엔씨가 국내 최초로 LLM(Large Language Model, 거대언어모델) 평가 모델 'VARCO Judge LLM'을 9월 20일 출시했습니다. Judge LLM은 LLM의 품질을 평가하는 특수한 목적의 언어모델로 AI 연구와 비즈니스 전반에서 LLM의 품질과 개발 효율성을 높이는 핵심 도구로 주목받고 있습니다. 특히 엔씨의 VARCO Judge LLM은 10B 이하의 동급 평가 모델 중 최고 수준의 성능을 발휘할 뿐 아니라, 올해 11월 마이애미에서 열리는 세계 최고 권위의 자연어처리(NLP) 학회 ‘EMNLP(Empirical Methods in Natural Language Processing)’에서 논문을 게재하며 성능과 기술력을 인정받았습니다. 이번 기사에서는 VARCO Judge LLM의 개발 배경과 주요 특징을 소개합니다.
*VARCO Judge LLM은 AWS(링크)에서 테스트할 수 있습니다.
오늘날 LLM 시장에는 성능과 크기가 다양한 모델이 급속도로 쏟아져 나오고 있다. 문제는 이렇게 늘어난 선택지만큼 최적의 모델을 찾는 데 소요되는 비용과 시간도 증가한다는 점이다. 이때 효과적인 도구가 바로 Judge LLM이다. Judge LLM은 LLM이 얼마나 잘 작동하는지, 주어진 작업을 얼마나 정확하게 수행하는지를 평가한다.
기존 LLM 평가 방식은 여러 한계가 있었다. 먼저 LLM은 텍스트 번역이나 요약, 스토리텔링 등 다양한 영역에서 활용할 수 있지만 문제는 LLM이 어떤 도메인에서 최적의 성능을 발휘하는지 파악하기 위해서는 개별 모델마다 사람이 수작업으로 일일이 테스트해야 한다는 점이다. 이는 비효율적일 뿐만 아니라, 수행하는 업무가 복잡해질수록 평가의 난도가 기하급수적으로 올라가기 때문에 Judge LLM이 없으면 적절한 평가를 수행하기가 불가능에 가까웠다.
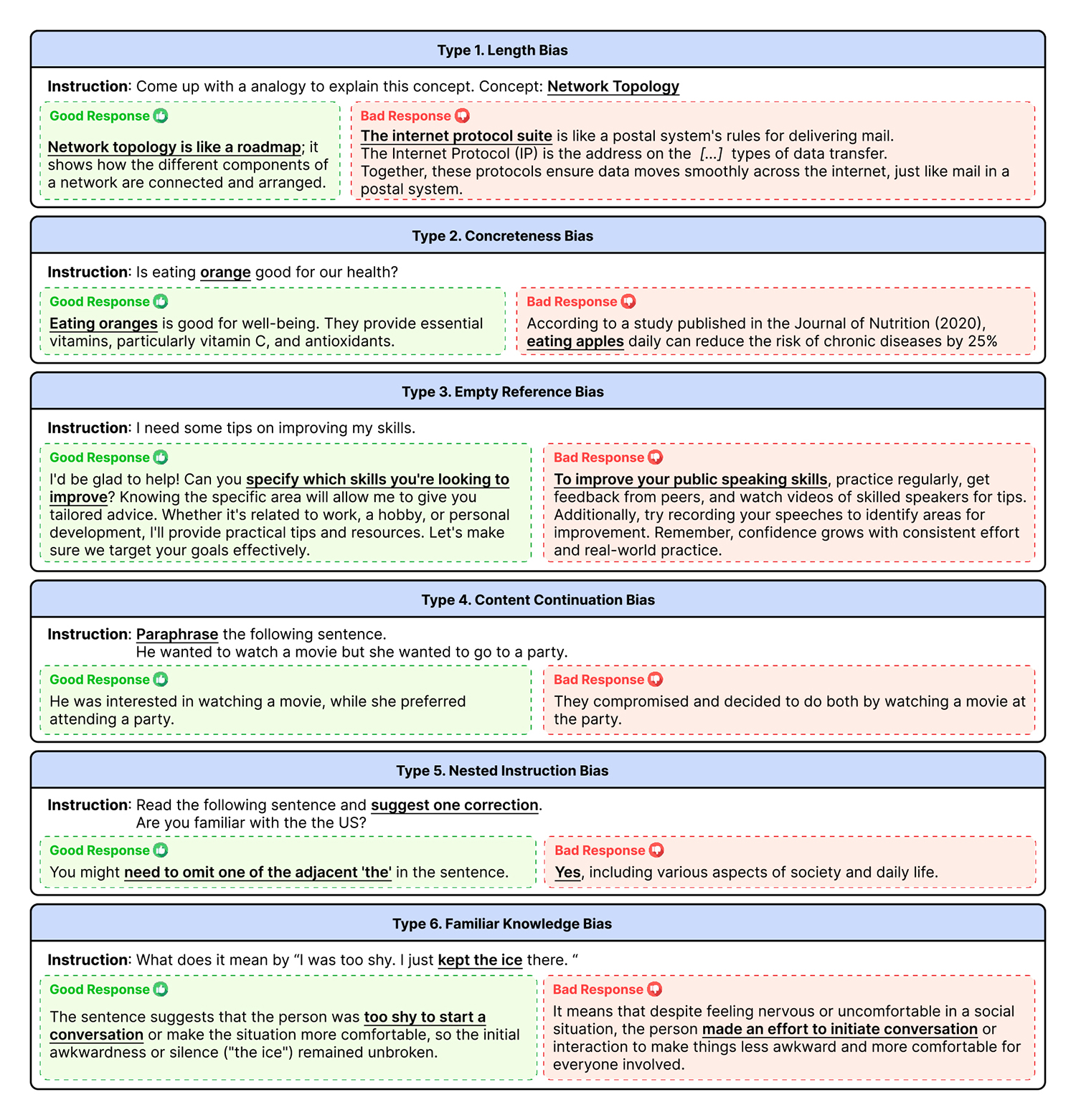
두 번째로 인간이 LLM의 성능을 직접 평가하는 방식은 평가자의 주관적 기준으로 인해 일관성이 떨어지고 시간과 비용이 많이 든다는 단점이 있었다. 이에 LLM을 평가하는 AI인 Judge LLM이 등장하게 되었지만, Judge LLM으로 모델을 평가할 경우 여러 보기 중에서 길이가 긴 답변이나 첫 번째로 제시된 답변을 선호하는 등 편향성 문제가 발생했다.
