AI 센터 산하 Vision AI Lab(출전 팀명 VARCO)이 과학기술정보통신부가 주최한 ‘인공지능 그랜드 챌린지’ 3차 대회에서 최종 우승했습니다. 이 대회는 2019년부터 2022년까지 ‘인공지능과 로보틱스를 활용한 복합 재난 상황의 다양한 임무 해결’을 목표로 진행되었는데요. 4년간의 대회 기간 동안 총 175팀, 935명이 참가해 단계별로 문제 해결 능력을 겨뤘습니다.
팀 VARCO는 2019년 1단계 대회, 2020년 2단계 대회, 2021년 3단계 대회, 2022년 4단계 대회까지 4년 연속으로 입상하며 AI 기술 활용 능력을 증명했습니다. 특히 4단계 결선 대회에 참가한 팀 중 3단계 연속으로 입상한 팀은 VARCO가 유일했는데요. 이번 기사에서는 결선 대회의 도전 과제인 '재난 상황에서의 드론 운영 미션' 해결 과정을 공개합니다. 이 과제를 어떻게 풀었는지 전하면서 우승까지의 여정을 따라가보겠습니다.
국내 최고 권위의 인공지능 챌린지 대회 도전
2019년 Vision AI Lab은 게임 개발 QA(Quality Assurance)를 위한 디지털 이미지 OCR(Optical Character Recognition, 광학 문자 인식) 기술을 연구하고 있었다. OCR 기술은 게임 화면에 노출되는 문자 정보를 인지하므로 결과물 검수, 번역 등에도 활용할 수 있다.
