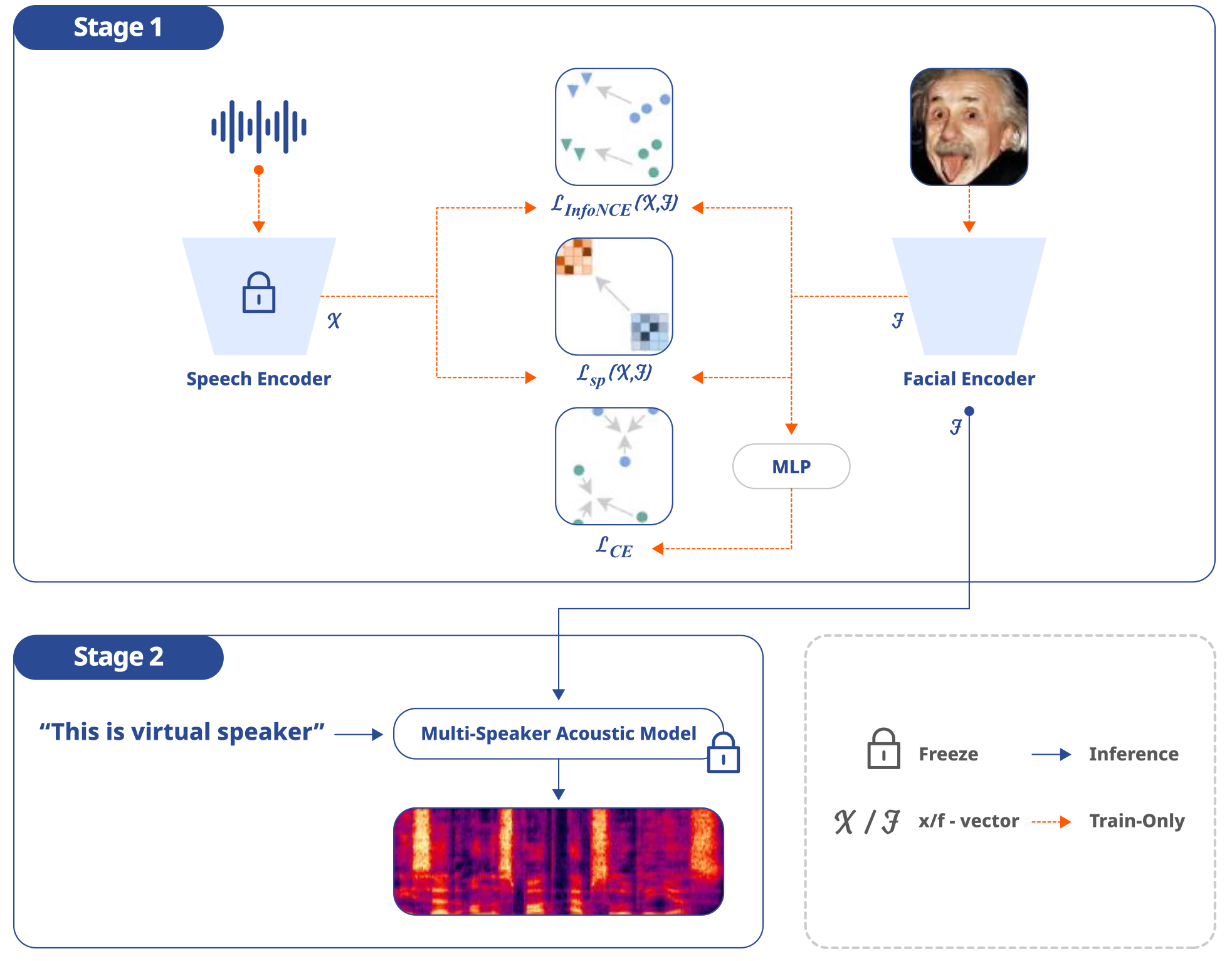
논문 제목: “Synthe-Sees: Multi-Speaker Text-to-Speech for Virtual Speaker”
Audio AI Lab 박재현, 맹준규, 주영선 / SK Telecom 박태준
보다 자세한 연구 내용은 링크에서 확인하실 수 있습니다.
최근 얼굴 이미지를 활용한 가상 음성 생성 기술이 연구되고 있다. 하지만 대부분의 기존 가상 음성 생성 기술은 같은 화자의 여러 얼굴 이미지에 대해 목소리가 동일한 음성을 생성하지 못하거나 다른 화자의 얼굴에도 비슷한 음성을 생성하는 등 일관적이지 못한 한계가 있다. 이 문제를 해결하기 위해 이 연구는 ‘사전 훈련된 다중 화자 TTS 시스템(Synthe-Sees)’을 위한 페이셜 인코더(Facial Encoder)* 모듈을 제안한다. 이 모듈의 목적은 얼굴 이미지를 이용하여 훈련을 위해 사용된 음성이나 기존의 음성 샘플과 다른 완전한 가상 음성의 화자 임베딩을 생성하는 것이다. 얼굴에 맞는 가상 음성을 생성할 수 있다면 훈련에 사용되는 음성 데이터베이스를 생성하는 데 필요한 시간과 비용을 절약하고, 새로운 음성을 추가하는 데 필요한 성우의 수를 줄일 수 있기 때문이다. 이를 통해 얼굴 이미지로부터 그럴듯한 목소리를 합성할 뿐 아니라 일관된 목소리를 생성할 수 있다.
Synthe-Sees의 페이셜 인코더는 2가지 방법으로 훈련되었다. 첫째, 일관된 화자 임베딩을 만들기 위해 화자 식별이 가능한 데이터셋을 이용하여 화자의 고유 특성을 추출하도록 훈련하였다. 둘째, 음성 임베딩의 내부 구조를 반영하도록 훈련하여 사전 훈련된 다중 화자 TTS 시스템이 다양하고 품질 높은 음성을 생성하도록 유도한다.
Synthe-Sees를 평가하기 위해 정량 평가와 정성 평가를 모두 실시했다. 정량 평가에서는 화자의 식별성과 다양성을 평가하기 위해 동일한 화자로부터 생성한 음성 임베딩의 일관성을 측정하는 등의 지표를 도입했다. 또한 정성 평가에서는 25명의 영어 원어민 참가자에게 20개의 음성 샘플을 제시하여 자연스러움, 명료함 및 음질 등의 항목들을 평가하였다. 평가 결과 양적 및 질적 평가 모두에서 다른 최신 방법들보다 더 뚜렷하고 일관되면서 품질 높은 음성을 생성한다는 것을 확인하였다. 데모 사이트는 다음 링크에서 확인할 수 있다. 바로가기
더 큰 즐거움을 만들 게임과 AI
엔씨는 게임과 맞닿아 있는 다양한 영역에서 ‘서비스 중심의 기술’을 개발하는 것을 목표로 하고 있다. 앞으로도 AI를 게임 제작 파이프라인에 더욱 밀접하게 결합하여 게임 개발 생산성과 게임 경쟁력을 높일 계획이다. 나아가 기술 연구의 방향이 궁극적으로 게임을 즐기는 플레이어에게 더 큰 즐거움을 제공하는 방향으로 전개될 수 있도록 사용자 중심의 AI 연구 개발에 집중할 예정이다. 앞으로 게임과 AI가 만들어낼 더 큰 즐거움을 기대해주기 바란다.
 Facebook
Facebook  KakaoTalk
KakaoTalk  LinkedIn
LinkedIn  Email
Email  Copy URL
Copy URL