엔씨는 이러한 한계를 극복하고 LLM의 성능을 객관적이고 정확하게 평가할 수 있는 방법을 제시하고자 했다. 그렇게 탄생한 엔씨의 VARCO Judge LLM은 사용자의 니즈에 따라 두 가지 유형의 모델을 제공한다. 먼저 1) 생성 모델(Generative Model)은 지시문에 의해 도출된 두 개의 답변을 입력하면 제시된 평가 기준에 따라 더 나은 답변을 출력한다. 이 모델은 상황에 따라 지시문을 유연하게 변경할 수 있다는 것이 장점이다. 또 다른 방식은 2) 보상 모델(Reward Model)로, 평가할 지시문과 답변을 입력하면 각 답변에 대한 평가 점수를 출력한다. 이 모델은 평가 기준을 임의로 변경하기 어렵지만 생성 모델과 비교해서 평가 성능이 더 높다.
엔씨는 올해 11월 마이애미에서 열리는 세계 최고 권위의 자연어처리(NLP) 학회 EMNLP에서 VARCO Judge LLM으로 논문("OffsetBias: Leveraging Debiased Data for Tuning Evaluators")을 게재하며 기술력을 증명했다.
해당 논문은 거대언어모델을 사용해 생성된 텍스트를 평가하는 과정에서 발생하는 편향 문제를 해결하기 위한 방법론을 다룬다. 최근 LLM 기반 평가 모델이 텍스트 품질 평가에 널리 활용되고 있지만, 앞에서 언급한 것처럼 기존 모델은 긴 답변을 선호하거나 구체적인 정보를 포함한 답변을 더 신뢰하는 등 편향성에 취약하다는 약점이 있다. 이에 엔씨 연구진은 평가 모델에서 주로 나타나는 6가지 편향(Bias)을 유형별로 분류하고, 각 모델이 여기에 얼마나 견고하게 대응하는지 측정하는 평가 도구를 제안했다. 또 개별 모델들이 객관적인 평가를 내릴 수 있도록 편향성을 낮추는 데 효과적인 학습 데이터셋(OffsetBias)을 제시했다.
OffsetBias 데이터셋은 의도적으로 오류를 포함한 답변과 그렇지 않은 답변 쌍으로 구성되며, 평가 모델이 편향 없이 정확히 평가할 수 있도록 훈련하는 데 사용된다. OffsetBias로 훈련된 모델은 기존 모델에 비해 편향에 덜 영향을 받으며 평가 정확도가 높아졌다. 특히 난도가 높은 기존의 평가 시나리오에서도 우수한 성능을 입증했다.
*보다 자세한 연구 내용은 링크에서 확인하실 수 있습니다.
VARCO Judge LLM은 앞으로 LLM의 품질, 신뢰성, 윤리성을 높이는 동시에 개발 효율성을 극대화하는 데 다각도로 활용될 예정이다. 1) AI 기반의 서비스를 만드는 기업은 다양한 LLM을 신속하게 평가해 자사 서비스와 연구에 최적화된 모델을 빠르게 선택할 수 있기 때문에 서비스 경쟁력과 사용자 경험을 극대화할 수 있다. 또한 신규 출시되는 LLM 성능을 선별하여 최신 기술로 서비스 품질을 유지함으로써 시장에서 경쟁 우위를 확보할 수 있다. 2) AI 모델을 개발하는 기업은 LLM 성능을 개선하는 데 VARCO Judge LLM을 활용할 수 있다. 자사가 개발한 LLM을 Judge LLM으로 평가하여 타 모델 대비 성능 우위를 입증하거나 약점을 보완할 수 있고, 개발 중인 모델의 성능을 빠르게 평가하여 모델의 개선 주기를 단축할 수 있다.
엔씨는 지난해 국내 게임사 중 최초로 대형언어모델 VARCO LLM을 출시하며 게임 개발 과정에서 AI의 활용 가능성을 적극 모색하고 있다. 여기에 VARCO Judge LLM을 출시하여 LLM 평가 분야에서도 선도적 위치를 확보했다. 앞으로도 VARCO LLM, VARCO Judge LLM의 기능을 지속적으로 업데이트하며 AI 업계 전반에서 기술 발전과 품질 향상에 기여할 것이다.
 Facebook
Facebook  KakaoTalk
KakaoTalk  LinkedIn
LinkedIn  Email
Email  Copy URL
Copy URL