Vision AI Lab은 화려하고 복잡한 배경에서도 문자를 검출하는 기술, 폰트가 다양한 문자를 검출하고 인식하는 기술, 게임 용어를 정확히 인식하는 기술 등을 중점적으로 연구해왔다. 그리고 그동안 확보한 기술 경쟁력을 이번 ‘인공지능 그랜드 챌린지’ 대회에서 확인할 수 있었다.
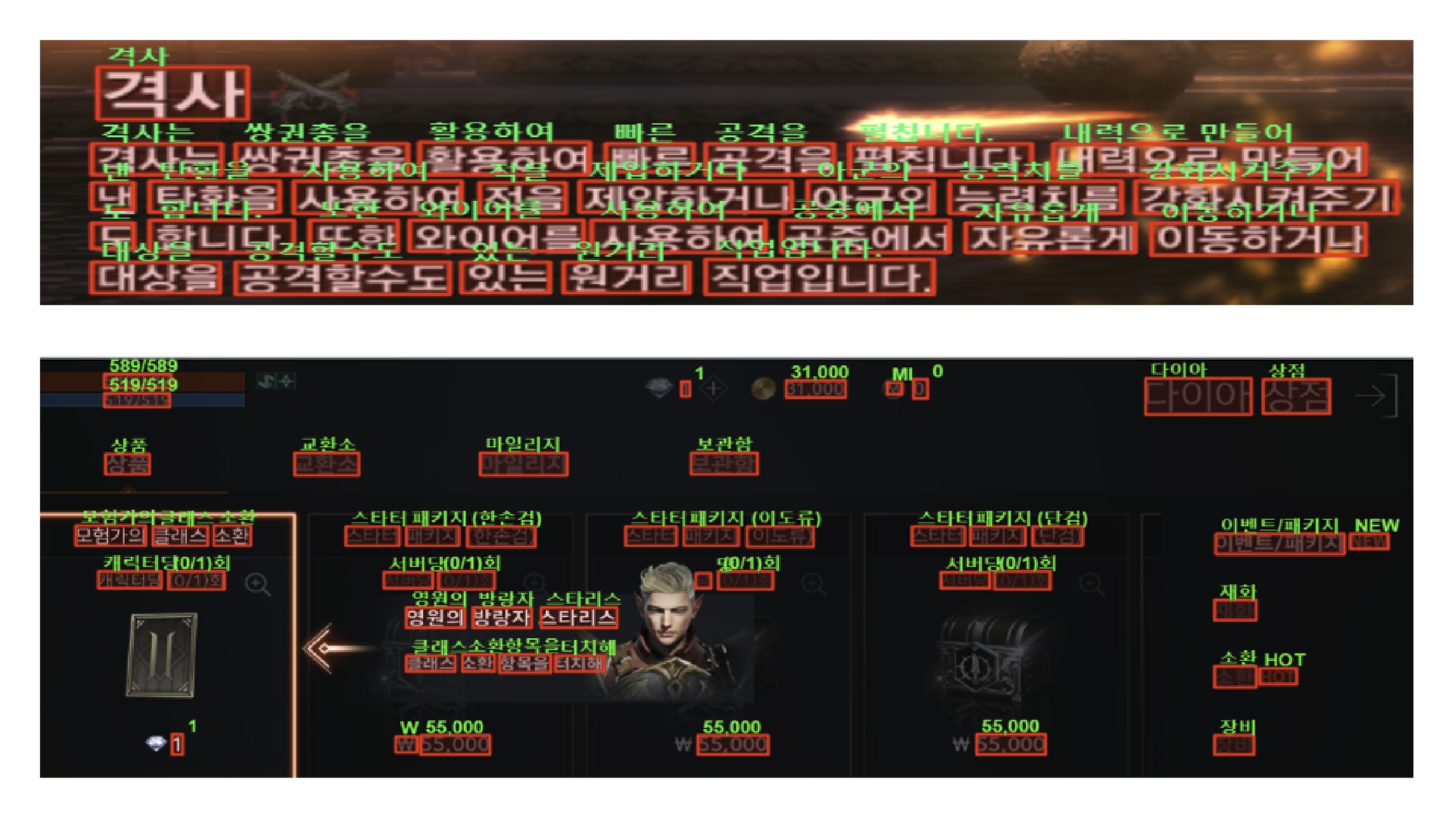
게임 화면에 노출되는 문자 정보를 인지하는 OCR 기술
인공지능 그랜드 챌린지 3차 대회가 추구한 목표는 ‘에지-클라우드 기반의 복합 재난 상황 대응 체계 시나리오’를 구축하는 것이었다. 재난 상황이 발생하면 현장에 출동한 드론(에지)을 통해 위험 상황 정보를 수집하고, 중앙재난안전상황실(클라우드)에서는 드론이 전송한 정보를 분석하여 대응 계획을 세우고 현장 구조대에 다시 전송하는 시나리오다.
2019년부터 시작된 인공지능 그랜드 챌린지 3차 대회의 1단계(2019), 2단계(2020) 대회는 상황 인지, 문자 인지, 청각 인지, 제어 지능 4개 트랙으로 나뉘어 진행되었다. 이후 3단계(2021) 대회부터 트랙이 구분되지 않는 복합 지능 문제를 푸는 방식으로 진행되었다. 3차 대회 결선 과제는 드론을 활용한 건물 내 영상·음성 정보 파악, 구조 요청자의 사진·신고 문자 수집 등 구조 요청자의 상황을 파악하기 위한 세 가지 미션이었다.
복합 재난 상황에 실시간으로 대응하는 드론-서버 플랫폼을 구축하기 위하여
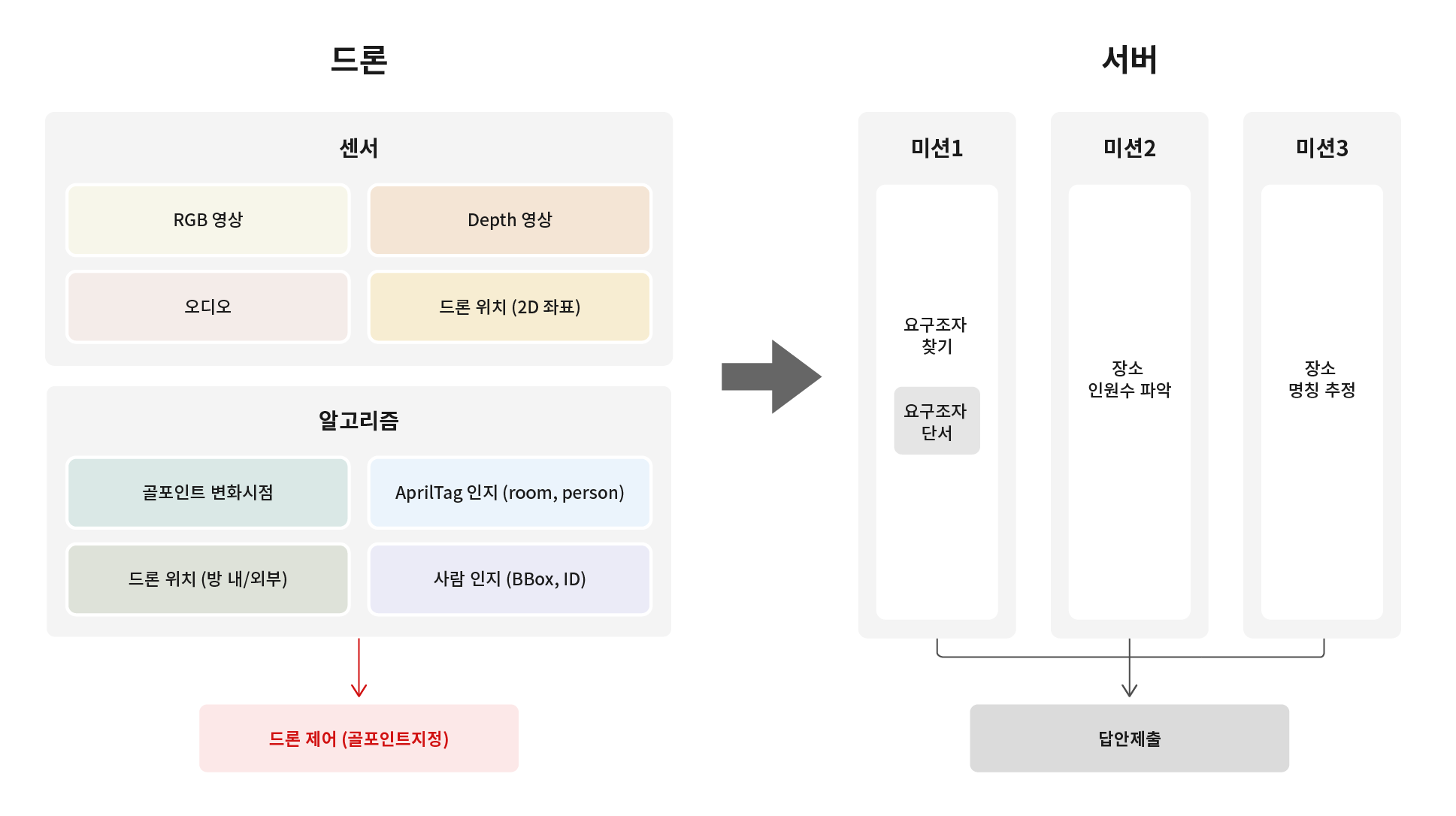
이번 3차 4단계 대회는, 주어진 데이터만 분석하여 미션을 해결하는 이전 대회와 달랐다. 도전 과제는 참가 팀이 직접 드론을 운용하며 건물 내 구조 요청자의 상황을 파악해야 하는 세 가지 미션이었다. 따라서 대회에 참여하려면 드론 플랫폼과 서버 플랫폼 모두 사용하는 파이프라인을 설계하고 구현해야 했다.
미션을 수행하기에 앞서 구현한 전체 파이프라인은 다음과 같다. 먼저 각 플랫폼의 입출력 데이터를 정의해야 한다. 드론 플랫폼은 드론의 센서를 통해 비행 중 RGB 영상, Depth 영상, 오디오, 드론 위치 좌표를 획득하고, 이를 기반으로 몇 가지 인지 결과를 추출하고 모든 데이터를 묶어 서버로 전송한다. 추출한 인지 결과는 드론이 어디로 이동해야 하는지 결정하는 데도 사용된다. 서버는 드론으로부터 입력받은 데이터를 각 미션 프로세스에 전달하고, 각 미션 프로세스는 답안을 만들어 채점 서버에 제출한다.
실시간으로 드론 비행을 제어해야 하는 팀 VARCO는 서버와 드론 플랫폼 간에 시간 지연이 발생하지 않도록 사람 인지와 AprilTag 인지 모델이 드론 플랫폼에서 동작할 수 있도록 구현했다. 또한 Neural Architecture Search 등의 모델 탐색 기술과 TensorRT 변환 및 Tensor Decomposition 등의 최적화/경량화 기술을 적용하여 드론 비행 중에도 여러 인지 결과를 실시간으로 추출하도록 구현했다.
첫 번째 미션: 요구조자 찾기
세 가지 미션 중 첫 번째는 요구조자를 찾는 미션이었다. 요구조자가 보낸 사진 또는 문자의 내용을 분석하여 어느 방에 있는 누구인지 찾아야 했다. 이를 단계별로 나누면 1) 사진 단서를 활용하기 위해 드론이 비행 중 관찰하는 공간과 사진 단서의 공간이 얼마나 유사한지, 2) 문자 단서를 활용하기 위해 드론이 비행 중 관찰하는 공간에 문자 단서에 포함된 내용이 얼마나 보이는지, 3) 동일한 공간 안에 있는 사람들 중 누가 구조 요청을 보낸 요구조자인지를 판단해야 한다.
팀 VARCO는 이미지 검색에 많이 활용되는 Image Retrieval 기술을 적용하여, 드론이 관찰하는 장면이 여러 요구조자가 보낸 사진 단서들 중 어느 장면과 가장 유사한지 판단함으로써 현재 장소에 누가 있는지 판단할 수 있도록 했다. 또한 Image Classification 기술을 사용하여, 드론이 관찰하는 장면에 어떤 사물이 있는지 판단하고, Person Detection 기술을 통해 일행이 몇 명인지 판단했다. 이 정보와 앞서 설명한 사진 단서의 정보를 복합하여 요구조자가 있는 공간을 특정했다.
마지막으로는 Text-based Person Retrieval 기술을 활용하여 문자 단서 안의 상하의 색상 정보를 문장으로 구성하고(예를 들어 ‘상의: 빨강, 하의: 검정’의 정형 데이터 - > ’빨간 상의와 검정 하의를 입은 여성’의 문장 데이터), 문장이 설명하는 인상착의와 가장 유사한 사람을 찾음으로써 요구조자를 특정했다.
두 번째 미션: 대회장 내 전체 인원수 파악하기
두 번째 미션은 각 방 안의 인원수를 파악하는 문제였다. 인원수는 성인 남성/성인 여성/아동 등 세 가지 클래스로 구분하여 추정해야 한다. 특히 이 미션은 다른 두 미션과 달리 영상 인지와 음성 인지 모두를 활용해야 했다. 예를 들어 영상으로 분석한 어느 방의 인원수가 성인 남성 2명이었는데 같은 방에서 성인 여성의 구조 요청 소리가 들린다면 이 여성은 보이지 않는 공간에 숨어 있거나 매몰되었다고 봐야 한다. 따라서 방의 인원수를 성인 남성 2명, 성인 여성 1명으로 제출해야 정답으로 인정받을 수 있다.
미션에서 영상에 기반하여 인원수를 추정하려면 두 가지 어려운 점을 해결해야 한다. 먼저 마네킹의 크기와 인상착의 등을 통해 성인 남성/성인 여성/아동을 구분해야 한다. 게다가 구조가 필요한 사람만을 인원수로 파악하고, 현장 구조대원, 의사 등은 포함하지 않아야 한다. 두 번째로, 요구조자를 탐색하기 위해 방 구석구석을 이동하는 드론이 동일인을 중복하여 카운트하지 않아야 한다. 즉, 드론 이동 과정에서 잠시 시야를 벗어난 마네킹이 다시 시야에 들어오면 기존에 본 사람이라고 판단해야 한다.
팀 VARCO는 첫 번째 문제에 Image Classification 기술을 통해 접근했다. 성인 남성/성인 여성/구조자 등의 이미지 DB를 수집하고, 이를 통해 학습한 모델이 검출된 사람의 클래스를 분류하도록 했다. 아동은 인상착의보다 마네킹의 크기 정보를 이용하여 따로 분류했다. 두 번째 문제에는 Person Re-Identification 기술을 사용했다. 여러 사람 이미지 중 동일인을 판별하는 기술이다. 또한 RGB 정보만 사용하는 일반적 영상 기반 Re-ID 기술과 달리 드론 센서를 통해 마네킹의 위치 정보까지 추가로 활용하며 Re-ID 성능을 높였다.
세 번째 미션: 모든 장소의 명칭 추정하기
세 번째 미션은 각 방의 입구에 부착된 명패의 문자를 인식하여 명칭을 추정하는 문제였다. 팀 VARCO는 다음과 같이 알고리즘을 설계했다. 먼저 입력 영상의 출입문과 명패를 검출할 수 있는 모델과 함께 문자 인식(OCR) 모델을 적용하여 출입문, 명패, 문자의 위치를 찾았다. 특히 문자의 경우 출입문 또는 명패와 가까이 있는 문자의 내용도 인식하도록 구현했다. 다음으로는 출입문을 검출한 정보와 드론의 위치 정보를 활용하여 2D 맵 상에서 출입문이 어디 있는지 판단했다. 또한 드론이 출입문을 통과하여 방에 진입하는 시점부터 반대쪽 출입문을 지나 나오는 시점 사이에, 인식하고 누적하여 융합한 문자 내용을 통해 장소 명칭을 추정했다.
아래 데모 비디오는 드론이 장소를 추정하는 과정을 보여준다. 방 안에 쓰여있는 문자 정보들을 인식 및 조합해서 현재 드론이 어떤 장소에 와 있는지 추정한다.
(추정된 장소 명칭은 화면 왼쪽 상단에 표시)
최종 결선 1위로 증명한 Vision AI 기술력
Vision AI Lab은 문자 인지와 관련하여 대회에 참여했지만, 각 단계가 진행되면서 상황 인지, 음향 인지, 드론 제어 등 복합 지능, 협업 지능을 활용하는 연구를 수행해야 했다. 연구 분야가 확장된 것은 물론이고 재난 환경에서 사용할 수 있는 인지 기술을 개발해야 했기 때문에 어려움이 많았다. 대회를 준비하면서도 두 가지 어려움을 겪었다. 첫 번째는 모든 미션을 실시간으로 처리해야 하고, 두 번째는 미션 수행에 필요한 모든 과정을 직접 만들어야 하는 것이었다.
이를 해결하기 위해 Vision AI Lab은 필요한 요소 기술들을 각 플랫폼에 적절히 배치했다. 재난 환경과 유사한 환경을 꾸미고 수많은 사전 테스트를 통해 문제를 파악하고 개선책을 모색하며 어려움을 극복해갔다. 대회 주최 측이 사전 테스트를 위해 제공한 공간 외에 추가로 공간을 대여해 대회 직전까지 테스트했다.
팀 VARCO는 1단계 2위, 2단계 2위, 3단계 2위로 모든 단계에 입상한 유일한 팀으로서 다년간 쌓은 노하우에 힘입어 최종 대회에서 1위를 수상하는 쾌거를 달성했다. 무엇보다 가장 큰 수확은 재난 상황이라는 극한 환경에서 강인한 성능을 발휘하는 Vision AI 기술을 확보한 것과, 드론이나 서버 장치 등을 직접 다루면서 플랫폼에 대한 이해도를 높인 것이다.
실시간으로 인터랙션하는 디지털 휴먼을 향해
엔씨는 이번 대회에서 획득한 사람-사물-문자 인지 기술을 향후 사람과 자연스럽게 인터랙션할 수 있는 대화형 디지털 휴먼 기술 개발에 활용할 예정이다. 문자의 위치를 찾기 위해 연구한 검출 모델은 사람 얼굴 또는 주변 사물을 검출하는 데 활용할 수 있고, 문자 내용을 인식하기 위해 연구한 시계열 모델은 제스처 인식 등에 활용할 수 있다.
또한 영상뿐 아니라 음성과 자연어를 융합한 멀티모달 인지 기술을 개발한 경험과 딥러닝 모델 경량화/최적화 노하우를 바탕으로 향후 자사 게임 서비스 및 콘텐츠 제작 효율화에 AI 기술을 활용할 예정이다. 이번 대회를 통해 축적한 Vision AI Lab의 인지 기술들은 상대방을 잘 관찰하고 공감해 줄 수 있는 실시간 대화형 디지털 휴먼을 개발하는 데 계속해서 활용될 것이다.
 Facebook
Facebook  KakaoTalk
KakaoTalk  LinkedIn
LinkedIn  Email
Email  Copy URL
Copy URL